

티스토리 뷰
Paper/Vocoder
[Paper 리뷰] WaveFlow: A Compact Flow-based Model for Raw Audio
feVeRin 2024. 2. 18. 12:47반응형
WaveFlow: A Compact Flow-based Model for Raw Audio
- Raw audio 합성을 위해 maximum likelihood를 활용하는 generative flow model을 구성할 수 있음
- WaveFlow
- Dilated 2D convolution을 활용하여 1D waveform의 long-range structure를 capture 하고, expressive autoregressive function을 통해 local variation을 모델링
- 효율적인 합성을 위해 likelihood gap을 줄임
- 논문 (ICML 2020) : Paper Link
1. Introduction
- 기존의 autoregressive model은 raw audio에 대해 가장 높은 likelihood score를 제공하여 high-fidelity의 auido를 생성함
- BUT, 추론 과정에서 1D waveform sample을 sequential하게 생성하므로 매우 느린 추론 속도를 보임
- Flow-based model은 invertible transform을 활용하여 단순한 initial density를 복잡한 density로 변환하는 generative model
- Flow-based model은 주로 Autoregressive Flow (AF)와 Inverse Autoregressive Flow (IAF)를 활용하는 autoregressive transformation에 기반을 두고 있음
- AF는 parallel density evaluation과 sequential synthesis를 수행
- IAF도 parallel synthesis를 수행할 수 있지만, sequential density evaluation이 필요하므로 likelihood-based training을 느리게 만듦
- 이를 해결하기 위해 Paralle WaveNet, CalriNet 등이 제안되었지만, intractable KL divergence를 근사하는 Monte Carlo method와 같은 복잡한 pipeline이 필요함
- AF는 parallel density evaluation과 sequential synthesis를 수행
- Flow-based model의 다른 측면에서는, bipartite transformation을 활용하는 방법도 있음
- 대표적으로 WaveGlow가 이 방식을 통해 우수한 성능을 달성함
- BUT, bipartite flow는 autoregressive model 보다 더 많은 layer와 parameter 수가 요구됨
- i.e.) WaveNet은 4.57M의 parameter를 가지는 반면, WaveGlow는 182.64M이 필요 - 추가적으로 bipartite transformation을 적용하기 전에 channel dimension에서 time-domain sample을 squeeze 하므로 temporal order information이 손상되는 문제점이 존재
-> 따라서 raw audio 합성을 위해 기존 flow-based model의 한계점을 개선한 WaveFlow를 제안
- WaveFlow
- 추가적인 density distillation이나 auxiliary loss 없이 maximum likelihood을 통해 직접적으로 학습됨
- 1D waveform sample을 2D matrix로 squeeze하고 temporal order information을 잃지 않도록 autoregressive function을 통해 local adjacent sample을 처리 - Raw audio에 대한 likelihood-based model의 unified view를 제공
- Autoregressive model과 flow-based model 사이의 likelihood gap을 줄임
- 추가적인 density distillation이나 auxiliary loss 없이 maximum likelihood을 통해 직접적으로 학습됨
