

티스토리 뷰
Paper/TTS
[Paper 리뷰] Period VITS: Variational Inference with Explicit Pitch Modeling for End-to-End Emotional Speech Synthesis
feVeRin 2024. 4. 3. 11:17반응형
Period VITS: Variational Inference with Explicit Pitch Modeling for End-to-End Emotional Speech Synthesis
- End-to-End 방식은 acoustic model과 vocoder를 개별적으로 training 하는 cascade 방식보다 더 우수한 text-to-speech 성능을 달성할 수 있음
- BUT, dataset에 다양한 prosody나 emotional attribute가 포함되어 있는 경우 audible artifact와 unstable pitch를 생성하는 경우가 많음 - Period VITS
- Unstable pitch 문제를 해결하기 위해 explicit periodicity generator를 사용하는 end-to-end text-to-speech 모델
- Input text로부터 voicing flag, pitch와 같은 prosodic feature를 예측하는 frame pitch predictor를 도입
- 해당 feature로부터 periodicity generator는 waveform decoder가 pitch를 정확하게 reproduce 하도록 sample-level sinusoidal source를 생성
- 최종적으로 전체 모델은 variational inference와 adversarial objective를 활용하여 jointly optimize 됨
- 논문 (ICASSP 2023) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 주로 acoustic model과 vocoder의 개별적인 두 가지 모델로 구성됨
- 이러한 cascade 방식은 두 개의 independent model을 사용하기 때문에 pre-defined feature와 separated optimization으로부터 파생되는 한계점이 존재함
- 이를 해결하기 위해 acoustic, vocoding model을 jointly optimize 하는 fully end-to-end architecture를 활용할 수 있음
- 대표적으로 VITS는 normalizing flow를 사용하는 variational autoencoder (VAE)를 통해 우수한 TTS 성능을 달성함
- 여기서 VAE는 waveform에서 trainable latent acoustic feature를 얻는 데 사용되고, normalizing flow는 hidden text representation을 latent feature처럼 powerful 하게 만드는 역할을 수행 - BUT, VITS를 비롯한 end-to-end 방식은 dataset이 다양한 pronunciation과 prosody를 가지는 emotional speech synthesis에서는 제한적인 성능을 보임
- 특히 unstable pitch contour로 인해 less intelligible 한 음성을 생성하는 경우가 많음
- 이러한 cascade 방식은 두 개의 independent model을 사용하기 때문에 pre-defined feature와 separated optimization으로부터 파생되는 한계점이 존재함
-> 그래서 emotional TTS를 위한 end-to-end 모델인 Period VITS를 제안
- Period VITS
- Target waveform을 생성할 때 sample-level과 pitch-dependent periodicity를 explicit 하게 제공하는 방식
- 구조적으로는 prior encoder와 waveform decoder 2가지 module로써 구성됨
- Prior encoder는 모든 frame에서 prior 분포의 parameter와 prosodic feature를 동시에 생성하는 frame pitch predictor가 있는 frame prior network를 사용함
