

 [Paper 리뷰] DenoiSpeech: Denoising Text to Speech with Frame-level Noise Modeling
[Paper 리뷰] DenoiSpeech: Denoising Text to Speech with Frame-level Noise Modeling
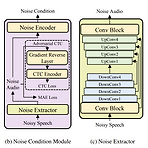
DenoiSpeech: Denoising Text to Speech with Frame-level Noise ModelingText-to-Speech 모델을 학습하기 위해서는 고품질의 speech data가 필요하지만, 대부분 noisy speech를 포함하고 있음DenoiSpeechNoisy speech data를 사용하여 clean speech를 합성할 수 있는 Text-to-Speech 모델모델과 jointly train 되는 noise condition module을 사용하여 fine-grained frame-level noise를 모델링하여 real-world noisy speech를 처리함논문 (ICASSP 2021) : Paper Link1. IntroductionText-to-Speech ..
 [Paper 리뷰] SRCodec: Split-Residual Vector Quantization for Neural Speech Codec
[Paper 리뷰] SRCodec: Split-Residual Vector Quantization for Neural Speech Codec
SRCodec: Split-Residual Vector Quantization for Neural Speech CodecEnd-to-End neural speech coding은 residual vector quantization을 통해 수행될 수 있지만, 가능한 적은 bit로 latent variable을 quantize 하는 것은 어려움SRCodecLatent representation을 동일한 dimension을 가지는 두 part로 split 하는 split-residual vector quantization을 채택한 fully convolutional encoder-decoder network- Low-dimensional feature와 high-dimensional feature 간의 res..
 [Paper 리뷰] VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech with Adversarial Learning and Architecture Design
[Paper 리뷰] VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech with Adversarial Learning and Architecture Design
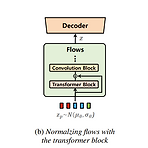
VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech with Adversarial Learning and Architecture DesignSingle-stage text-to-speech model은 기존의 two-stage 방식보다 더 우수한 합성 품질을 보이고 있지만, phoneme conversion에 대한 dependency와 computational efficiency 측면에서 개선이 필요함VITS2기존의 VITS structure를 개선하여 보다 natural 한 음성 합성과 multi-speaker에서 더 나은 speaker similarity를 지원Fully end-to-end single-stage approac..
 [Algorithm] 문자열 검색 - KMP 알고리즘
[Algorithm] 문자열 검색 - KMP 알고리즘
* Python을 기준으로 합니다문자열 검색 - KMP 알고리즘 (Knuth-Morris-Pratt Algorithm)- 개념KMP (Knuth-Morris-Pratt) 알고리즘 : 불일치가 감지되기 이전까지의 문자열은 다시 비교할 필요가 없다는 점을 활용함이를 통해 $O(NM)$의 time complexity를 가지는 Naive approach에 비해 KMP 알고리즘은 $O(N+M)$의 time complexity로 줄일 수 있음KMP를 위한 문자열 전처리 : 불일치가 발생했을 때 건너뛸 문자 수를 결정하기 위함먼저 건너뛸 문자 수를 결정하기 위해, 패턴 크기 `M`과 동일한 크기의 배열 `lps[]`를 선언함- `lps[]`는 길이가 최대인 접두사(prefix)-접미사(suffix) 배열을 의미이후 ..
 [Paper 리뷰] SANE-TTS: Stable and Natural End-to-End Multilingual Text-to-Speech
[Paper 리뷰] SANE-TTS: Stable and Natural End-to-End Multilingual Text-to-Speech
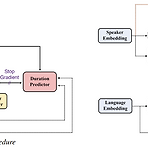
SANE-TTS: Stable and Natural End-to-End Multilingual Text-to-SpeechStable 하고 natural 한 end-to-end multilingual text-to-speech 모델이 필요함SANE-TTSMultilingual synthesis의 naturalness를 향상하기 위해 domain adversarial training을 도입추가적으로 speaker regularization loss를 적용하여 duration predictor의 speaker embedding을 zero-vector로 대체해 cross-lingual synthesis를 stablize 함논문 (INTERSPEECH 2021) : Paper Link1. IntroductionM..
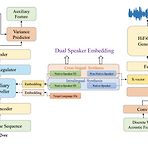 [Paper 리뷰] DSE-TTS: Dual Speaker Embedding for Cross-Lingual Text-to-Speech
[Paper 리뷰] DSE-TTS: Dual Speaker Embedding for Cross-Lingual Text-to-Speech
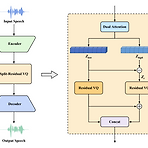
DSE-TTS: Dual Speaker Embedding for Cross-Lingual Text-to-SpeechCross-lingual text-to-speech는 speaker timbre를 정확하게 retain 하면서 nativeness를 반영하는 것이 어려움DSE-TTSMel-spectrogram 보다 더 적은 speaker information을 포함하는 vector-quantized acoustic feature를 활용해당 acoustic feature를 기반으로 speaking style을 반영하는 Dual Speaker Embedding을 도입- 한 embedding은 linguistic speaking stlye을 학습하기 위해 acoustic model에 전달되고,- 다른 embedd..