< Overall of WaveFlow >
- Dilated 2D convolution을 활용하여 1D waveform의 long-range structure를 capture
- Expressive autoregressive function을 통해 local variation을 모델링
- 결과적으로 WaveFlow는 real-time보다 40배 빠른 합성 속도를 달성하고 고품질의 음성 합성이 가능
2. Flow-based Generative Models
- Flow-based model은 bijection $x=f(z)$를 적용하여 isotropic Gaussian과 같은 단순한 density를 복잡한 분포 $p(x)$로 변환
- 여기서 $x, z$은 모두 $n$-dimensional
- 이때 $x$의 probability density는:
(Eq. 1) $p(x)=p(z)\left| \det \left( \frac{\partial f^{-1}(x)}{\partial x}\right)\right|$
- $z = f^{-1}(x)$ : bijection의 inverse
- $\det \left( \frac{\partial f^{-1}(x)}{\partial x}\right)$ : 해당 Jacobian의 determinant - 일반적으로 determinant를 계산하는데 $O(n^{3})$이 필요하므로, 위 식은 high-dimension에서는 적용하기 어려움
- 대신 triangular Jacobian과 tractable determinant를 사용하는 flow-based model의 경우, Autoregressive transformation과 Bipartite transformation의 2가지 접근 방식을 활용할 수 있음

- Autoregressive Transformation
- Autoregressive Flow와 Inverse Autoregressive Flow는 autoregressive transformation을 활용함
- Autoregressive Flow (AF)는,
- $z=f^{-1}(x;\vartheta)$를 정의함:
(Eq. 2) $z_{t}= x_{t}\cdot \sigma(x_{<t};\vartheta)+\mu_{t}(x_{<t};\vartheta)$
- Shifting variable $\mu_{t}(x_{<t};\vartheta)$와 Scaling variable $\sigma_{t}(x_{<t};\vartheta)$는 $\vartheta$에 의해 parameterize 되는 autoregressive architecture에 의해 모델링 됨 - 이때 $t$-th variable $z_{t}$는 $x\leq t$에만 의존하므로 Jacobian은 triangular matrix임
- 해당 determinant는 diagonal entry의 곱으로: $\det \left( \frac{\partial f^{-1}(x)}{\partial x}\right) = \prod_{t}\sigma_{t}(x_{<t};\vartheta)$ - $z=f^{-1}(x)$를 계산하기 위한 최소 squential operation 수는 $O(1)$이기 때문에 density $p(x)$는 (Eq. 1)을 통해 parallel evaluation 될 수 있음
- 이때 AF는 $x=f(z)$가 autoregressive 하기 때문에 sequential synthesis를 수행해야 함: $x_{t} =\frac{z_{t}-\mu_{t}(x_{<t};\vartheta)}{\sigma_{t}(x_{<t};\vartheta)}$
- $z=f^{-1}(x;\vartheta)$를 정의함:
- Inverse Autoregressive Flow (IAF)는,
- Inverse mapping $z = f^{-1}(x)$에 autoregressive transformation을 적용함:
