

티스토리 뷰
Paper/TTS
[Paper 리뷰] DCTTS: Discrete Diffusion Model with Contrastive Learning for Text-to-Speech Generation
feVeRin 2024. 4. 19. 09:29반응형
DCTTS: Discrete Diffusion Model with Contrastive Learning for Text-to-Speech Generation
- Text-to-Speech에서 latent diffusion model을 우수한 성능을 보이고 있지만, resource consumption이 크고 추론 속도가 느림
- DCTTS
- Discrete diffusion model과 contrastive learning을 결합한 text-to-speech 모델
- 간단한 text encoder와 VQ model을 사용하여 raw data를 discrete space로 compress 한 다음, discrete space에서 diffusion model을 training 함
- 이때 diffusion step 수를 줄이기 위해 contrastive learning loss를 적용
- 논문 (ICASSP 2024) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 input text로부터 자연스러운 음성을 생성하는 것을 목표로 함
- 특히 Diffusion Probabilistic Model (DPM)은 powerful TTS backbone으로써 우수한 성능을 보이고 있음
- 이러한 DPM은 variational lower bound에 prior를 추가하여 음성과 text 간의 연결성을 implicit 하게 학습함
- BUT, diffusion model은 우수한 품질을 얻을 수 있지만, 여전히 느린 추론 속도의 한계가 있음 - Diffusion model의 느린 추론 속도 문제는 mel-spectrogram과 같은 high-dimensional raw speech feature와 과도한 diffusion step으로 인해 발생함
- 이를 근본적으로 해결하기 위해서는 data space를 일반적인 continuous latent가 아닌 discrete space로 compress 할 수 있어야 함
- 특히 Diffusion Probabilistic Model (DPM)은 powerful TTS backbone으로써 우수한 성능을 보이고 있음
-> 그래서 expensive prediction cost를 줄이고, 더 적은 diffusion step으로도 고품질의 음성을 합성할 수 있는 DCTTS를 제안
- DCTTS
- TTS 작업에서 discrete diffusion model과 contrastive learning을 결합
- Diffusion model의 data dimension을 compress 하고 computational efficiency를 향상 - Text와 음성의 alignment를 위해 discrete space에 대해 Text-wise Contrastive Learning Loss (TCLL)를 적용
- 더 적은 step으로 high-fidelity의 sample을 생성 - Parameter 수와 computation cost를 더욱 줄이기 위해 efficient text encoder를 도입
- TTS 작업에서 discrete diffusion model과 contrastive learning을 결합
< Overall of DCTTS >
- Discrete diffusion model과 contrastive learning을 결합한 text-to-speech 모델
- 간단한 text encoder와 VQ model을 사용하여 raw data를 discrete space로 compress 하고 contrastive learning loss를 적용함
- 결과적으로 기존 모델들보다 빠르고 고품질의 합성이 가능
2. Method
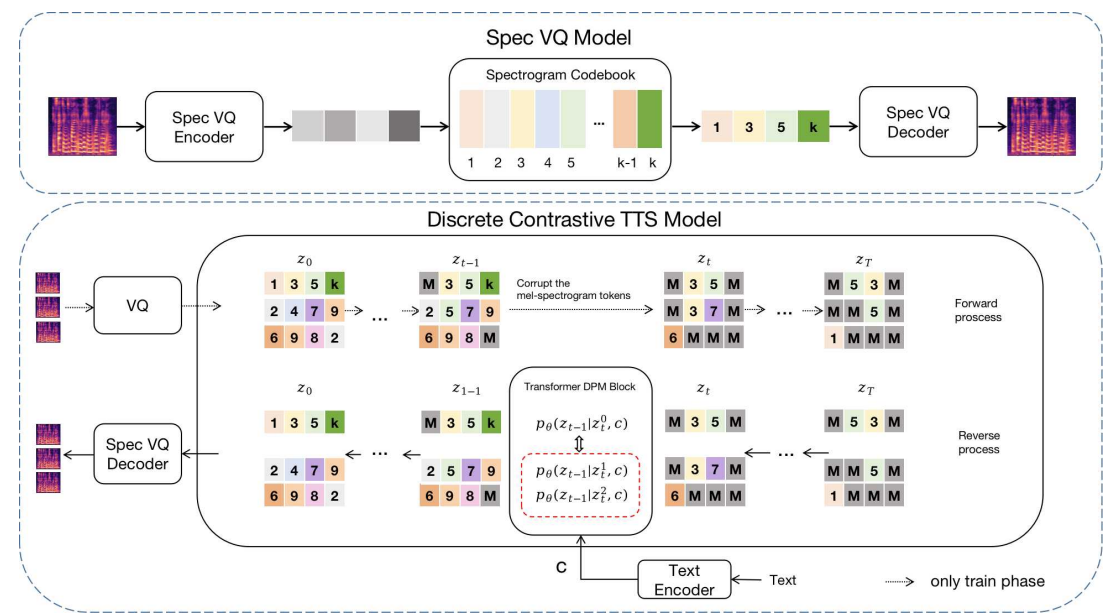