- 이때 parameter는 normalizing flow를 통해 expressive piror 분포를 학습하는 데 사용되고, pitch/voicing flag와 같은 prosodic feature는 sample-level sinusoidal source signal을 생성하는 데 사용됨 - 이후 decoder에서 periodic source는 HiFi-GAN vocoder의 모든 upsampled representation에 제공되어 target waveform의 pitch stability를 보장함
- Prior encoder는 모든 frame에서 prior 분포의 parameter와 prosodic feature를 동시에 생성하는 frame pitch predictor가 있는 frame prior network를 사용함
- Training process는 variational inference 관점에서 end-to-end 방식으로 전체 모델을 최적화함
< Overall of Period VITS >
- Unstable pitch 문제를 해결하기 위해 explicit periodicity generator를 사용하는 end-to-end TTS 모델
- Pre-define 된 acoustic feature를 사용하는 기존 방식들과는 달리 frame pitch predictor를 통해 auxiliary pitch information으로 guide 되는 optimal latent acoustic feature를 얻을 수 있음
- 해당 feature로부터 periodicity generator는 decoder가 pitch를 정확하게 reproduce 하도록 sample-level sinusoidal source를 생성하고, 이를 통해 Period VITS는 결과적으로 우수한 합성 품질을 달성 가능함
2. Method
- Overview
- Period VITS는 VITS를 기반으로 text에 따라 prior 분포가 condition 되는 VAE를 채택함
- 이때 VAE는 posterior encoder, decoder로 구성되지만 prior 분포는 prior encoder에 의해 모델링 됨
- Posteriror encoder는 input linear spectrogram을 latent acoustic feature로 변환하고, piror encoder는 text를 latent feature로 변환하는 역할
- Decoder는 learned latent feature로부터 waveform을 reconstruction 하는 역할 - 추가적으로 prosodic feature를 represent 하기 위해 latent variable $y$를 도입함
- 이때 생성된 음성의 pitch information을 explicit 하게 모델링하기 위해, VAE latent variable $z$에서 separated source로써 사용함 - Period VITS는 주어진 text $c$에서 waveform $x$의 log-likelihood를 최대화하도록 training 되지만, 이는 일반적으로 intractable 하기 때문에 다음의 marginal likelihood의 lower bound를 최적화함:
(Eq. 1) $\log p(x|c)=\log \iint p(x,z,y|c)dzdy $
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \geq \iint q(z,y|x)\log\frac{p(x,z,y|c)}{q(z,y|x)}dzdy =\iint q(z|x)q(y|x)\log \frac{p(x|z,y)p(z|c)p(y|c)}{q(z|x)q(y|x)}dzdy$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, = \mathbb{E}_{q(z,y|x)}[\log p(x|z,y)]-D_{KL}(q(z|x)||p(z|c))-D_{KL}(q(y|x)||p(y|c))$
- $p$ : generative model 분포, $q$ : $z$와 $y$에 대한 근사 posterior 분포
