

 [Paper 리뷰] VQVC: One-Shot Voice Conversion by Vector Quantization
[Paper 리뷰] VQVC: One-Shot Voice Conversion by Vector Quantization
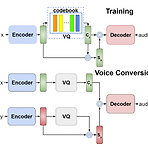
VQVC: One-Shot Voice Conversion by Vector QuantizationSpeaker label에 대한 supervision 없이 voice conversion을 수행할 수 있음VQVCContent embedding을 discrete code로 모델링하고 quantize-before/quantize-after vector 간의 차이를 speaker embedding으로 취급Vector quantization에 대한 reconstruction loss 만으로 content/speaker information에 대한 strong disentanglement를 달성논문 (ICASSP 2020) : Paper Link1. IntroductionVoice Conversion (VC)는 l..
 [Paper 리뷰] VQVC+: One-Shot Voice Conversion by Vector Quantization and U-Net Architecture
[Paper 리뷰] VQVC+: One-Shot Voice Conversion by Vector Quantization and U-Net Architecture
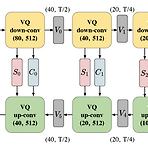
VQVC+: One-Shot Voice Conversion by Vector Quantization and U-Net ArchitectureAutoEncoder-based voice conversion은 speaker identity와 input speech content를 disentangle 하여 unseen speaker에 대해 generalize 됨- BUT, imperfect disentanglement로 인해 합성 품질의 한계가 있음VQVC+AutoEncoder-based system에 대해 U-Net architecture를 도입해 conversion 품질을 향상Strong information bottleneck을 위해 latent vector를 quantize 하는 vector quant..
 [Paper 리뷰] One-Shot Voice Conversion by Separating Speaker and Content Representations with Instance Normalization
[Paper 리뷰] One-Shot Voice Conversion by Separating Speaker and Content Representations with Instance Normalization
One-Shot Voice Conversion by Separating Speaker and Content Representations with Instance NormalizationSource, target speaker의 example utterance만으로 voice conversion을 수행할 수 있어야 함AdaIN-VCInstance Normalization을 도입해 speaker, content representation을 disentanlging 함Unseen speaker에 대해 one-shot voice conversion이 가능논문 (INTERSPEECH 2019) : Paper Link1. IntroductionVoice Conversion (VC)는 linguistic conten..
 [Paper 리뷰] AGAIN-VC: A One-Shot Voice Conversion Using Activation Guidance and Adaptive Instance Normalization
[Paper 리뷰] AGAIN-VC: A One-Shot Voice Conversion Using Activation Guidance and Adaptive Instance Normalization
AGAIN-VC: A One-Shot Voice Conversion Using Activation Guidance and Adaptive Instance NormalizationVoice Conversion은 일반적으로 disentangle-based learning을 사용하여 speaker와 linguistic content를 분리한 다음, speaker information을 target speaker로 변환하는 방식을 활용함AGAIN-VCActivation guidance와 Adaptive Instance Normalization을 도입해 speaker information의 유출을 방지Single encoder-decoder로 구성되어 합성 품질과 speaker similarity를 향상 논문 (..
 [Paper 리뷰] EmoQ-TTS: Emotion Intensity Quantization for Fine-Grained Controllable Emotional Text-to-Speech
[Paper 리뷰] EmoQ-TTS: Emotion Intensity Quantization for Fine-Grained Controllable Emotional Text-to-Speech
EmoQ-TTS: Emotion Intensity Quantization for Fine-Grained Controllable Emotional Text-to-SpeechEmotional text-to-speech를 위해 대부분은 emotion label이나 reference audio에 의존함- BUT, utterance-level emotion condition으로 인해 expression이 monotonous 하다는 한계가 있음EmoQ-TTSFine-grained emotion intensity와 phoneme-wise emotion information을 conditioning하여 expressive speech를 합성Emotion intensity는 human labeling 없이 distanc..
 [Paper 리뷰] QI-TTS: Question Intonation Control for Emotional Speech Synthesis
[Paper 리뷰] QI-TTS: Question Intonation Control for Emotional Speech Synthesis
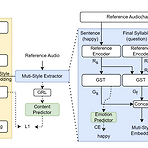
QI-TTS: Question Intonation Control for Emotional Speech SynthesisExpressive text-to-speech는 intonation과 같은 fine-grained style이 무시되는 경우가 많음QI-TTSReference speech의 emotion을 transfer 하면서 questioning intonation을 효과적으로 deliver 하기 위해 2가지의 서로 다른 level에서 style embedding을 추출하는 multi-style extractor를 활용Fine-grained intonation control을 위해 relative attribute를 통해 syllable level에서 intonation intensity를 repre..