- DCTTS는 spectrogram VQ model, text encoder, discrete contrastive diffusion model의 3 부분으로 구성됨
- High-dimensional raw spectrogram을 discrete space로 compress 하기 위해 spectrogram VQ model을 pre-train 함
- 이후 text encoder는 input text에서 text feature를 추출함
- Conditional diffusion model은 text feature에 따라 discrete token sequence를 예측하는 데 사용되고, discrete token sequence는 spectrogram VQ decoder에 의해 mel-spectrogram으로 decoding 됨
- Spectrogram VQ Model
- Diffusion model의 computational cost를 줄이는 것은 data dimension을 줄이는 것으로 해결할 수 있음
- 따라서 DCTTS는 vector quantization을 위한 spectrogram VQ model을 도입해 raw spectrogram을 discrete space에 mapping 함
- 이때 spectrogram은 spectrogram token group으로 represent 될 수 있으므로 spectrogram 생성은 discrete token sequence 예측으로 transfer 됨
- 이를 통해 computation cost를 크게 줄일 수 있고, 이후의 diffusion model이 expensive 한 raw spectrogram 예측 대신 discrete space에서 동작하도록 함
- Spectrogram VQ model은 discrete codebook에서 retrieve 된 compressed intermediate representation을 사용하여 spectrogram input을 근사하도록 training 됨
- 구조적으로는 encoder $E_{vq}$, decoder $G$, codebook $Z=\{z_{k}\}_{k=1}^{K}\in \mathbb {R}^{K\times d}$로 구성
- $K$ : codebook size, $d$ : code dimension - Frequency dimension $F$, time dimension $L$을 가지는 spectrogram $s\in\mathbb{R}^{F\times L}$이 주어지면,
- 먼저 input $s$는 small-scale representation $z\in E_{vq}(s)\in\mathbb{R}^{f\times l \times d}$으로 encoding 됨
- $f\times l$ : reduced frequency, time dimension ($f\times l \ll F\times L$), $d$ : embedding dimension - 이후 $(f,l)$의 모든 $(i,j)$에 대해, 각 spatial feature $z_{ij}$를 가장 가까운 codebook entry $z_{k}$에 mapping 하는 spatial-wise quantizer $Q(.)$을 사용하여 spectrogram token의 spatial collection $z_{q}$를 얻음:
(Eq. 1) $z_{q}=Q(z):=\left(\arg \min_{z_{k}\in z}|| z_{ij}-z_{k}||_{2}^{2}\right)$ - 다음으로 해당 spectrogram은 decoder를 통해 $\hat{s}=G(z_{q})$와 같이 reconstruction 될 수 있음
- 여기서 smaller-scale representation에서 upsampling 할 때 reconstruction 품질을 유지하기 위해 추가적인 discriminator를 사용하는 VQGAN을 활용
- 먼저 input $s$는 small-scale representation $z\in E_{vq}(s)\in\mathbb{R}^{f\times l \times d}$으로 encoding 됨
