

 [Paper 리뷰] Avocodo: Generative Adversarial Network for Artifact-Free Vocoder
[Paper 리뷰] Avocodo: Generative Adversarial Network for Artifact-Free Vocoder
Avocodo: Generative Adversarial Network for Artifact-Free VocoderGenerative Adversarial Network (GAN) 기반의 vocoder는 고품질의 음성 합성이 가능함- 이때 대부분의 speech component는 low-frequency band에 집중되어 있기 때문에 downsampling을 통한 multi-scale analysis를 활용BUT, multi-scale analysis는 unintended artifact를 발생시킬 가능성이 높음AvocodoArtifact 발생을 줄여 고품질의 합성이 가능한 GAN-based VocoderCollaborative multi-band discriminator와 sub-band discr..
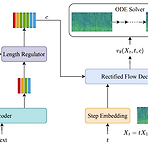 [Paper 리뷰] ReFlow-TTS: A Rectified Flow Model for High-Fidelity Text-to-Speech
[Paper 리뷰] ReFlow-TTS: A Rectified Flow Model for High-Fidelity Text-to-Speech
ReFlow-TTS: A Rectified Flow Model for High-Fidelity Text-to-SpeechDiffusion model이 음성 합성에서 우수한 성능을 보이고 있지만, 고품질 음성 합성을 위해서는 여전히 많은 sampling step이 필요함 ReFlow-TTSRectified Flow를 활용한 Text-to-Speech 모델Gaussian 분포를 straight line을 통해 ground-truth mel-spectrogram 분포로 transport 하는 Ordinary Differential Equation을 활용논문 (ICASSP 2024) : Paper Link1. IntroductionText-to-Speech (TTS)는 acoustic model과 vocoder..
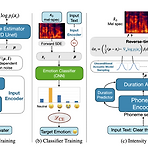 [Paper 리뷰] EmoDiff: Intensity Controllable Emotional Text-to-Speech with Soft-Label Guidance
[Paper 리뷰] EmoDiff: Intensity Controllable Emotional Text-to-Speech with Soft-Label Guidance
EmoDiff: Intensity Controllable Emotional Text-to-Speech with Soft-Label Guidance 최신 Text-to-Speech 모델들은 고품질 음성을 합성할 수 있지만, emotion에 대한 intensity controllability는 떨어짐 - Intensity 계산을 위한 external optimization이 필요하기 때문 EmoDiff Classifier guidance에서 파생된 soft-label guidance를 diffusion 기반 text-to-speech 모델에 적용 Specified emotion과 Neutral을 emotion intensity $\alpha, 1-\alpha$로 나타내는 soft-label을 활용 논문 (I..
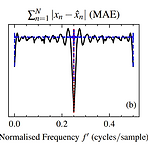 [Paper 리뷰] Sinusoidal Frequency Estimation by Gradient Descent
[Paper 리뷰] Sinusoidal Frequency Estimation by Gradient Descent
Sinusoidal Frequency Estimation by Gradient Descent Gradient descent를 사용하여 sinusoidal frequency parameter를 추정하는 것은 어려움 - Error function이 non-convex 하고 local minima에 densely populated 되어 있기 때문 Sinusoidal Frequency Estimation by Gradient Descent Complex exponential surrogate의 Wirtinger derivative와 first order gradient-based optimizer를 활용 Differentiable signal processing을 oscillatory component의 fre..
 [Paper 리뷰] DiffWave: A Versatile Diffusion Model for Audio Synthesis
[Paper 리뷰] DiffWave: A Versatile Diffusion Model for Audio Synthesis
DiffWave: A Versatile Diffusion Model for Audio Synthesis Conditional/Unconditional waveform generation을 위해 diffusion probabilistic model을 사용할 수 있음 DiffWave Non-autoregressive 하고 Markov chain을 통해 white noise signal을 waveform으로 변환하는 모델 - Data likelihood에 대한 variational bound를 최적화함으로써 학습됨 Mel-spectrogram에 따라 condition 된 neural vocoding, class-conditional generation, unconditional generation 작업에서 활..
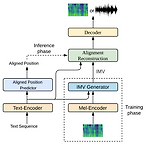 [Paper 리뷰] EfficientTTS: An Efficient and High-Quality Text-to-Speech Architecture
[Paper 리뷰] EfficientTTS: An Efficient and High-Quality Text-to-Speech Architecture
EfficientTTS: An Efficient and High-Quality Text-to-Speech Architecture Text-to-Speech를 위해 non-autoregressive architecture는 많은 이점을 가지고 있음 EfficientTTS External aligner를 필요로 하는 autoregressive 모델과 달리, 안정적인 end-to-end 학습을 지원하여 효율적이면서 고품질의 음성 합성이 가능 연산량을 증가시키지 않고, sequence alignment에 monotonic constraint를 반영할 수 있는 monotonic alignment modeling을 제시 EfficientTTS를 다양한 feed-forward network 구조와 결합하여 Text-..