

티스토리 뷰
Paper/TTS
[Paper 리뷰] DSE-TTS: Dual Speaker Embedding for Cross-Lingual Text-to-Speech
feVeRin 2024. 6. 3. 08:51반응형
DSE-TTS: Dual Speaker Embedding for Cross-Lingual Text-to-Speech
- Cross-lingual text-to-speech는 speaker timbre를 정확하게 retain 하면서 nativeness를 반영하는 것이 어려움
- DSE-TTS
- Mel-spectrogram 보다 더 적은 speaker information을 포함하는 vector-quantized acoustic feature를 활용
- 해당 acoustic feature를 기반으로 speaking style을 반영하는 Dual Speaker Embedding을 도입
- 한 embedding은 linguistic speaking style을 학습하기 위해 acoustic model에 전달되고,
- 다른 embedding은 speaker timbre를 mimic 하기 위해 vocoder에 결합됨
- 논문 (INTERSPEECH 2023) : Paper Link
1. Introduction
- Text-to-Speech (TTS) 모델들은 우수한 성능을 보이고 있지만, 여전히 multi-lingual TTS (MTTS) 환경에서는 speaker timbre를 정확하게 retain 하기 어려움
- 구체적으로, cross-language synthesis는 speaker similarity를 유지하면서 non-native language에서 기존 native language 수준의 nativeness를 달성하는 것을 목표로 함
- 특히 cross-lingual TTS의 성능 저하는 language간 entanglement로 인해 발생하므로, 이를 해결하기 위해 adversarial domain training, mutual information minimization, speaker classifier 등을 도입함
- 한편으로 SANE-TTS와 같이 VITS를 기반으로 한 end-to-end 모델을 활용할 수도 있음 - BUT, 기존의 cross-lingual TTS 모델들은 대부분 speaker-dependent information을 포함하는 mel-spectrogram을 acoustic feature로 사용하므로 correlated factor를 disentangle 하기 어려움
- Mel-spectrogram은 time, frequency axis에 따라 highly correlate 되어 있기 때문
- 한편으로 Speech-Based Self-Supervised Learning (SBSSL)에 기반하여, discrete vector-quantized (VQ) representation을 mel-spectrogram의 대체로 사용할 수 있음
- 여기서 SBSSL 모델은 raw waveform을 input으로 하여 time axis에 대해서만 correlate 됨 - 결과적으로, quantized output은 기존의 mel-sepctrogram 보다 더 coarse 한 speech feature를 가지므로 speaker-dependent information을 줄일 수 있음
- 실제로 VQTTS는 self-supervised VQ acoustic feature를 도입하여 뛰어난 naturalness를 달성
-> 그래서 VQ acoustic feature를 기반으로 한 cross-lingual TTS 모델인 DSE-TTS를 제안
- DSE-TTS
- 효과적인 disentangling을 위해, mel-spectrogram 보다 더 적은 speaker-specific information을 포함하는 VQ acoustic feature를 도입
- 이때 wav2vec 2.0으로 추출된 self-supervised VQ feature를 활용하여 timbre와 linguistic information을 decouple 함 - Dual Speaker Embedding (DSE)는 linguistic speaking style과 speaker timbre를 개별적으로 모델링함으로써 nativness를 향상
- 효과적인 disentangling을 위해, mel-spectrogram 보다 더 적은 speaker-specific information을 포함하는 VQ acoustic feature를 도입
< Overall of DSE-TTS >
- Mel-spectrogram을 대체하는 VQ acoustic feature와 nativeness 향상을 위한 Dual Speaker Embedding을 활용
- 결과적으로 cross-lingual TTS에서 기존보다 뛰어난 성능을 달성