- 따라서 DCTTS는 vector quantization을 위한 spectrogram VQ model을 도입해 raw spectrogram을 discrete space에 mapping 함
- Text Encoder
- Text encoder는 input text에서 text representation을 추출하는 것을 목표로 함
- 기존에는 CLIP이나 BERT 같은 large pre-trained model을 사용하므로 parameter 수가 증가하고 expensive 함
- 따라서 cost를 줄이기 위해서는 보다 효율적인 text encoder 구성이 필요함
- 특히 최근의 EfficientSpeech는 FastSpeech2를 기반으로 하여 효율적이고 고품질의 합성 성능을 제시했음 - 따라서 DCTTS는 EfficientSpeech의 architecture를 활용하여 phoneme encoder와 acoustic feature extractor로 구성된 efficient text encoder를 도입함
- 먼저 phoneme encoder는 g2p를 통해 얻은 input phoneme에서 content feature를 추출함
- Acoustic feature extractor는 content feature로부터 energy $y_{e}$, pitch $y_{p}$, duration $y_{d}$를 예측함
- 이때 acoustic feature를 series로 예측하는 대신 parallel 하게 생성하여 빠른 추론 속도를 달성 - 이후 content, acoustic feature는 text feature와 concatenate 되어 diffusion model의 input으로 사용됨
- 기존에는 CLIP이나 BERT 같은 large pre-trained model을 사용하므로 parameter 수가 증가하고 expensive 함
- Discrete Diffusion Model with Contrastive Learning
- Data dimension은 VQ model을 사용하여 compress 되므로, text feature에 따라 discrete token sequence를 예측하도록 diffsuion model을 training 하여 추론을 수행할 수 있음
- 여기서 diffusion model의 training은 forward/reverse process로 구성됨
- 먼저 text-spectrogram pair가 주어지면 pre-trained spectrogram VQ model을 사용하여 discrete spectrogram token sequence $z\in \mathbb{Z}^{N}$를 얻음
- $N=f\times l$ : token sequence length
- 이때 codebook size가 $K$라고 하면 location $i$의 spectrogram token $z_{i}$는 codebook의 entry를 지정하는 index를 specify 함 (즉, $z_{i}\in\{1,2,...,k\}$) - Forward phase에서는 Mask-and-Replace diffusion strategy를 사용하여 spectrogram token을 corrupt 함
- 이때 diffusion strategy는 Markov chain을 따르면서, 각 token은 $[MASK]$ token에 의해 masking 될 확률 $\gamma_{t}$를 가지고 모든 $K$ category에 대해 uniformly resample 될 확률 $K\beta_{t}$를 가짐
- 이때 $\alpha_{t}=1-k\beta_{t}-\gamma_{t}$의 확률은 변경되지 않고 $[MASK]$ token은 fix 된 상태로 유지됨 - Reverse phase에서 transformer DPM block은 condition input을 기반으로 corrupted token sequence를 예측하고 recover 하도록 training 됨
