

 [Paper 리뷰] PVAE-TTS: Adaptive Text-to-Speech via Progressive Style Adaptation
[Paper 리뷰] PVAE-TTS: Adaptive Text-to-Speech via Progressive Style Adaptation
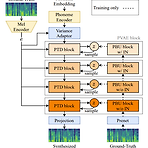
PVAE-TTS: Adaptive Text-to-Speech via Progressive Style AdaptationAdaptive text-to-speech는 limited data에서 speaking style을 학습하기 어렵기 때문에 새로운 speaker에 대한 합성 품질이 떨어짐PVAE-TTSStyle에 점진적으로 adapting 하면서 data를 생성하는 Progressive Variational AutoEncoder를 채택추가적으로 adaptiation 성능을 향상하기 위해 Dynamic Style Layer Normalization을 도입논문 (ICASSP 2022) : Paper Link1. IntroductionText-to-Speech (TTS) system을 training 하기 위..
 [Paper 리뷰] VISinger2: High-Fidelity End-to-End Singing Voice Synthesis Enhanced by Digital Signal Processing Synthesizer
[Paper 리뷰] VISinger2: High-Fidelity End-to-End Singing Voice Synthesis Enhanced by Digital Signal Processing Synthesizer
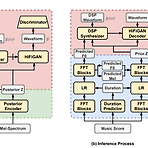
VISinger2: High-Fidelity End-to-End Singing Voice Synthesis Enhanced by Digital Signal Processing SynthesizerSinging Voice Synthesis에서 VISinger는 우수한 합성 성능을 달성했지만 다음의 한계점이 존재함- Text-to-Phase problem, Glitches, Low sampling rateVISinger2Digital signal processing synthesizer를 통해 VISinger의 latent representation $z$로부터 periodic/aperiodic signal을 생성- Phase information 없이 latent representation을 추출하도록 p..
 [Paper 리뷰] RefineGAN: Universally Generating Waveform Better than Ground Truth with Highly Accurate Pitch and Intensity Responses
[Paper 리뷰] RefineGAN: Universally Generating Waveform Better than Ground Truth with Highly Accurate Pitch and Intensity Responses
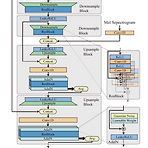
RefineGAN: Universally Generating Waveform Better than Ground Truth with Highly Accurate Pitch and Intensity ResponsesGenerative Adversarial Network-based waveform generation은 discriminator에 크게 의존함- 따라서 generation process에 uncertainty가 존재하고 pitch/intensity mismatch가 발생함RefineGANRobustness, pitch/intensity accuracy를 유지하기 위해 pitch-guided refine architecture를 구성추가적으로 training을 stabilize 하기 위해 multi..
 [Paper 리뷰] EmoSphere-TTS: Emotional Style and Intensity Modeling via Spherical Emotion Vector for Controllable Emotional Text-to-Speech
[Paper 리뷰] EmoSphere-TTS: Emotional Style and Intensity Modeling via Spherical Emotion Vector for Controllable Emotional Text-to-Speech
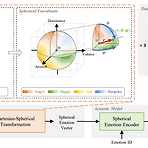
EmoSphere-TTS: Emotional Style and Intensity Modeling via Spherical Emotion Vector for Controllable Emotional Text-to-SpeechEmotional text-to-speech는 pre-defined label로 제한되므로 emotion의 변화를 효과적으로 반영하지 못함EmoSphere-TTSEmotional style, intensity를 control 하는 spherical emotion vector를 채택Human annotation 없이 arousal, valence, dominance pseudo-label을 사용하여 Cartesian-spherical transformation을 통해 emotion을 모델..
 [Paper 리뷰] Mega-TTS2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis
[Paper 리뷰] Mega-TTS2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis
Mega-TTS2: Boosting Prompting Mechanisms for Zero-Shot Speech SynthesisZero-shot text-to-speech에서 prompting mechanism은 다음의 문제를 가지고 있음- 대부분 single-sentence prompt로 training 되므로 추론 시 주어지는 data가 다양한 경우 성능이 제한됨- Prompt의 prosodic information은 timbre와 highly couple 되어 있고, 서로 untransferable 함Mega-TTS2고품질 reconstruction을 제공하면서 prosody, timbre information을 compressed latent space로 separately encode 하는 ac..
 [Paper 리뷰] VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild
[Paper 리뷰] VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild
VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the WildSpeech editing, zero-shot text-to-speech를 위해 token infilling neural codec language model을 구성할 수 있음VoiceCraftTransformer decoder architecture와 causal masking, delayed stacking을 결합하여 existing sequence 내에서 generation을 수행하는 token rearrangement를 도입추가적으로 speech editing evaluation을 위한 RealEdit dataset을 제공논문 (ACL 2024) : Paper Link1. Int..