- $\mathbb{E}$ : expectation operator, $D_{KL}$ : Kullback-Leibler divergence
- 추가적으로 $x$가 주어지면 $z$와 $y$는 conditionally independent 하다고 가정하므로, $q(z,y|x)$는 $q(z|x)q(y|x)$로 factorize 됨 - $x$로부터의 pitch 추출은 deterministic operation이므로, $q(y|x) = \delta (y-y_{gt})$를 정의했을 때 (Eq. 1)의 세 번째 term은 다음과 같이 변환됨:
(Eq. 2) $-\log p(y_{gt}|c)+const.$
- $y_{gt}$ : ground-truth pitch value
- 해당 term은 Fixed unit variance를 가지는 $p(y|c)$에 대한 Gaussian 분포를 가정하여, 예측과 ground-truth 사이의 $L_{2}$ norm을 최소화함으로써 최적화됨 - 결과적으로 (Eq. 1)의 3가지 term은 각각 VAE의 wave reconstruction loss $L_{recorn}$, prior/posteriror 분포 간의 KL-divergence loss $L_{kl}$, text로부터의 pitch reconstruction loss $L_{pitch}$로 볼 수 있음
- 여기서는 $L_{recon}$에 대해 mel-spectrogram loss를 사용
- 이때 VAE는 posterior encoder, decoder로 구성되지만 prior 분포는 prior encoder에 의해 모델링 됨

- Prior Encoder
- Period VITS는 일반적인 TTS 뿐만 아니라 emotional dataset에서의 TTS도 목표로 하기 때문에, prior encoder에 의해 모델링 된 prior 분포는 동일한 phoneme에 대해 다양한 acoustic variation을 표현할 수 있어야 함
- 이를 위해 VISinger에서 제안된 frame prior network를 채택하여, phoneme-level prior 분포를 frame-level fine-grained 분포로 expand 함
- 이러한 방식은 가창 음성 합성뿐만 아니라 emotional TTS에서도 pronunciation을 stablize 할 수 있는 것으로 나타남 - 추가적으로 frame-level prosodic feature (fundamental frequency $F_{0}$, voicing flag $v$)를 예측하기 위해 frame piror network의 hidden layer에서 frame pitch predictor를 도입함
- 이는 이후 periodicity generator의 input으로 사용됨
- 이때 해당 frame-level prosodic feature는 다음의 $L_{2}$ norm을 통해 최적화됨:
(Eq. 3) $L_{pitch}= || \log F_{0}-\log \hat{F}_{0} ||_{2}+|| v-\hat{v}||_{2}$ - VITS와 마찬가지로 모델링 성능을 향상하기 위해 normalizing flow $f$를 사용하여 prior 분포는 augmented 됨:
(Eq. 4) $p(z|c)=N(f(z);\mu(c),\sigma(c))\left| \det \frac{\partial f(z)}{\partial z}\right|$
- $\mu(c), \sigma(c)$ : 각각 text representation에서 계산된 trainable 평균, 분산 parameter
- 이를 위해 VISinger에서 제안된 frame prior network를 채택하여, phoneme-level prior 분포를 frame-level fine-grained 분포로 expand 함
- Decoder with Periodicity Generator
- Generative Adversarial Network (GAN) 기반의 vocoder는 일반적으로 pitch와 periodicity를 추정할 수 없으므로, acoustic feature로부터 waveform을 reconstruct 할 때 artifact가 생성됨
