

 [Paper 리뷰] Pengi: An Audio Language Model for Audio Tasks
[Paper 리뷰] Pengi: An Audio Language Model for Audio Tasks
Pengi: An Audio Language Model for Audio Tasks Audio domain에서 사용되는 language model에는 Audio Captioning이나 Audio Question Answering과 같은 open-ended task를 처리하는 기능이 부족함 Pengi 모든 audio task를 text generation task로 framing 하고 transfer learning을 적용하는 audio language model Text encoder와 audio encoder는 continuous embedding sequence로 각각의 input을 represent 하고, 얻어진 두 sequence는 pre-trained frozen language model을 p..
 [Paper 리뷰] SC-GlowTTS: An Efficient Zero-Shot Multi-Speaker Text-to-Speech Model
[Paper 리뷰] SC-GlowTTS: An Efficient Zero-Shot Multi-Speaker Text-to-Speech Model
SC-GlowTTS: An Efficient Zero-Shot Multi-Speaker Text-to-Speech Model Unseen speaker에 대한 similarity를 향상하는 zero-shot text-to-speech 모델이 필요함 SC-GlowTTS Flow-based decoder를 기반으로 speaker-conditional architecture를 도입 Text encoder로써 dilated residual convolutional-based encoder, gated convolutional-based encoder, transformer-based enocoder를 비교 추가적으로 text-to-speech 모델을 통해 예측된 spectrogram에 대해 GAN-based v..
 [Paper 리뷰] AudioGen: Textually Guided Audio Generation
[Paper 리뷰] AudioGen: Textually Guided Audio Generation
AudioGen: Textually Guided Audio Generation Text-to-Audio 생성에는 몇 가지 어려움이 있음 - 동시에 말하는 speaker를 분리하는 것과 같이 object를 구별하는 것이 어려움 - Scarce text annotation은 모델의 확장을 어렵게 함 - 고품질 audio 합성을 위해서는 높은 sampling rate가 필요하므로 sequence가 길어짐 AudioGen Learnt discrete audio representation을 기반으로 동작하는 autoregressive 모델 다양한 audio sample을 mix 하여 모델이 source 분리를 internally learn 하는 augmentation을 도입 빠른 추론을 위해 multi-strea..
 [Paper 리뷰] Simple and Controllable Music Generation
[Paper 리뷰] Simple and Controllable Music Generation
Simple and Controllable Music Generation Conditional music generation을 위해 Language Model (LM)을 도입 MusicGen Token interleaving pattern을 활용하는 single-stage transformer LM으로 구성하여 cascading한 model 구성을 회피 Textual description이나 melodic feature를 condition으로 하여 고품질 음성을 생성 가능 논문 (NeurIPS 2024) : Paper Link 1. Introduction Text-to-Music은 text description이 주어지면 그에 해당하는 음악을 생성하는 작업 일반적으로 음악을 생성하는 것은 long-ran..
 [Paper 리뷰] Denoising Diffusion Probabilistic Models
[Paper 리뷰] Denoising Diffusion Probabilistic Models
Denoising Diffusion Probabilistic Models Nonequilibrium thermodynamics에서 영감을 받은 latent variable model인 diffusion probabilistic model을 사용하여 고품질의 이미지 합성을 시도 Denoising Diffusion Probabilistic Model (DDPM) Diffusion probabilistic model과 Langevin dynamics를 연결하는 denoising score matching을 활용 Autoregressive decoding의 generalization으로 해석될 수 있는 progressive lossy decompression을 허용 논문 (NeurIPS 2020) : Paper..
 [Paper 리뷰] PortaSpeech: Portable and High-Quality Generative Text-to-Speech
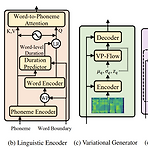
[Paper 리뷰] PortaSpeech: Portable and High-Quality Generative Text-to-Speech
PortaSpeech: Portable and High-Quality Generative Text-to-Speech Non-autoregressive Text-to-Speech 모델은 고품질의 음성 합성이 가능하지만 몇 가지 한계가 있음 - VAE는 작은 모델 size로도 long-range semantic feature를 capture 할 수 있지만, 종종 부자연스러운 결과를 생성함 - Normalizing Flow는 frequency bin-wise detail을 reconstruct 하는데 좋지만, 많은 parameter 수를 필요로 함 PortaSpeech Lightweight architecture를 사용하여 고품질의 음성 합성을 지원하는 TTS 모델 Enhanced prior를 포함한 ligh..