
티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] SRCodec: Split-Residual Vector Quantization for Neural Speech Codec
feVeRin 2024. 6. 6. 10:27반응형
SRCodec: Split-Residual Vector Quantization for Neural Speech Codec
- End-to-End neural speech coding은 residual vector quantization을 통해 수행될 수 있지만, 가능한 적은 bit로 latent variable을 quantize 하는 것은 어려움
- SRCodec
- Latent representation을 동일한 dimension을 가지는 두 part로 split 하는 split-residual vector quantization을 채택한 fully convolutional encoder-decoder network
- Low-dimensional feature와 high-dimensional feature 간의 residual을 quantize 하기 위함 - 두 dimension에 대한 information sharing을 향상하기 위해 split-residual vector quantization에 dual attention module을 적용
- Latent representation을 동일한 dimension을 가지는 두 part로 split 하는 split-residual vector quantization을 채택한 fully convolutional encoder-decoder network
- 논문 (ICASSP 2024) : Paper Link
1. Introduction
- Neural codec은 크게 generative model을 사용하는 방법과 end-to-end framework를 사용하는 방법으로 나눌 수 있음
- 특히 end-to-end neural codec은 VQ-VAE framework를 기반으로 compression과 reconstruction process를 통합함
- 여기서 input signal은 latent representation으로 변환된 다음, bitstream으로 quantize 됨 - 따라서 end-to-end neural codec에서는 quantizer의 역할이 핵심적임
- 일반적으로 quantizer는 latent representation의 전체 set를 single entity로 처리하여 quantization error를 최소화할 수 있음
- BUT, representation에 대한 transparent quantization을 달성하기 위해서는, high feature dimension을 처리할 수 있는 더 많은 bit 수가 필요하므로 codebook size와 computation이 증가함
- 한편으로 split-vector quantization (SVQ)는 linear predictive coding (LPC) parameter를 quantize 하기 위해 사용됨
- 이때 LPC parameter vector는 2개 이상의 part로 split 되고 각 part는 independent 하게 quantize 됨
- 이는 1 bit/frame을 saving 하는 동안 residual vector quantization (RVQ)를 수행하는 것과 같음 - 해당 SVQ는 neural codec에서 유용하게 사용될 수 있지만, single vector를 multiple vector로 split 되어 개별적인 index로 indendent 하게 quantize 되기 때문에 structured information missing과 distortion이 발생할 수 있음
- 특히 end-to-end neural codec은 VQ-VAE framework를 기반으로 compression과 reconstruction process를 통합함
-> 그래서 SVQ에서 개선된 Split-Residual Vector Quantization을 적용한 neural codec인 SRCodec을 제안
- SRCodec
- Split-residual vector quantization을 적용하기 위해 latent representation을 동일한 dimension을 가지는 2개의 part로 divide 함
- Low-dimensional feature는 RVQ를 통해 quantize 되고,
- Low-dimension과 high-dimension feature 사이의 residual은 또 다른 RVQ를 통해 quantize 됨 - 추가적으로 reconsturct 된 음성 품질을 향상하기 위해, dimension에 따른 information sharing을 지원하는 dual attention module을 split-residual vector quantization에 적용
- Split-residual vector quantization을 적용하기 위해 latent representation을 동일한 dimension을 가지는 2개의 part로 divide 함
< Overall of SRCodec >
- RVQ와 SVQ의 장점만을 결합한 split-residual vector quantization을 neural codec에 도입
- 두 dimension 모두에서 information sharing을 향상하는 dual attention module을 활용
- 결과적으로 기존 codec보다 우수한 성능을 달성
2. Method
- SRCodec은 아래 그림과 같이 encoder, split-residual vector quantizer, decoder로 구성됨
- Encoder는 raw speech에서 low-rate feature를 추출하고,
- Continuous feature는 split-residual vector quantization에 의해 discrete representation으로 encode 됨
- 이때 dimension에 따라 information을 share 하기 위해 dual attention module이 사용됨 - 최종적으로 decoder의 discrete encoded feature로부터 input signal을 reconstruct 함

