

티스토리 뷰
Paper/Vocoder
[Paper 리뷰] Parallel WaveGAN: A Fast Waveform Generation Model Based on Generative Adversarial Networks with Multi-Resolution Spectrogram
feVeRin 2024. 4. 1. 09:32반응형
Parallel WaveGAN: A Fast Waveform Generation Model Based on Generative Adversarial Networks with Multi-Resolution Spectrogram
- Generative Adversarial Network를 사용하여 distillation 과정이 필요 없는 vocoder를 구성할 수 있음
- Parallel WaveGAN
- Waveform의 time-frequency 분포를 효과적으로 capture 하는 multi-resolution spectrogram loss와 adversarial loss를 jointly optimize 하여 non-autoregressive WaveNet을 training 함
- 기존의 teacher-student framework을 통한 distillation 의존성을 제거하여 간단한 학습을 지원하고, compact 한 architecture로 high-fidelity의 음성을 생성
- 논문 (ICASSP 2020) : Paper Link
1. Introduction
- Text-to-Speech (TTS)에서 WaveNet과 같은 autoregressive 모델은 우수한 합성 성능을 보이고 있음
- BUT, autoregressive nature로 인해 추론 속도가 상당히 느리다는 한계점이 있음
- 이때 추론 속도 문제를 극복하기 위해 teacher-student framework를 기반으로 하는 방식을 고려할 수 있음
- BUT, well-trained teacher 모델이 필요하고 density distillation 과정이 복잡해 최적화가 어렵다는 단점이 있음 - 한편으로 Generative Adversarial Network (GAN)는 훨씬 간단한 parallel waveform 생성을 지원함
-> 그래서 GAN framework를 사용하여 distillation 의존성을 제거하고, 빠르고 효과적인 합성을 지원하는 Parallel WaveGAN을 제안
- Parallel WaveGAN
- Parallel WaveGAN은 teacher-student training과 같은 기존의 distillation 방식을 전혀 사용하지 않음
- 대신 모델이 time-frequency 분포를 효과적으로 capture 하도록 multi-resolution STFT loss와 adversarial loss를 결합하여 non-autoregressive WaveNet을 training 함
- 이를 통해 기존 보다 더 간단한 training 과정과 자연스러운 결과를 얻을 수 있음
< Overall of Parallel WaveGAN >
- Multi-resolution STFT loss와 waveform-domain adversarial loss의 joint training 방식을 제시
- Distillation에 대한 의존성을 제거하여 학습, 추론 시간을 크게 절감함
- 결과적으로 Transformer-based TTS 모델에 Parallel WaveGAN을 적용하여 우수한 합성 품질을 달성
2. Method
- Parallel Waveform Generation based on GAN
- GAN은 generator $G$와 discriminator $D$로 구성되는 생성 모델
