

 [Algorithm] 유니온 파인드, 서로소 집합
[Algorithm] 유니온 파인드, 서로소 집합
* Python을 기준으로 합니다 유니온 파인드 (Union Find), 서로소 집합 (Disjoint Set) - 개념 집합 : 순서와 중복이 없는 원소들을 가지는 자료구조 유니온 파인드 (=서로소 집합) : 교집합이 없는 두 집합 관계를 의미 해당하는 원소가 그래프에 연결되어 있는지를 판별하기 위한 자료구조로써, 일반적으로 트리를 통해 구현함 노드의 개수가 $V$이고 $V-1$개의 union 연산과 $M$개의 find 연산이 가능할 때, 유니온 파인드의 time complexity는 $O(V+M(1+\log_{2-M/V}V))$ 유니온 파인드의 연산 Find : 특정 노드의 root를 확인하는 연산 (노드가 같은 트리에 연결되어 있는지를 판별) 현재 노드의 parent를 찾는다 Parent가 root..
 [Paper 리뷰] Textually Pretrained Speech Language Models
[Paper 리뷰] Textually Pretrained Speech Language Models
Textually Pretrained Speech Language Models Speech language model은 textual supervision 없이 acoustic data 만을 처리하고 생성함 Textually Warm Initialized Speech Transformer (TWIST) Pretrained textual languaga model의 warm-start를 사용하여 speech language model을 training Parameter 수와 training data 측면에서 가장 큰 speech language model을 제시 논문 (NeurIPS 2023) : Paper Link 1. Introduction 음성에는 단순한 textual context 이상의 정보가 포..
 [Algorithm] 우선순위 큐
[Algorithm] 우선순위 큐
* Python을 기준으로 합니다 우선순위 큐 (Priority Queue) - 개념 우선순위 큐 : 우선순위가 높은 데이터를 가장 먼저 삭제하는 큐 즉, 우선순위 큐는 데이터를 우선순위에 맞게 정렬하고 순서대로 추출할 수 있어야 함 이때 배열이나 연결 리스트를 사용한 구현은, 우선순위에 따른 삽입과 삭제에 많은 비용이 소모됨 따라서 우선순위 큐는 힙 자료구조를 사용하여 삽입과 삭제를 $O(\log n)$ 내에 처리하도록 함 우선순위 큐에서 최소힙을 적용하면 값이 작을수록 높은 우선순위를 부여하도록 할 수 있음 반대로 최대힙을 적용하면 값이 클수록 우선순위를 부여함 - 힙은 일반적으로 최소힙으로 구현되므로, 삽입 시 음수를 취하고 추출 시 다시 -1을 곱하는 방식으로 처리 - 구현 1. heapq 라이브..
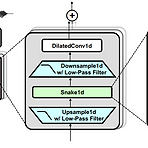 [Paper 리뷰] BigVGAN: A Universal Neural Vocoder with Large-Scale Training
[Paper 리뷰] BigVGAN: A Universal Neural Vocoder with Large-Scale Training
BigVGAN: A Universal Neural Vocoder with Large-Scale TrainingGenerative Adversarial Network (GAN) 기반의 vocoder는 우수한 품질을 보이고 있지만, 다양한 recording 환경과 speaker에 대한 audio를 합성하는 것에는 어려움이 있음BigVGANFine-tuning 없이 다양한 out-of-distribution scenario에 generalize 할 수 있는 universal vocoderGAN generator에 periodic activation function과 anti-aliased representation을 도입하여 inductive bias를 제공하고 합성 성능을 향상결과적으로 over-regula..
 [Algorithm] 힙
[Algorithm] 힙
* Python을 기준으로 합니다 힙 (Heap) - 개념 힙 : 특정 조건을 만족하면서 항상 완전 이진 트리 형태를 가지는 자료구조 힙의 조건 최대힙 : parent 노드가 항상 child 노드 보다 크거나 같다는 조건을 만족하는 힙 최소힙 : parent 노드가 항상 child 노드 보다 작거나 같다는 조건을 만족하는 힙 - 해당 힙 구조를 기반으로 최대/최소값 탐색을 $O(1)$ 내에 처리 가능 이때 힙은 단순히 위의 조건들만을 만족할 뿐, 정렬된 상태는 아님 - 구조적으로는 이진 탐색 트리와 유사하기 때문에 대부분의 연산은 $O(\log n)$ 내에 끝남 - BUT, 힙은 상/하 관계를 보장하고 이진 탐색 트리는 좌/우 관계를 보장한다는 차이가 있음 사용 예시 : 우선순위 큐, 힙 정렬, 다익스트..
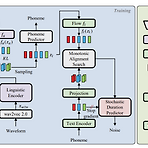 [Paper 리뷰] HierSpeech: Bridging the Gap between Text and Speech by Hierarchical Variational Inference using Self-Supervised Representations for Speech Synthesis
[Paper 리뷰] HierSpeech: Bridging the Gap between Text and Speech by Hierarchical Variational Inference using Self-Supervised Representations for Speech Synthesis
HierSpeech: Bridging the Gap between Text and Speech by Hierarchical Variational Inference using Self-Supervised Representations for Speech Synthesis Text로부터 raw waveform을 직접 생성하는 end-to-end pipeline은 고품질의 합성이 가능하지만, mispronunciation이나 over-smoothing 문제가 종종 발생함 HierSpeech 고품질의 end-to-end text-to-speech를 위해 self-supervised speech representation을 활용하는 hierarchical variational autoencoder 구조 Self-s..