

티스토리 뷰
Paper/TTS
[Paper 리뷰] EmoQ-TTS: Emotion Intensity Quantization for Fine-Grained Controllable Emotional Text-to-Speech
feVeRin 2024. 7. 31. 09:28반응형
EmoQ-TTS: Emotion Intensity Quantization for Fine-Grained Controllable Emotional Text-to-Speech
- Emotional text-to-speech를 위해 대부분은 emotion label이나 reference audio에 의존함
- BUT, utterance-level emotion condition으로 인해 expression이 monotonous 하다는 한계가 있음 - EmoQ-TTS
- Fine-grained emotion intensity와 phoneme-wise emotion information을 conditioning하여 expressive speech를 합성
- Emotion intensity는 human labeling 없이 distance-based intensity quantization을 통해 rendering됨
- 논문 (ICASSP 2022) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 여전히 pitch, tone, tempo와 같은 paralinguistic feature 측면에서 expressive speech를 합성하는데 한계가 있음
- 특히 emotion information은 다양한 paralinguistic characteristic에 큰 영향을 받음
- 이를 위해 emotional TTS에서는 일반적으로 reference audio나 emotion label에서 추출된 global emotion information을 conditioning 하는 방식을 사용함
- BUT, 해당 방식은 전체 sentence가 하나의 global condition에 의해 regulate 되므로 monotonous expression을 생성한다는 한계가 있음 - 한편으로 emotional expression을 scaling 하거나 interpolating 하는 방식을 활용할 수도 있음
- BUT, interpolation을 위한 적절한 parameter를 결정하는 것이 어렵고 합성 품질이 unstable 함
-> 그래서 emotion intensity quantization을 활용하는 EmoQ-TTS를 제안
- EmoQ-TTS
- Fine-grained emotion intensity를 기반으로 phoneme-wise emotion information을 conditioning 해 expressive speech를 합성
- 적절한 emotional expression을 반영하기 위해 intensity pseudo-label을 활용하고 distance-based intensity quantization을 적용
- 이를 통해 text로부터 적절한 emotion intensity를 예측하여 expressive TTS를 수행하고 intensity label을 통한 control이 가능
< Overall of EmoQ-TTS >
- Distance-based intensity quantization을 활용한 emotional TTS 모델
- 결과적으로 기존보다 뛰어난 emotion controllability와 합성 품질을 달성
2. EmoQ-TTS
- Model Architecture
- EmoQ-TTS는 encoder, decoder, variance adaptor로 구성된 FastSpeech2를 기반으로 함
- 이때 논문은 emotion renderer를 도입해 fine-grained emotion intensity에 따라 phoneme-level emotion information을 제공함
- 이를 통해 pitch, energy, duration을 포함한 모든 variance information이 fine-grained emotion intensity에 영향을 받게 됨 - Duration predictor는 variance adaptor의 가장 마지막으로 이동됨
- 이를 통해 모든 variance information은 phoneme-level에서 처리되므로, frame-level 보다 더 나은 합성 품질을 달성할 수 있음
- 이때 논문은 emotion renderer를 도입해 fine-grained emotion intensity에 따라 phoneme-level emotion information을 제공함