- Encoder and Decoder
- Encoder와 Decoder는 SoundStream을 기반으로 하여 causal 1D convolution을 통한 convolution operation에 의존함
- 결과적으로 SRCodec의 latency는 frame size에 의해 결정됨
- 먼저 encoder에서 input speech signal $x\in\mathbb{R}^{T\times 1}$은 embedding sequence $Z\in \mathbb{R}^{T_{z}\times N_{z}}$로 변환됨
- $T, T_{z}$는 각각 dimension $1$과 $N_{z}$를 가지는 speech signal과 embedding의 length - 이후 quantized representation은 decoder에서 speech signal을 reconstruct 하기 위해 사용됨
- 먼저 encoder에서 input speech signal $x\in\mathbb{R}^{T\times 1}$은 embedding sequence $Z\in \mathbb{R}^{T_{z}\times N_{z}}$로 변환됨
- 논문에서는 16kHz waveform을 input으로 하여, frame size가 20ms인 $N_{z}=256$-dimensional speech feature로 변환함
- 결과적으로 SRCodec의 latency는 frame size에 의해 결정됨
- Split-Residual Vector Quantization
- Vector quantizer는 latent input representation의 distortion을 최소화하면서 discrete representation으로 변환하는 것을 목표로 함
- 이를 위해 SoundStream에서는 cascade 방식으로 VQ의 $N_{q}$ layer를 활용하는 RVQ를 채택함
- 즉, residual quantizer $\mathcal{Q}:\mathbb{R}^{T_{z}\times N_{z}}\rightarrow \{0,...,2^{\lceil \log N_{c}\rceil}-1\}^{T_{z}\times N_{q}}$는 $N_{q}$ codebook에서 code index를 search 하여 input latent에 가장 가까운 codeword에 대한 cascade combination을 생성함
- $N_{c}$ : single quantizer의 codebook size, $N_{q}$ : quantizer 수 - 한편으로 SVQ는 vector를 multiple sub-vector로 divide 하고 각 sub-vector를 independent 하게 index로 quantize 함
- 이때 극단적인 경우, SVQ는 scalar quantizer와 동일해짐
- 즉, split part 간의 correlation을 ignoring 하여 성능 저하를 발생시킬 수 있음
- 이를 위해 SoundStream에서는 cascade 방식으로 VQ의 $N_{q}$ layer를 활용하는 RVQ를 채택함
- Split-Residual Vector Quantization
- 논문은 앞선 SVQ의 한계를 개선하기 위해 Split-Residual Vector Quantization을 도입함
- 즉, latent variable $Z$를 동일한 dimension을 가진 $Z_{\text{low}}, Z_{\text{high}}$의 두 part로 split 함
- 이후 $Z_{\text{low}}$와 $Z_{\text{low}}, Z_{\text{high}}$ 사이의 residual $Z_{r}$은 RVQ에 의해 개별적으로 quantize 됨
- SRCodec에서는 $Z_{\text{low}}$를 quantize 하기 위해 $N_{c}=210$의 codebook size를 사용하고, $Z_{r}$을 quantize하기 위해 $N_{c}=29$의 codebook size를 사용함
- 추가적으로 $N_{q}$는 0.95kpbs, 1.9kbps, 3.8kpbs에 해당하는 set $\{1,2,4\}$에서 값을 취하여 RVQ의 layer 수를 변경함
- 논문은 앞선 SVQ의 한계를 개선하기 위해 Split-Residual Vector Quantization을 도입함
- Dual Attention Module
- Latent representation split 이전에, 두 dimension의 information sharing을 향상하기 위해 dual attention module을 도입함
- 이때 dual attention module은 아래 그림과 같이, feature map $F$에서만 동작함
- 먼저 $F$는 residual block을 통해 transform 된 다음, channel/time attention module로 전달됨
- Channel attention module에서는 time dimension을 따라 global max pooling과 global average pooling을 적용함
- 이후 result를 concatenate 하여 feature map $F_{c}\in \mathbb{R}^{N_{z}\times 2}$를 얻고, channel attention feature map $W_{c}\in\mathbb{R}^{N_{z}\times 1}$을 추출하는데 사용함 - Time attention module에서는 SE block을 사용하여 feature map $W_{t}\in\mathbb{R}^{1\times T_{z}}$를 얻음
- 결과적으로 latent feature $F$는 $W_{c}, W_{t}$에 의해 rescale 되어 final latent representation을 생성함
- $\otimes$ : element-wise multiplication
- 이때 dual attention module은 아래 그림과 같이, feature map $F$에서만 동작함