2. Method
- Input Representation
- 먼저 input text는 normalize 되고 Phonemizer를 사용하여 International Phonetic Alphabet (IPA) phoneme으로 변환됨
- 여기서 text와 speech 간의 alignment를 위해, input sequence에서 다양한 language의 tone과 stress를 preserve 함
- 그리고 pause length에 따라 $\mathrm{sp1,sp2,sp3,sp4}$의 4가지 group으로 categorize 된 shared punctuation token을 사용
- 각 sentence의 start/end token으로 $\text{sil}$을 사용 - 최종적으로 txt2vec의 text encoder에 input sequence를 전달하기 전에, 각 phoneme (token)에 embedding table을 적용해 384-dimensional vector를 얻음

- Model Architecture
- Self-Supervised VQ Features
- DSE-TTS에서는 각각 320개의 codeword를 포함하는 2개의 quantized codebook을 가지는 wav2vec 2.0을 사용하여 VQ acoustic feature를 추출함
- wav2vec 2.0은 다른 VQ feature들 보다 더 적은 speaker information을 포함하고 있기 때문 - 각 input speech를 20ms stride로 multiple frame으로 quantize 하고, 각 frame은 각 codebook에서 2개의 256-dimensional codeword를 concatenate 하여 represent 할 수 있음
- 이때 mixed-language dataset에서 possible index combination은 28.8K개 이고, high-fidelity reconstruction을 위해서는 해당 index pair를 정확하게 예측해야 함
- 따라서 VQTTS의 VQ feature predictor를 LSTM에서 convolutional neural network로 대체
- 추가적으로, 각 codebook의 index를 개별적으로 예측하여 2가지의 320-class classification problem을 resulting 함
- DSE-TTS에서는 각각 320개의 codeword를 포함하는 2개의 quantized codebook을 가지는 wav2vec 2.0을 사용하여 VQ acoustic feature를 추출함
- Phone-Level (PL) Auxiliary Labelling
- DSE-TTS는 log pitch, energy, probability of voice (POV)를 auxiliary feature로 사용함
- 이를 위해,
- 먼저 mixed language dataset의 phone-level representation을 계산하고 normalize 함
- 이후 $k$-means clustering을 적용하여 해당 representation을 128개의 distinct class로 group 함
- 결과적으로 생성된 clustered index를 PL information에 대한 auxiliary label로 사용
- 해당 ground-truth PL auxiliary label은 multi-lingual auxiliary controller training과 subsequent duration modeling/acoustic feature generation을 위한 condition으로써 사용됨
- Dual Speaker Embedding
- Cross-lingual TTS에서는 speaker timbre를 정확하게 retain 하고 first language의 accent를 제거하는 것이 어려우므로 unnatural 한 결과가 얻어짐
- 이는 TTS에서 주로 사용되는 mel-spectrogram이 speaker와 language에 대해 entangle 되어 있기 때문
- 반면 self-supervised VQ feature는 speaker identity를 훨씬 적게 포함하고 있으므로, VQ-based TTS에서는 acoustic model에서 speaker/language를 disentangle 하기 위한 technique을 적용할 필요가 없음
- 즉, acoustic model은 textual/linguistic characteristic 모델링에 온전히 집중할 수 있고, speaker timbre controlling은 vocoder로 delegate 됨
- 결과적으로 VQ-based TTS는 더 native 한 cross-lingual synthesis가 가능해짐 - 여기서 논문은 Dual Speaker Embedding (DSE)를 도입하여 VQ-based TTS의 nativeness를 더욱 향상함