- Parallel WaveGAN에서는 mel-spectrogram을 condition으로 하는 WaveNet-based 모델을 generator로 사용
- Input noise를 output waveform으로 parallel 하게 변환하는 역할 - 이때 generator는 기존 WaveNet과 비교하여 아래의 차이점을 가짐:
- Causal convolution 대신 non-causal convolution을 사용
- Input은 Gaussian 분포에서 얻어지는 random noise
- 학습, 추론 모두에서 non-autoregressive 하게 동작함
- 결과적으로 generator는 realistic sample을 생성하여 discriminator를 deceive 하도록 동작하고, 다음의 adversarial loss $L_{adv}$를 최소화하는 것으로 학습됨:
(Eq. 1) $L_{adv}(G,D)=\mathbb{E}_{z\sim N(0,I)}[(1-D(G(z)))^{2}]$
- $z$ : input white noise - 한편으로 discriminator는 다음의 objective를 사용하여 생성된 sample과 ground-truth를 올바르게 classify 하도록 학습됨:
(Eq. 2) $L_{D}(G,D)=\mathbb{E}_{x\sim p_{data}}[(1-D(x))^{2}]+\mathbb{E}_{z\sim N(0,I)}[D(G(z))^{2}]$
- $x, p_{data}$ : target waveform과 해당 분포
- Parallel WaveGAN에서는 mel-spectrogram을 condition으로 하는 WaveNet-based 모델을 generator로 사용
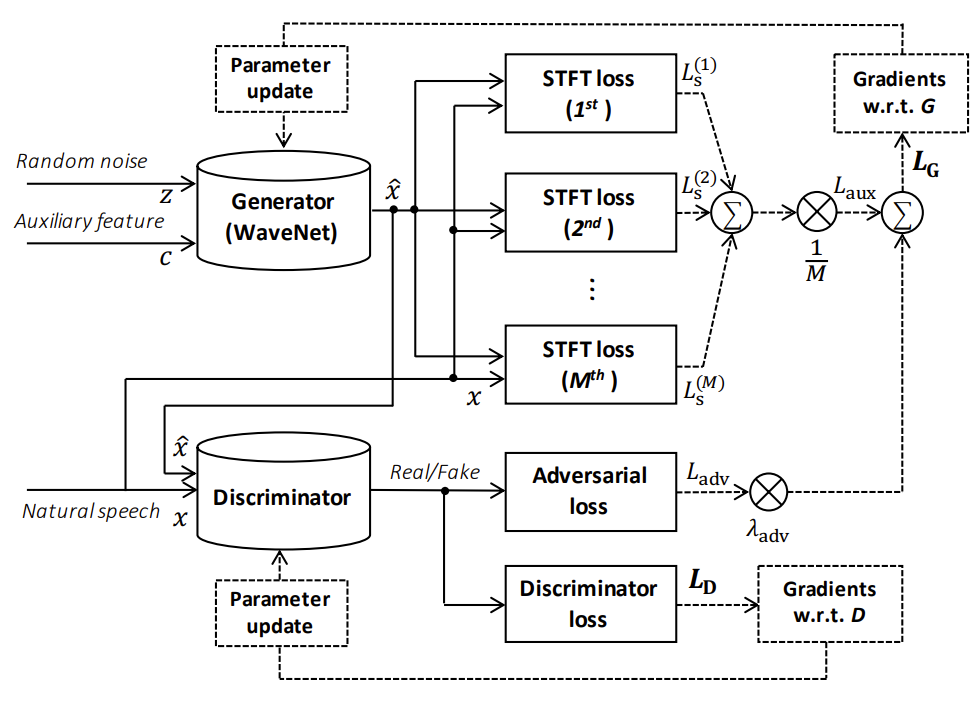
- Multi-Resolution STFT Auxiliary Loss
- Adversarial training의 stability를 향상하기 위해, multi-resolution STFT loss를 도입함
- 먼저 single STFT loss를 다음과 같이 정의하자:
(Eq. 3) $L_{s}(G)=\mathbb{E}_{z\sim p(z),x\sim p_{data}}[L_{sc}(x,\hat{x})+L_{mag}(x,\hat{x})]$
- $\hat{x}$ : generated sample로써 $G(z)$와 동일 - 이때 $L_{sc}, L_{mag}$는 각각 spectral convergence, log STFT magnitude loss로써:
(Eq. 4) $L_{sc}(x,\hat{x})=\frac{||\,\,|STFT(x)|-|STFT(\hat{x})|\,\,||_{F}}{||\,\, |STFT(x)| \,\, ||_{F}}$
(Eq. 5) $L_{mag}(x,\hat{x})=\frac{1}{N}|| \,\log |STFT(x)|-\log |STFT(\hat{x})| \, ||_{1}$
- $|| \cdot ||_{F}, || \cdot ||_{1}$ : 각각 Frobenius, $L_{1}$ norm
- $| STFT(\cdot) |$ : STFT magnitude, $N$ : magnitude의 element 수 - Multi-resolution STFT loss는 다양한 analysis parameter (FFT size, Window size, Frame shift)를 사용한 STFT loss들의 합과 같음
- 즉, $M$을 STFT loss의 개수라고 했을 때, multi-resolution STFT auxiliary loss $L_{aux}$는:
(Eq. 6) $L_{aux}(G)=\frac{1}{M}\sum_{m=1}^{M}L_{s}^{(m)}(G)$ - STFT-based time-frequency representation에는 time과 frequency resolution 간의 trade-off가 존재함