- Emotion Renderer
- Emotion renderer는 fine-grained emotion intensity에 따라 phoneme-level emotion information을 제공함
- 구조적으로는 intensity predictor, intensity quantizer, intensity embedding table로 구성됨
- 여기서 phoneme hidden sequence $\mathcal{H}_{pho}$와 $k$-th emotion category $\text{emotion}_{k}$가 제공되면, intensity predictor는 $\text{emotion}_{k}$에 적합한 phoneme-wise emotion intensity scalar sequence를 $[0,1]$ 사이 값으로 예측함
- Intensity predictor는 ground-truth/predicted intensity scalar sequence 간의 Mean Absolute Error (MAE)로 최적화됨
- Robust training을 위해 intensity scalar는 emotion intensity quantizer를 통해 regular interval로 $N_{I}$-sized emotion intensity pseudo-label로 quantize 됨 ($N_{I}$ : quantized intensity pseudo-label 수)
- 이후 intensity embedding table을 통해 quantized intensity pseudo-label을 각 emotion에 대한 embedding table의 entry index로 활용
- 최종적으로 phoneme-wise intensity embedding sequence는 phoneme hidden sequence에 concatenate 됨
- 여기서 ground-truth intensity scalar와 intensity embedding table은 emotion intensity modeling을 통해 설계됨
- 추론 시에 EmoQ-TTS는 predicted intensity scalar에서 quantized intensity embedding을 conditioning 하여 emotional speech를 합성함
- 이때 custom label을 사용하여 intensity를 manually control 할 수 있음
- 구조적으로는 intensity predictor, intensity quantizer, intensity embedding table로 구성됨
3. Emotion Intensity Modeling
- Emotion intensity modeling은 feature extraction, emotion intensity quantization의 2-stage로 구성됨
- Emotion Feature Extraction
- 먼저 first stage에서는 mel-spectrogram에서 clustered emotion embedding을 추출하도록 reference encoder를 training 함
- Reference encoder는 각 frame의 temporal information을 maintain 하는 3개의 1D convolution layer로 구성됨
- Emotion classifier와 phoneme classifer에는 discriminative emotion embedding을 추출하도록 Gradient Reversal Layer (GRL)을 적용함
- 이를 통해 classifier는 phoneme information을 interruption 하지 않고 emotion별로 feature vector를 cluster 할 수 있음 - 추가적으로 두 classifer 모두에 softmax layer와 cross-entropy loss를 적용함
- Phoneme classifier의 경우 GRL을 통한 back-propagation 시, negative scalar를 multiplying 하여 gradient를 reverse 함
- Emotion classifier와 phoneme classifer에는 discriminative emotion embedding을 추출하도록 Gradient Reversal Layer (GRL)을 적용함
- 이후 token-wise pooling layer는 각 phoneme boundary에서 range를 averaging 하여 frame-level sequence를 phoneme-level sequence로 변환함
- 여기서 pitch, energy를 각각 예측하는 2개의 auxiliary predictor가 추가됨
- 해당 predictor는 emotion과 직접적으로 관련된 paralinguistic feature를 예측함으로써 clustered embedding을 통해 emotion information을 효과적으로 반영하도록 함 - Auxiliary predictor는 Mean Squared Error (MSE)로 최적화됨
- 여기서 pitch, energy를 각각 예측하는 2개의 auxiliary predictor가 추가됨
- 한편으로 emotion feature extraction module은 TTS system과 jointly training 됨
- Training 과정에서 추출된 phoneme-wise emotion embedding $\mathcal{H}_{E}$는 emotion renderer로 전달되고, intensity embedding sequence 대신 phoneme hidden sequence와 concatenate 됨
- Reference encoder는 각 frame의 temporal information을 maintain 하는 3개의 1D convolution layer로 구성됨
- Distance-based Emotion Intensity Quantization
- Second stage에서는 intensity quantization을 통해 emotion intensity pseudo-label과 intensity embedding table을 생성함
- 먼저 $k$-th emotion embedding $E_{kj}$와 neutral embedding $E_{nj}$의 두 cluster가 emotion intensity extractor로 전달된다고 하자
- $j\in\{1,2,...,N_{k}\}$, $N_{k}$ : $E_{kj}$의 총 개수
- 논문에서는 reference encoder에서 추출된 각 emotion에 대한 entire emotion embedding을 사용 - 이를 기반으로 EmoQ-TTS는 적절한 intensity를 추출하기 위해 vector가 neutral emotion의 centroid에서 상대적으로 얼마나 떨어져 있는지를 나타내는 emotion distance를 도입함
- 여기서 논문은 다음의 2가지 가정을 반영
- Neutral emotion은 다른 emotion보다 intensity가 가장 약함
- Neutral emotion에서 멀어질수록 emotion intensity는 증가함 - Multi-dimensional space는 distance를 측정하기에 unstable 하므로 emotion intensity extractor는 주어진 emotion embedding을 single vector에 projection 하여 사용
- 여기서 논문은 다음의 2가지 가정을 반영
- EmoQ-TTS는 projection을 위해 class-sensitive method인 Linear Discriminant Analysis (LDA)를 채택함
- 결과적으로 optimal projection vector $w^{*}$은 binary-class LDA의 objective function을 최대화하여 얻어짐:
(Eq. 1) $\mathcal{L}_{LDA}(w)=\frac{(m_{k}-m_{n})^{2}}{s_{k}^{2}+s_{n}^{2}}=\frac{w^{T}S_{B}w}{ w^{T}S_{W}w}$
- $m_{k}, m_{n}$ : 각각 $E_{kj},E_{nj}$의 평균, $s_{k}^{2}, s_{n}^{2}$ : $E_{kj}, E_{nj}$의 분산
- $w$ : projection vector, $S_{B},S_{W}$ : 두 cluster의 between-class/within-class 분산 - Binary-class LDA로 $w^{*}$을 얻은 다음 emotion embedding $E_{kj}, E_{nj}$는 optimal projection vector $w^{*}$에 projection 되고, 이때 projected emotion embedding $E'_{kj},E'_{nj}$는:
(Eq. 2) $E'_{kj}=\frac{E_{kj}\cdot w^{*}}{|| w^{*}||_{2}^{2}}w^{*}$ - 다음으로 emotion distance $d_{kj}$는 projected emotion embedding $E'_{kj}$와 projected neutral embedding $E'_{nj}$의 centroid 간 euclidean distance로 얻어짐:
(Eq. 3) $d_{kj}=|| E'_{kj}-M'_{n}||_{2}\,\, \text{where}\,\, M'_{n}=\frac{1}{N_{n}}\sum_{j=1}^{N_{n}}E'_{nj}$
- $M'_{n}$ : projected neutral embedding의 centroid - Emotion distance를 계산한 다음, interquartile range technique을 적용하여 각 emotion에 대한 outlier를 제거하고, min-max normalization을 통해 $[0,1]$ range를 가지는 intensity scalar로 변환함
- 해당 intensity scalar는 regular interval로 $N_{I}$-sized emotion intensity pseudo-label로 quantize 됨
- 결과적으로 optimal projection vector $w^{*}$은 binary-class LDA의 objective function을 최대화하여 얻어짐:
- 추가적으로 intensity pseudo-label을 반영하기 위해 intensity embedding table을 도입함
- Intensity embedding table에서 $I$-th intensity embedding은 intensity pseudo-label에 해당하는 reference encoder의 emotion embedding 평균으로 정의됨:
(Eq. 4) $I_{kl}=\frac{1}{N_{kl}}\sum_{i_{kj}\in C_{kl}}E_{kj}$
- $I_{kl}$ : intensity embedding table에서 $\text{emotion}_{k}$의 $l$-th intensity embedding
- $i_{kj}$ : $E_{kj}$의 pseudo-label, $C_{kl}$ : $l$-th intensity에 해당하는 $i_{kj}$ group
- $N_{kl}$ : $i_{kj}\in C_{kl}$을 만족하는 emotion embedding 수 - Intensity label은 각 emotion에 대한 intensity embedding table의 entry index와 같고, 해당 embedding table은 emotion renderer에서 사용됨
- Intensity embedding table에서 $I$-th intensity embedding은 intensity pseudo-label에 해당하는 reference encoder의 emotion embedding 평균으로 정의됨:
- 먼저 $k$-th emotion embedding $E_{kj}$와 neutral embedding $E_{nj}$의 두 cluster가 emotion intensity extractor로 전달된다고 하자
4. Experiments
- Settings
- Dataset : KES, ETOD
- Comparisons : TP-GST, FEP + FastSpeech2
- Results
- 전체적으로 EmoQ-TTS의 성능이 가장 뛰어남