- Adversarial Training
- SRCodec은 adversarial loss로 train 되는 VQ-VAE-based framework를 채택함
- 해당 adversarial training framework는 SoundStream의 waveform-domain discriminator와 STFT-domain discriminator를 포함하여 구성됨
- 즉, SRCodec은 standard adversarial loss, feature matching loss를 활용해 training 됨
- 추가적으로 $i \in \{\mathrm{low},\mathrm{high}\}$ residual quantizer에 대해 다음의 commitment loss를 적용:
(Eq. 1) $\mathcal{L}_{w}=\sum_{i,w}|| z_{i,w}-q_{i,w}(z_{i,w})||_{2}^{2}$
- $z_{w}$ : current residual, $q_{w}(z_{w})$ : codebook의 nearest entry - 결과적으로 generator loss는:
(Eq. 2) $\mathcal{L}_{G}=\lambda_{adv}\mathcal{L}_{adv}+\lambda_{feat}\mathcal{L}_{feat}+\lambda_{rec}\mathcal{L}_{rec}+\lambda_{w}\mathcal{L}_{w}$
- $\lambda_{adv}=1, \lambda_{feat}=100, \lambda_{rec}=1, \lambda_{w}=1$
- 추가적으로 $i \in \{\mathrm{low},\mathrm{high}\}$ residual quantizer에 대해 다음의 commitment loss를 적용:
3. Experiments
- Settings
- Dataset : VCTK
- Comparisons : Opus, Lyra, EnCodec
- Results
- MUSHRA test 측면에서 0.95kbps의 SRCodec은 3kbps의 Lyra-v1, EnCodec보다 뛰어난 성능을 보임

- 정량적 평가 측면에서도, SRCodec이 가장 뛰어난 것으로 나타남
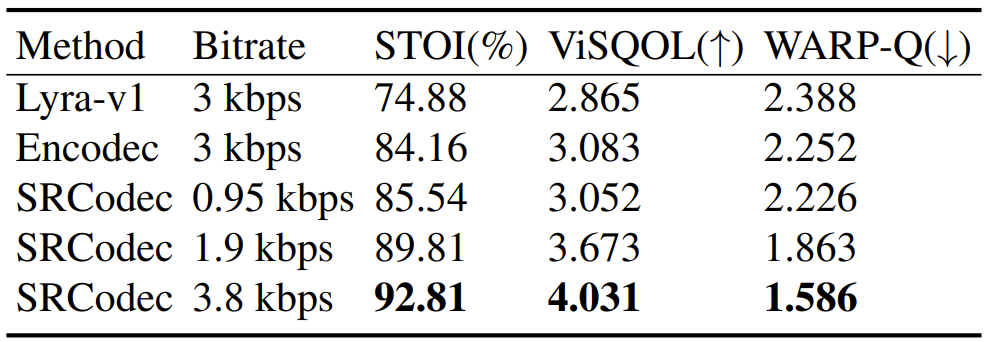
- Ablation study 측면에서 SRCodec의 각 component를 제거하는 경우 품질 저하가 발생함

- Computation time 측면에서도 SRCodec은 EnCodec 보다 뛰어남

반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글