

 [Paper 리뷰] Meta-StyleSpeech: Multi-Speaker Adaptive Text-to-Speech Generation
[Paper 리뷰] Meta-StyleSpeech: Multi-Speaker Adaptive Text-to-Speech Generation
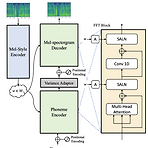
Meta-StyleSpeech: Multi-Speaker Adaptive Text-to-Speech Generation Text-to-Speech 모델은 주어진 speaker에서 나온 few audio sample 만을 사용하여 고품질 음성을 합성할 수 있어야 함 StyleSpeech 고품질 합성이 가능하고 새로운 speaker에 대해 효과적으로 adaptaion 하는 TTS 모델 Reference에서 추출된 style에 따라 text input의 gain과 bias를 align 하는 Style-Adaptive Layer Normalization을 도입 Meta-StyleSpeech 새로운 speaker에 대한 StyleSpeech의 adaptation을 향상하기 위해 style prototype으로 학..
 [Paper 리뷰] FedSpeech: Federated Text-to-Speech with Continual Learning
[Paper 리뷰] FedSpeech: Federated Text-to-Speech with Continual Learning
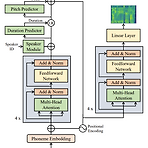
FedSpeech: Federated Text-to-Speech with Continual Learning Federated text-to-speech는 여러 사용자의 음성을 device에 locally store 된 few audio sample과 합성하는 것을 목표로 함 Federated text-to-speech는 각 speaker에 대한 training sample이 거의 없고, sample이 각 local device에만 store 되어 있고, global model이 다양한 공격에 취약하다는 어려움이 있음 FedSpeech Gradual pruning mask를 사용하여 speaker tone을 preserving 하기 위해 parameter를 isolate 함 Task에서 얻은 knowled..
 [Paper 리뷰] Lightweight and Interpretable Neural Modeling of an Audio Distortion Effect Using Hyperconditioned Differentiable Biquads
[Paper 리뷰] Lightweight and Interpretable Neural Modeling of an Audio Distortion Effect Using Hyperconditioned Differentiable Biquads
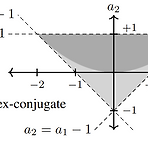
Lightweight and Interpretable Neural Modeling of an Audio Distortion Effect Using Hyperconditioned Differentiable Biquads Audio distortion effect를 모델링하기 위해 differentiable cacaded biquads를 사용할 수 있음 Hyperconditioned Differentiable Biquads Trainable Infinite Impulse Response (IIR) filter를 hyperconditioned case로 확장 Transformation은 distortion effect의 external parameter를 internal filter와 gain paramete..
 [Paper 리뷰] ProsoSpeech: Enhancing Prosody with Quantized Vector Pre-training in Text-to-Speech
[Paper 리뷰] ProsoSpeech: Enhancing Prosody with Quantized Vector Pre-training in Text-to-Speech
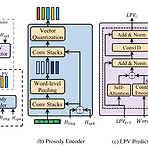
ProsoSpeech: Enhancing Prosody with Quantized Vector Pre-training in Text-to-Speech Text-to-Speech에서 prosody 모델링을 위해서는 몇 가지 어려움이 있음 - 추출된 pitch에는 inevitable error가 포함되어 있어 prosody 모델링을 저해함 - Pitch, duration, energy와 같은 prosody의 다양한 특성은 서로 dependent 함 - Prosody의 high variability로 인해 prosody 분포를 fully shape 하기 어려움 ProsoSpeech Low-quality text와 speech data에 대해 pre-train 된 quantized latent vector를 도..
 [Paper 리뷰] WaveFlow: A Compact Flow-based Model for Raw Audio
[Paper 리뷰] WaveFlow: A Compact Flow-based Model for Raw Audio
WaveFlow: A Compact Flow-based Model for Raw Audio Raw audio 합성을 위해 maximum likelihood를 활용하는 generative flow model을 구성할 수 있음 WaveFlow Dilated 2D convolution을 활용하여 1D waveform의 long-range structure를 capture 하고, expressive autoregressive function을 통해 local variation을 모델링 효율적인 합성을 위해 likelihood gap을 줄임 논문 (ICML 2020) : Paper Link 1. Introduction 기존의 autoregressive model은 raw audio에 대해 가장 높은 likelih..
 [Paper 리뷰] WaveGrad: Estimating Gradients for Waveform Generation
[Paper 리뷰] WaveGrad: Estimating Gradients for Waveform Generation
WaveGrad: Estimating Gradients for Waveform Generation Score mathcing과 diffusion probabilistic model을 waveform generation에 활용할 수 있음 WaveGrad Data density의 gradient를 추정하는 waveform generation을 위한 conditional model Gaussian white noise에서 시작하여 mel-spectrogram에 따라 condition 된 gradient-based sampler를 활용 논문 (ICRL 2021) : Paper Link 1. Introduction Autorgressive 모델을 raw waveform 생성에서 활용할 수 있지만, sequenti..