- Condition $c$를 text encoder의 text feature라고 하면, 전체 TTS framework는 conditional transition distribution $q(x|c)$를 최대화하는 것으로 볼 수 있음
- 여기서 network $p_{\theta}(x_{t-1}|x_{t},y)$는 posterior transition distribution $q_{\theta}(x_{t-1}|x_{t},x_{0})$을 추정하도록 training 되고, 해당 network는 variational lower bound를 최소화하는 것으로 최적화됨
- 먼저 text-spectrogram pair가 주어지면 pre-trained spectrogram VQ model을 사용하여 discrete spectrogram token sequence $z\in \mathbb{Z}^{N}$를 얻음
- TTS에서는 text와 음성 간의 correspondence가 매우 중요하고, 합성 품질과 직접적으로 관련되어 있음
- Text와 음성이 misalign 되어 있으면 reapeating, dragging과 같은 mispronunciation 문제가 발생함
- 따라서 DCTTS의 text feature 역시 discrete spectrogram token과 good correspondence를 유지해야 함 - 이러한 alignment connection을 향상하기 위해 DCTTS는 contrastive learning을 도입함
- 여기서 $I(z_{0};c)=\sum_{z_{0}}p_{\theta}(z_{0},c)\log \frac{p_{\theta}(z_{0}|c)}{p_{\theta}(z_{0})}$로 정의된 mutual information을 최대화하여 $c$와 생성된 data $z_{0}$ 간의 connection을 향상하는 것을 목표로 함
- $N$개의 negative sample $X'=\{x_{1},x_{2},...,x_{N}\}$에서 quantify된 spectrogram sequence $Z'=\{z_{1},z_{2},...,z_{N}\}$이 있다고 하자
- 그러면 similar text는 similar spectrogram token을 가져야하고, contrastive learning의 degree를 control하기 위해 $f(z_{0},c)$를 정의하여 text feature의 similarity를 계산할 수 있음
- 결과적으로 DCTTS에 적용되는 Text-wise Contrastive Learning Loss (TCLL)은:
(Eq. 2) $L_{TCLL}:=-\mathbb{E}\left[\log \frac{f(z_{0},c)}{f(z_{0},c)+\sum_{z_{j}\in Z'}\{f(z_{j},c)(1-\mathrm{sim}(c,c_{j})) \}}\right]$
- $\mathrm{sim}(c,c_{j})$ : $c, c_{j}$ 간의 Cosine similarity
- 결과적으로 위 TCLL을 최적화함으로써 $I(z_{0};c)$를 최대화할 수 있고, 논문에서는 step-wise parallel diffusion을 기반으로 diffusion model에 TCLL을 추가함
- 여기서 diffusion model의 training은 forward/reverse process로 구성됨
3. Experiments
- Settings
- Dataset : LJSpeech
- Comparisons : FastSpeech2, Grad-TTS, Tacotron2
- Results
- MOS 측면에서 합성 품질을 비교해 보면, DCTTS가 가장 우수한 것으로 나타남
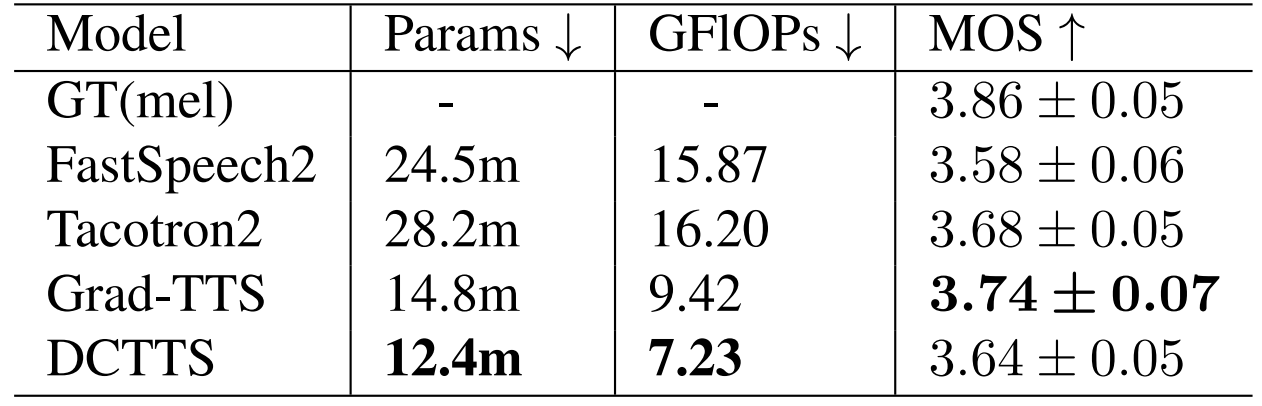
- DCTTS는 효율성 측면에서도 다른 모델들보다 더 적은 parameter와 GFLOP을 보임
- 결과적으로 DCTTS는 GPU에서 73.9 mRTF와 CPU에서 17.6 mRTF를 달성함

- 한편으로 Text-aware Contrastive Learning Loss (TCLL)이 제거되는 경우, DCTTS의 성능은 저하되는 것으로 나타남

반응형
'Paper > TTS' 카테고리의 다른 글
댓글