(Eq. 3) $z_{t} = \frac{x_{t}-\mu_{t}(z_{<t};\vartheta)}{\sigma_{t}(z_{<t};\vartheta)}$ - 이때 likelihood-based sampling은 density evaluation이 매우 느리지만, $x_{t} = z_{t} \cdot \sigma_{t}(z_{<t};\vartheta) + \mu_{t}(z_{<t};\vartheta)$를 통해 $x=f(z)$를 parallel sampling 할 수 있음
- Inverse mapping $z = f^{-1}(x)$에 autoregressive transformation을 적용함:
- Autoregressive Flow (AF)는,

- Bipartite Transformation
- RealNVP와 Glow는 data $x$를 2개의 group $x_{a}, x_{b}$로 partitioning 하여 bipartite transformation을 적용
- 여기서 index는 $a \cup b = \{ 1,...,n\}$, $a \cap b = \phi$
- Inverse mapping $z= f^{-1}(x, \theta)$는:
(Eq. 4) $z_{a} = x_{a}, \,\,\, z_{b}=x_{b}\cdot \sigma_{b}(x_{a};\theta)+\mu_{b}(x_{a};\theta)$
- Shifting variable $\mu_{b}(x_{a};\theta)$와 Scaling variable $\sigma_{b}(x_{a};\theta)$는 feed-forward network에 의해 모델링 됨
- 이때 Jacobian $\frac{\partial f^{-1}(x)}{\partial x}$는 special triangular matrix - 정의에 따라, $x=f(z,\theta)$는:
(Eq. 5) $x_{a}=z_{a}, \,\,\, x_{b}=\frac{z_{b}-\mu_{b}(x_{a};\theta)}{\sigma_{b}(x_{a};\theta)}$
- $z = f^{-1}(x,\theta)$에 대한 evaluating과 $x=f(z,\theta)$ sampling은 parallel 하게 수행 가능 - 이러한 방식을 활용한 WaveGlow는 channel dimension에서 time-domain sample을 squeeze 한 다음, partitioned channel에 bipartite transformation을 적용함
- 해당 squeeze 과정에서 temporal order information이 손실되므로 합성된 audio에는 아래 그림과 같은 constant frequency noise가 나타남
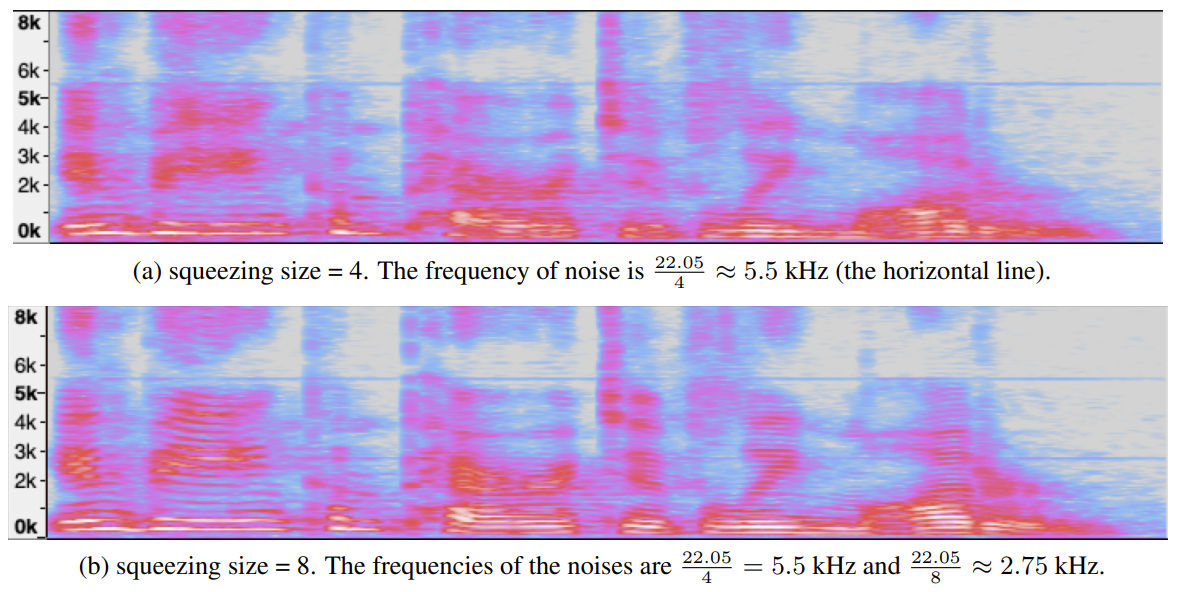
- Connections
- Autoregressive transformation은 bipartite transformation보다 뛰어난 expressiveness를 가짐
- Autoregressive transformation은 $\frac{n \times (n-1)}{2}$개의 complex non-linear dependency와 data $x$와 latent $z$ 사이에 $n$개의 linear dependency를 가짐
- 그에 비해 bipartite transformation은 $\frac{n^{2}}{4}$개의 non-linear dependency와 $\frac{n}{2}$개의 linear dependency를 가짐
- 따라서 autoregressive transformation $z=f^{-1}(x;\vartheta)$를 bipartite transformation $z = f^{-1}(x;\theta)$로 reduce 할 수 있음:
- Set $a$의 모든 index가 $b$의 index보다 먼저 rank 되도록 autoregressive order $o$를 picking 하고
- Shifting, scaling variable을 다음과 같이 설정:
$\begin{pmatrix} \mu_{t}(x_{<t};\vartheta) \\ \sigma_{t}(x_{<t};\vartheta) \end{pmatrix} = \left\{\begin{matrix} (0,1)^{T}, & \textrm{for} \, t\in a \\ \left( \mu_{t}(x_{a};\theta), \sigma_{t}(x_{a};\theta) \right)^{T},& \textrm{for} \, t\in b \\ \end{matrix}\right.$