- 특히 이러한 artifact는 emotion과 같이 pitch variacne가 큰 dataset에 대해 training 하는 경우, end-to-end TTS에서도 발생함
- 따라서 이 문제를 해결하기 위해 sine-based source signal을 사용하여 waveform의 periodic component를 explicit 하게 모델링함
- 이때 sine-based source signal은 sample-level feature인 반면, VITS의 HiFi-GAN vocoder는 frame-level acoustic feature에서 동작하므로 end-to-end architecture를 위해서는 수정이 필요 - 결과적으로 Period VITS는 pitch-controllable HiFi-GAN-based vocoder architecture를 구성함
- 해당 architecture의 핵심은 upsampled frame-level feature와 resolution을 일치시키기 위해 sample-level pitch input에 down-sampling layer를 적용하는 것
- 이러한 sample-level periodic source를 생성하는 module을 periodicity generator라고 함
- 이때 module의 input으로써 voicing flag와 Gaussian noise를 sinusoidal source와 함께 사용함 - 여기서 아래 그림과 같이 pre-conv module의 sample-level output은 upsampled feature에 directly add 되지 않음
- Upsampled feature에 directly add 되는 경우 sample 품질이 저하되기 때문
- 해당 architecture의 핵심은 upsampled frame-level feature와 resolution을 일치시키기 위해 sample-level pitch input에 down-sampling layer를 적용하는 것
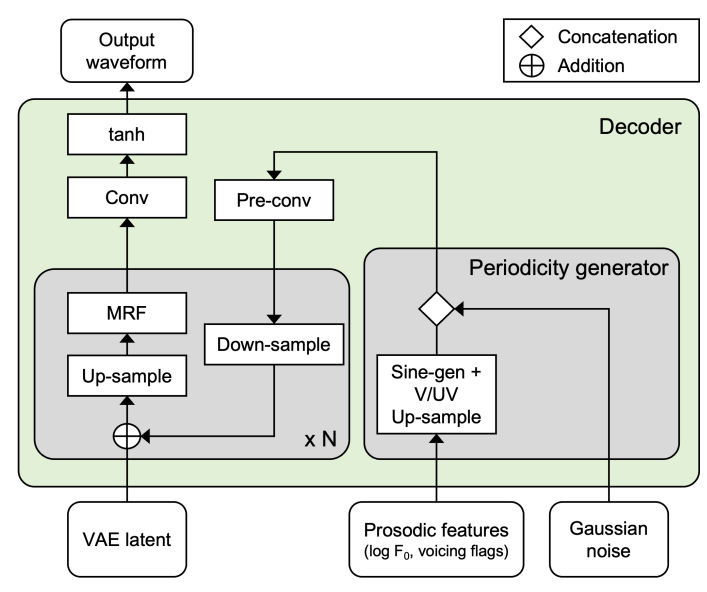
- Training Criteria
- 앞선 loss들을 기반으로 adversarial loss $L_{adv}$와 feature matching loss $L_{fm}$를 추가하여 waveform에 대한 GAN을 training 함
- 이때 $L_{2}$ duration loss는 supervised duration model을 training 하는 데에도 사용됨
- 결과적으로 Period VITS에 대한 final loss $L_{total}$은:
(Eq. 5) $L_{total}=L_{recon}+L_{kl}+L_{pitch}+L_{dur}+L_{adv}+L_{fm}$
3. Experiments
- Settings
- Dataset : Japanese Speech Dataset (internal)
- Comparisons : VITS
- FPN-VITS : VITS에 Frame Prior Network를 추가한 모델
- CAT-P-VITS : frame-level $F_{0}$과 voicing flag를 concatenate 하는 모델
- Sine-P-VITS : periodicity generator에서 voicing flag와 Gaussian noise를 생략한 모델
- FS2+P-HiFi-GAN : FastSpeech2 + HiFi-GAN

- Results
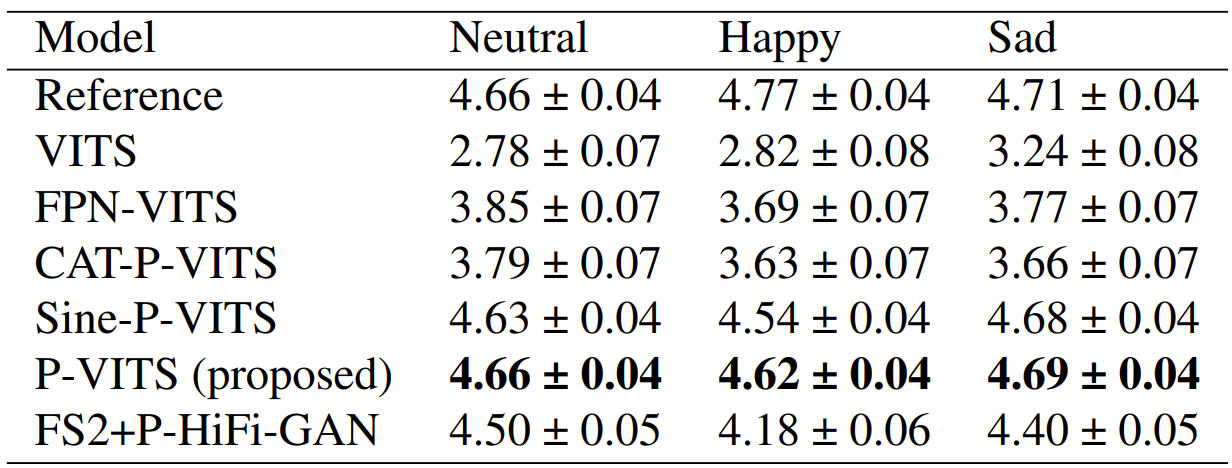
- MOS 측면에서 제안된 Period VITS (P-VITS)가 가장 우수한 성능을 보임
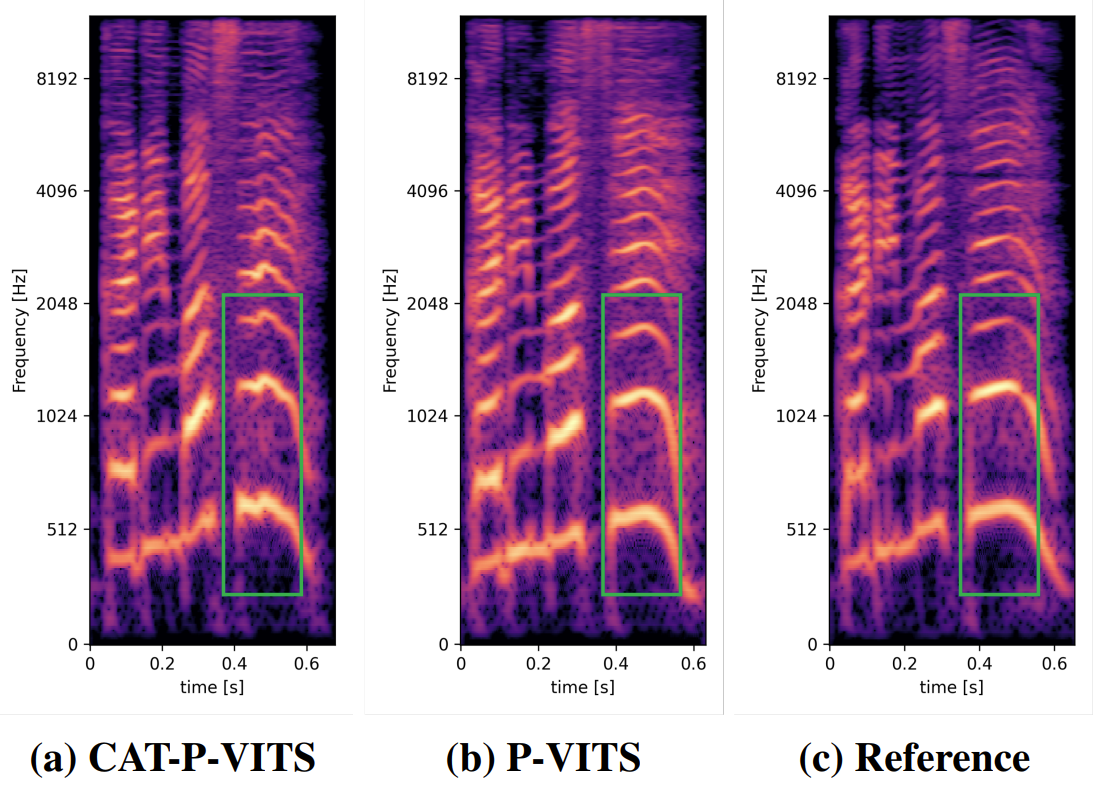
- 합성된 sample의 mel-spectrogram을 확인해 보면
- (a)에서는 utterance의 끝 부분에서 swaying pitch contour가 나타남 (초록색 박스 부분)
- 그에 비해 Period VITS (b)에서는 continuous 하고 reference (c)와 비슷한 contour가 나타남
반응형
'Paper > TTS' 카테고리의 다른 글
댓글