- A/B test 측면에서도 EmoQ-TTS가 가장 선호됨

- Emotion Controllability
- Pitch/energy tendency를 비교해 보면, EmoQ-TTS는 각 emotion intensity를 versatile 하게 반영함

- 특히 EmoQ-TTS는 하나의 sample에 대해서도 emotion, intensity에 따라 pitch, duration을 반영할 수 있음
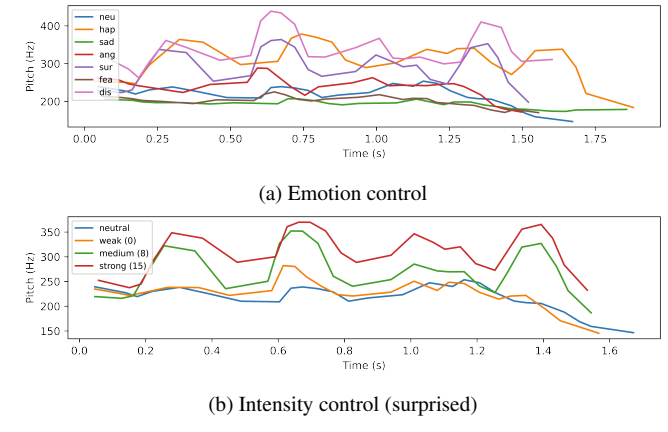
- Ablation Study
- Reference encoder, projection method, intensity quantization 모두 합성 품질에 큰 영향을 미침

반응형
'Paper > TTS' 카테고리의 다른 글
댓글