

 [Paper 리뷰] Fast DCTTS: Efficient Deep Convolutional Text-to-Speech
[Paper 리뷰] Fast DCTTS: Efficient Deep Convolutional Text-to-Speech
Fast DCTTS: Efficient Deep Convolutional Text-to-SpeechSingle CPU에서 real-time으로 동작하는 end-to-end text-to-speech model이 필요함Fast DCTTS다양한 network reduction과 fidelity improvement technique을 적용한 lightweight networkGating mechanism의 efficiency와 regularization effect를 고려한 group highway activation을 도입추가적으로 output mel-spectrogram의 fidelity를 측정하는 Elastic Mel-Cepstral Distortion metric을 설계논문 (ICASSP 2021) ..
 [Paper 리뷰] TriAAN-VC: Triple Adaptive Attention Normalization for Any-to-Any Voice Conversion
[Paper 리뷰] TriAAN-VC: Triple Adaptive Attention Normalization for Any-to-Any Voice Conversion
TriAAN-VC: Triple Adaptive Attention Normalization for Any-to-Any Voice ConversionVoice Conversion은 source speech의 content를 유지하면서 target speaker의 characteristic을 반영해야 함TriAAN-VCEncoder-Decoder architecture와 attention-based adaptive normalization block으로 구성된 Triple Adaptive Attention Normalization을 활용Adaptive normalization block을 통해 target speaker representation을 추출하고 siamese loss로 최적화를 수행논문 (ICA..
 [Paper 리뷰] Wav2Vec-VC: Voice Conversion via Hidden Representations of Wav2Vec 2.0
[Paper 리뷰] Wav2Vec-VC: Voice Conversion via Hidden Representations of Wav2Vec 2.0
Wav2Vec-VC: Voice Conversion via Hidden Representations of Wav2Vec 2.0Voice conversion을 위해 wav2vec 2.0 representation을 사용할 수 있음Wav2Vec-VCWav2Vec 2.0 layer의 hidden representation을 aggregate 하여 disentanglement-based voice conversion의 성능을 향상Target utterance가 주어졌을 때, speaker/content-related task를 수행하기 위해 hidden representation을 weighting 하여 활용논문 (ICASSP 2024) : Paper Link1. IntroductionHuBERT, wav2ve..
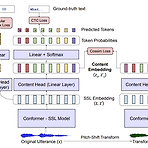 [Paper 리뷰] ACE-VC: Adaptive and Controllable Voice Conversion using Explicitly Disentangled Self-Supervised Speech Representations
[Paper 리뷰] ACE-VC: Adaptive and Controllable Voice Conversion using Explicitly Disentangled Self-Supervised Speech Representations
ACE-VC: Adaptive and Controllable Voice Conversion using Explicitly Disentangled Self-Supervised Speech RepresentationsVoice conversion을 위해 self-supervised learning으로 얻어진 speech representation을 활용할 수 있음ACE-VCContent/speaker representation을 disentangle 하기 위해 original과 pitch-shifted audio content representation 간의 similarity에 기반한 siamese network를 활용Decomposed representation으로부터 speech signal을 reco..
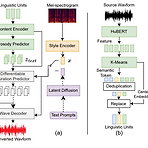 [Paper 리뷰] PromptVC: Flexible Stylistic Voice Conversion in Latent Space Driven by Natural Language Prompts
[Paper 리뷰] PromptVC: Flexible Stylistic Voice Conversion in Latent Space Driven by Natural Language Prompts
PromptVC: Flexible Stylistic Voice Conversion in Latent Space Driven by Natural Language Prompts기존의 voice conversion은 pre-defined label이나 reference speech에 의존적이므로 style의 한계가 있음PromptVCLatent diffusion model을 활용하여 natural language prompt에 의해 driven 된 style vector를 생성Style expressiveness를 향상하기 위해 HuBERT를 활용하여 discrete token을 추출하고, $k$-means center embedding을 적용하여 residual style information을 최소화추가적..
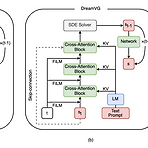 [Paper 리뷰] DreamVoice: Text-Guided Voice Conversion
[Paper 리뷰] DreamVoice: Text-Guided Voice Conversion
DreamVoice: Text-Guided Voice ConversionText-guided generation을 활용하면 user need에 따른 음성을 합성할 수 있음DreamVoiceEnd-to-End diffusion-based text-guided voice conversion을 위한 DreamVC와 text-to-voice generation을 위한 DreamVG를 제공추가적으로 VCTK, LibriTTS에 대한 voice timbre annotation을 가진 DreamVoiceDB dataset을 구축논문 (INTERSPEECH 2024) : Paper Link1. IntroductionVoice Conversion (VC)는 training/inference 중에 target voice의..