- e.g.) Window size를 늘리면 temporal resolution이 감소하고 frequency resolution이 높아짐 - 따라서 multiple STFT loss를 다양한 analysis parameter에 적용함으로써 generator는 음성의 time-frequency characteristic을 더 효과적으로 학습할 수 있음
- 추가적으로 generator가 fixed STFT representation에 overfit 되어 sub-optimal 한 성능을 초래하는 것을 방지 가능
- 즉, $M$을 STFT loss의 개수라고 했을 때, multi-resolution STFT auxiliary loss $L_{aux}$는:
- 결과적으로 Parallel WaveGAN의 final loss function은 multi-resolution STFT와 adversarial loss의 linear combination으로 정의됨:
(Eq. 7) $L_{G}(G,D)=L_{aux}(G)+\lambda_{adv}L_{adv}(G,D)$
- $\lambda_{adv}$ : balancing hyperparameter
- 먼저 single STFT loss를 다음과 같이 정의하자:

- Model Details
- Parallel WaveGAN은 exponential 하게 증가하는 dilation cycle을 가지는 dilated residual convolution block으로 구성됨
- Residual channel 수는 64, convolution filter size는 3
- Discriminator는 LeakyReLU activation을 사용한 non-causal diated 1D convolution으로 구성됨
- 추가적으로 discriminator와 generator 모두에 대해 모든 convolution layer에 weight normalization을 적용
3. Experiments
- Settings
- Dataset : Japanese speech dataset
- Comparisons : WaveNet, ClariNet
- Results
- MOS와 추론 속도 측면에서 비교해 보면
- Multi-resolution STFT loss를 사용한 모델은 기존의 single STFT loss 보다 더 높은 MOS 결과를 보임
- Multi-resolution STFT loss가 음성 signal의 time-frequency characteristic을 효과적으로 capture 하기 때문 - 결과적으로 제안된 Parallel WaveGAN은 4.06 MOS로 우수한 합성 품질을 보임
- ClariNet과 비교하여 MOS 품질은 다소 떨어지지만 Paralle WaveGAN은 합성 속도 측면에서 1.96배 더 빠르게 생성이 가능하다는 장점이 있음
- Multi-resolution STFT loss를 사용한 모델은 기존의 single STFT loss 보다 더 높은 MOS 결과를 보임
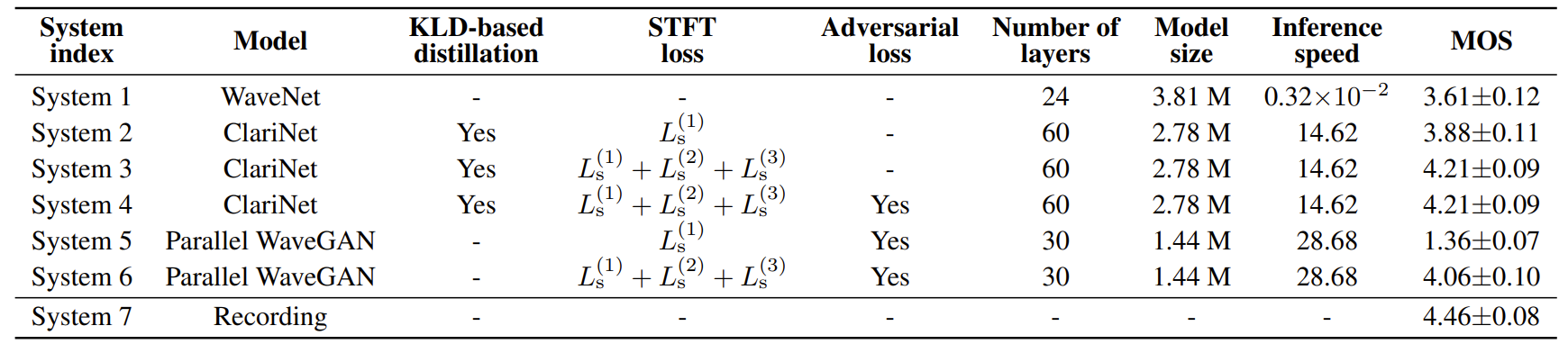
- 특히 Parallel WaveGAN은 density distillation과 같은 복잡한 과정이 필요하지 않기 때문에, 최적의 모델을 학습하는데 2.8일 밖에 걸리지 않음
- 이는 WaveNet, ClariNet 보다 2.64배, 4.82배 빠른 학습 속도

- 추가적으로 제안된 Parallel WaveGAN을 TTS 모델에 적용했을 때도 가장 우수한 합성 품질을 보임

반응형
'Paper > Vocoder' 카테고리의 다른 글
댓글