- 전체적으로, 각 speaker embedding은 acoustic model인 txt2vec과 vocoder vec2wav에 각각 전달됨
- 이때 training stage에서 native speaker의 text-speech pair가 주어지면, 두 speaker embedding은 모두 동일한 speaker에 연관됨
- 반면 synthesis stage에서는 txt2vec은 input text language의 speaker embedding을 사용하고 vec2wav는 target speaker의 speaker embedding을 사용함 - 즉, cross-lingual인 경우, txt2vec에서 native embedding을 선택하고 timbre를 control 하는 vec2wav에서 target speaker embedding을 선택하게 됨
- 결과적으로 해당 dual embedding을 통해 language-specific speaking style과 speaker timbre를 분리할 수 있음
- 전체적으로, 각 speaker embedding은 acoustic model인 txt2vec과 vocoder vec2wav에 각각 전달됨
- 구조적으로 acoustic model인 txt2vec은 speaker ID와 language ID를 input으로 사용함
- Speaker ID는 256-dimensional vector에 embed 된 다음, project 되어 encoder output에 더해짐
- Language ID는 128-dimensional vector를 사용 - vec2wav의 경우, X-vector를 speaker embedding으로 사용하여 pre-trained speaker recognition model에서 추출된 timbre를 control 함
- 추가적으로 cross-lingual synthesis에서 timbre를 target speaker와 가깝게 하기 위해, txt2vec에서 예측한 native speaker의 pitch distribution을 target speaker의 pitch로 shift 함:
(Eq. 1) $P_{\text{tgt}}=\sigma_{\text{tgt}}\frac{P_{\text{ntv}}-\mu_{\text{ntv}}}{\sigma_{\text{ntv}}} +\mu_{\text{tgt}}$
- $\text{tgt}, \text{ntv}$ : 각각 target, native speaker
- $\mu, \sigma$ : training set에서 target/native speaker의 pitch value의 평균, 표준편차
- 해당 pitch shift는 auxiliary feature가 vec2wav로 전달되기 전에 수행됨
- Speaker ID는 256-dimensional vector에 embed 된 다음, project 되어 encoder output에 더해짐
3. Experiments
- Settings
- Dataset : M-AILABS, LibriTTS, AISHELL3
- Comparisons : SANE-TTS

- Results
- Speaker-Independent VQ Acoustic Feature
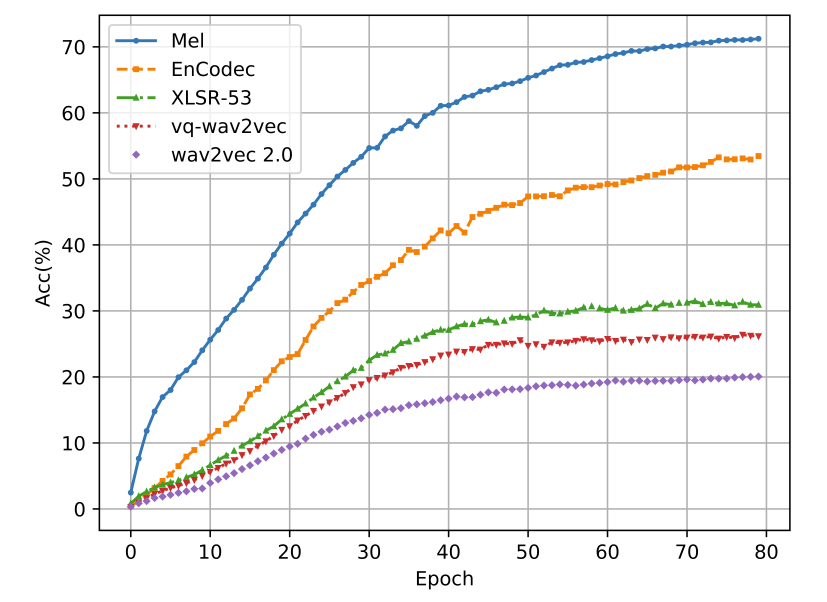
- TTS 모델의 acoustic feature로써 mel-spectrogram, vq-wav2vec, wav2vec 2.0, XLSR-53, EnCodec을 비교
- 결과적으로 mel-spectrogram에는 speaker identity에 대한 information이 충분히 포함되어 있어 높은 speaker classification 성능을 보임
- 반면 VQ feature는 speaker information이 적으므로 상대적으로 낮은 speaker classification 성능을 보임 - 결과적으로 논문은 speaker-dependent information을 가장 적게 포함하는 wav2vec 2.0을 acoustic feature로 채택
- Intralingual Synthesis
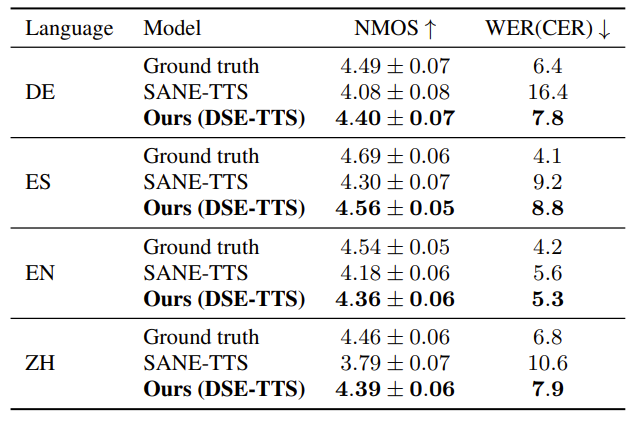
- NMOS, WER 측면에서 DSE-TTS가 가장 우수한 성능을 보임
- 구체적으로 DSE-TTS는 각 language에 대해 4.3 이상의 NMOS를 달성함
- Cross-lingual Synthesis
- 마찬가지로 cross-lingual 환경에서도 DSE-TTS가 가장 좋은 성능을 보임
- 추가적으로 ablation study 측면에서, DSE를 제거하는 경우 성능 저하가 발생함

반응형
'Paper > TTS' 카테고리의 다른 글
댓글