- 만약 less expressive building block이 주어지면, bipartite flow는 autoregressive model의 capacity에 도달하기 위해 더 많은 layer와 hidden size가 필요함
3. WaveFlow
- Definition
- 1D waveform을 $x = \{ x_{1}, ..., x_{n} \}$이라 하고, $x$를 column-major order로 $h$-row 2D matrix $X \in \mathbb{R}^{h \times w}$로 squeeze 하자
- 이때 adjacent sample은 동일한 column 내에 존재함
- $Z \in \mathbb{R}^{h\times w}$가 istoropic Gaussian 분포에서 sampling 된다고 할 때, $Z = f^{-1}(X;\Theta)$는:
(Eq. 6) $Z_{i,j}=\sigma_{i,j}(X_{<i, \bullet};\Theta)\cdot X_{i,j}+\mu_{i,j}(X_{<i,\bullet};\Theta)$
- $X_{<i,\bullet}$ : $i$-th row의 모든 element - 여기서, 아래 그림과 같이
- WaveFlow에서 $Z_{i,j}$를 계산하기 위해 squeeze된 input $X$에 대한 receptive field는 $h>2$일 때 WaveGlow의 receptive field보다 strictly large함
- WaveNet은 $X$에 column-major order가 있는 Autoregressive Flow와 동일
- WaveFlow와 WaveGlow 모두 $Z_{i,j}$를 계산하기 위해 original $x$의 future waveform sample을 볼 수 있지만, WaveNet은 그러지 못함
- (Eq. 6)의 shifting variable $\mu_{i,j}(X_{<i,\bullet};\Theta)$와 scaling variable $\sigma_{i,j}(X_{<i,\bullet};\Theta)$는 2D convolutional neural network로 모델링 됨
- 정의에 따라 variable $Z_{i,j}$는 raw-major order로 current $X_{i,j}$와 previous $X_{<i,\bullet}$에만 의존하므로 Jacobian은 triangular matrix이고, determinant는 다음과 같이 구해짐:
(Eq. 7) $\det \left( \frac{\partial f^{-1}(X)}{\partial X}\right) = \prod_{i=1}^{h}\prod_{j=1}^{w}\sigma_{i,j}(X_{<i,\bullet};\Theta)$ - 결과적으로 (Eq. 1)의 variable formula를 변경함으로써 log-likelihood를 parallel 하게 계산하여 효율적으로 maximum likelihood training을 수행할 수 있음:
$\log p(X) =\sum_{i,j}\left( \log \sigma_{i,j}(X_{<i,\bullet};\Theta)-\frac{Z^{2}_{i,j}}{2}-\frac{1}{2}\log (2\pi)\right)$ - 합성 시에는 isotropic Gaussian에서 $Z$를 sampling 하고 forward mapping $X=f(Z;\Theta)$를 적용:
(Eq. 8) $X_{i,j}=\frac{Z_{i,j}-\mu_{i,j}(X_{<i,\bullet};\Theta)}{\sigma_{i,j}(X_{<i,\bullet};\Theta)}$
- 이는 height dimension에 대한 autoregressive를 의미하므로, 전체 $X$를 생성하려면 $h$개의 sequential step이 필요하다는 것을 의미
- 정의에 따라 variable $Z_{i,j}$는 raw-major order로 current $X_{i,j}$와 previous $X_{<i,\bullet}$에만 의존하므로 Jacobian은 triangular matrix이고, determinant는 다음과 같이 구해짐:

- Implementation with Dilated 2D Convolution
- Dilated 2D convolution을 사용하여 WaveFlow를 구현함
- (Eq. 6)의 Shifting $\mu_{i,j}(X_{<i,\bullet};\Theta)$와 scaling $\sigma_{i,j}(X_{<i,\bullet};\Theta)$를 모델링하기 위해 2D convolution layer stack을 활용
- 구조적으로는 WaveNet과 유사한 architecture를 사용하여 dilated 1D convolution을 2D convolution으로 대체하고, gated-tanh non-linearity, residual connection을 도입
- Height, width dimension에 대해서는 filter size 3을 사용
- Width dimension에 대해 non-causal convolution을 사용하고 dilation cylce을 $[1,2,4...,2^{7}]$로 설정
- Height dimension의 convolution은 autoregressive constraint와 관련되어 있으므로 dilation cycle은 신중하게 설계되어야 함 - 경험적으로 합성 품질을 향상하기 위해서는,
- WaveNet의 dilation cycle과 비슷하게 8개 layer에 대한 dilation $d = [1,2,...,2^{s},1,2,...,2^{s},...]$로 설정
- $s \leq 7$ - Height dimension에 대한 receptive field $r$은 height $h$ 보다 크거나 같아야 함
- 그렇지 않으면 불필요한 conditional independence가 도입되어 likelihood가 낮아짐
-> 이때 dilated convolution layer stack의 receptive field는:
$r = (k-1)\times \sum_{i}d_{i}+1$ ($k$ : filter size, $d_{i}$ : $i$-th layer에서의 dilation)
-> 따라서 dilation의 sum $\sum_{i}d_{i} \geq \frac{h-1}{k-1}$을 만족해야 함
- 만약 $h$가 $2^{8} = 512$보다 크거나 같다면, dilation cycle을 $[1,2,4,..., 2^{7}]$로 설정 - $r$이 $h$보다 큰 경우, 작은 dilation을 가진 convolution이 더 큰 likelihood를 제공함
- WaveNet의 dilation cycle과 비슷하게 8개 layer에 대한 dilation $d = [1,2,...,2^{s},1,2,...,2^{s},...]$로 설정

- WaveFlow의 preferred dilation과 height는 아래 표와 같음
- 추가적으로 intermediate hidden state를 cache 하기 위해 convolution queue를 도입하여 height dimension에 대한 autoregressive 추론 속도를 향상
- WaveFlow는 fully autoregressive 하면서 $x$를 length 만큼 squeeze 하고 ($h=n$), filter size를 width dimension에 대해 1로 설정한 Gaussian WaveNet과 동일
- $x$를 $h=2$로 squeeze 하고, filter size를 height dimension에서 $1$로 설정하면 WaveFlow는 bipartite flow가 되어 squeeze channel 2를 가지는 WaveGlow와 동일해짐

- Local Conditioning for Speech Synthesis
- Neural vocoder는 linguistic feature / mel-spectrogram / learned hidden representation에 따라 condition 되는 time-domain waveform을 합성함
- WaveFlow는 ground-truth mel-spectrogram을 condition으로 하여 waveform을 합성
- 이를 위해,
- Mel-spectrogram은 transposed 2D convolution이 있는 waveform과 동일한 length로 upsampling
- 이후 waveform과 align 되기 위해서 $c \times h \times w$ shape로 squeeze
- $c$ : input channel - Input channel을 residual channel에 mapping 하는 $1\times 1$ convolution을 수행하고, 각 layer에 bias term으로 추가
- Stacking Multiple Flows with Permutations on Height Dimension
- Flow-based model은 분포 $p(X)$가 원하는 level에 도달할 때까지 transformation의 series가 필요함
- 이를 위해 $X = Z^{(n)}$이라 하고, (Eq. 6)에서 정의된 transformation $Z^{(i-1)} = f^{-1}(Z^{(i)};\Theta^{(i)})$를 $Z^{(n)}$에서 $Z^{(0)}$까지 반복적으로 적용
- 이때 $Z^{(0)}$은 isotropic Gaussian에서 얻어짐 - 따라서 $p(X)$는 chain rule을 통해 evaluate 될 수 있음:
$p(X)=p(Z^{(0)})\prod_{i=1}^{n}\left| \det \left( \frac{\partial f^{-1}(Z^{(i)};\Theta^{(i)})}{\partial Z^{(i)}}\right)\right|$ - 이때 각 transformation 이후 height dimension에 대해 각 $Z^{(i)}$를 permutating 하면, likelihood score가 크게 향상됨
- 결과적으로 다양한 autoregressive order를 얻을 수 있어 합성 품질이 향상됨
- 이를 위해 $X = Z^{(n)}$이라 하고, (Eq. 6)에서 정의된 transformation $Z^{(i-1)} = f^{-1}(Z^{(i)};\Theta^{(i)})$를 $Z^{(n)}$에서 $Z^{(0)}$까지 반복적으로 적용
4. Experiments
- Settings
- Dataset : LJSpeech
- Comparisons : Gaussian WaveNet, Autoregressive Flow, WaveGlow
- Results
- Test Log-Likelihood (LL) 측면에서 비교해 보면,
- 많은 flow를 stacking 할수록 모든 flow-based model의 LL이 향상됨
- WaveFlow는 WaveGlow보다 더 큰 likelihood를 가짐
- $h$를 증가시키면 WaveFlow의 likelihood도 증가하고 sequential step이 많아질수록 GPU에서의 추론 속도가 느려짐
- WaveNet과 비교하여, WaveFlow는 더 큰 likelihood를 얻을 수 있음
- 많은 flow를 stacking 할수록 모든 flow-based model의 LL이 향상됨

- 추론 속도와 MOS 측면에서의 합성 품질을 비교해 보면,
- 소형 WaveFlow는 5.91M의 parameter 수를 가지고 real-time보다 42.06배 빠르고, 4.32 MOS의 고품질 합성이 가능
- 대조적으로 소형 WaveGlow는 2.17 MOS를 보임 - 대형 WaveFlow는 4.43 MOS로 동일한 크기의 WaveGlow 보다 높은 합성 품질을 보임
- 소형 WaveFlow는 5.91M의 parameter 수를 가지고 real-time보다 42.06배 빠르고, 4.32 MOS의 고품질 합성이 가능
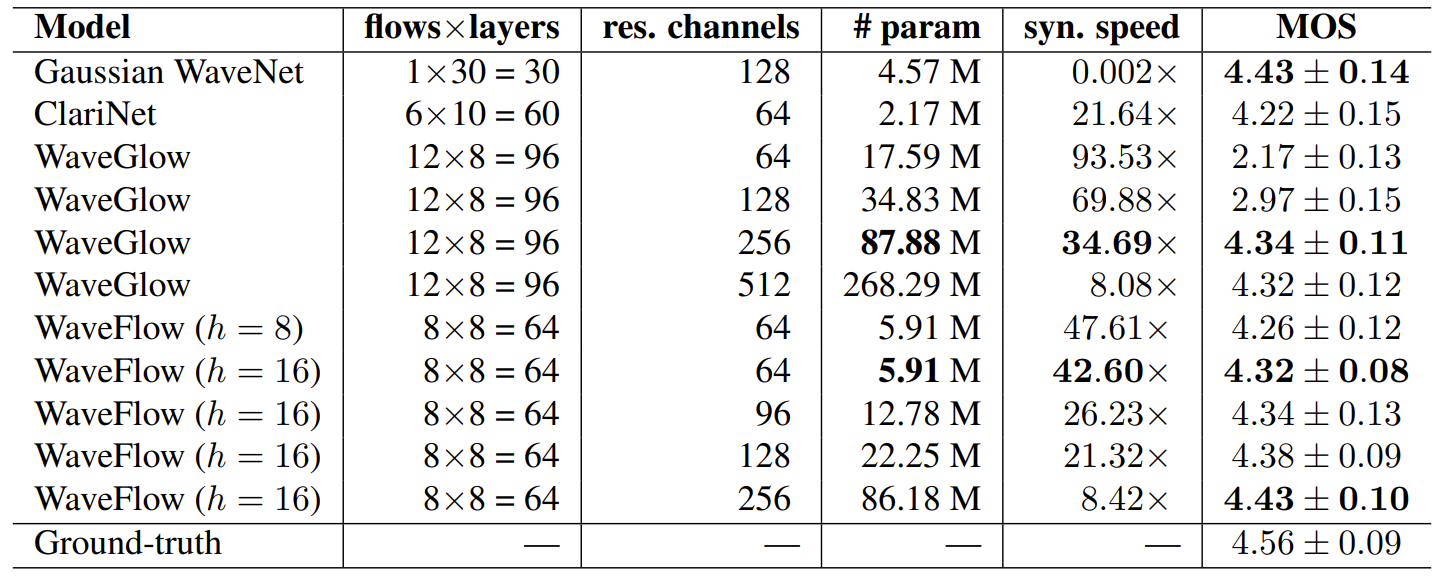
- 특히 test likelihood와 MOS 사이에는 positive correlation이 존재함
- 결과적으로 큰 LL을 가지는 모델은 더 높은 MOS를 달성할 수 있음

- Text-to-Speech 측면에서 DeepVoice3와 결합하여 성능을 확인해 보면, 마찬가지로 WaveFlow가 WaveGlow 보다 우수한 성능을 보임
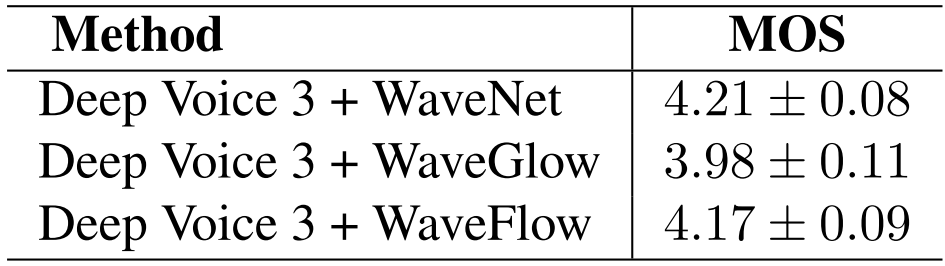
반응형
'Paper > Vocoder' 카테고리의 다른 글
댓글