

티스토리 뷰
Paper/Vocoder
[Paper 리뷰] Universal MelGAN: A Robust Neural Vocoder for High-Fidelity Waveform Generation in Multiple Domains
feVeRin 2024. 4. 17. 10:05반응형
Universal MelGAN: A Robust Neural Vocoder for High-Fidelity Waveform Generation in Multiple Domains
- 여러 domain에서 high-fidelity의 음성을 합성할 수 있는 vocoder가 필요함
- Universal MelGAN
- MelGAN-based structure에 multi-resolution spectrogram discriminator를 추가하여 생성된 waveform의 spectral resolution을 향상
- 이를 통해 large footprint 모델의 high-frequency band에서의 over-smoothing 문제를 방지
- 논문 (ICASSP 2021) : Paper Link
1. Introduction
- 최근의 neural vocoder는 single speaker utterance로 train 되어 우수한 합성 속도와 audio fidelity를 달성함
- BUT, speaker, language, expressive utternace와 같은 다양한 domain에서 자연스러운 음성을 합성하는 것에는 한계가 있음
- 따라서 input이 training 중에 학습되었는지, out-of-domain 인지에 관계없이 다양한 domain에서 고품질의 음성을 합성할 수 있는 universal vocoder가 필요함 - 대표적으로 MelGAN은 Generative Adversarial Network (GAN)을 기반으로 한 lightweight, robust vocoder임
- 이때 multi-scale discriminator를 활용해 unvoiced, breathy speech segment에서 발생하는 metallic sound를 완화하여 우수한 품질을 달성
- BUT, MelGAN은 multiple speaker learning에는 효율적이지 않고, non-sharp spectrogram에 대해 종종 over-smoothing 문제가 발생함
- BUT, speaker, language, expressive utternace와 같은 다양한 domain에서 자연스러운 음성을 합성하는 것에는 한계가 있음
-> 그래서 MelGAN의 품질을 개선하고 universal vocoder로 확장한 Universal MelGAN을 제안
- Universal MelGAN
- 기존 MelGAN의 over-smoothing 문제를 multi-resolution spectrogram discriminator 도입을 통해 frequency domain에서 해결
- Multi-scale discriminator는 waveform과 spectrogram을 discriminate 하여 fine-grained spectrogram을 예측하도록 함
- 기존 MelGAN의 over-smoothing 문제를 multi-resolution spectrogram discriminator 도입을 통해 frequency domain에서 해결
< Overall of Universal MelGAN >
- MelGAN-based structure에 multi-resolution spectrogram discriminator를 추가하여 생성된 waveform의 spectral resolution을 향상
- 이를 통해 기존 high frequency band에서의 over-smoothing 문제를 방지
- 결과적으로 unseen speaker, emotion, language 등 다양한 domain에서 우수한 합성 품질을 달성함
2. Method
- Full-Band MelGAN (FB-MelGAN)
- 논문에서는 FB-MelGAN을 baseline으로 사용함
- FB-MelGAN은 generator pre-training, residual stack의 receptive field 증가, multi-resolution STFT loss 등을 사용하여 더 나은 fidelity와 training stability를 보장함
- 먼저 multi-resolution STFT loss는 다양한 STFT parameter set으로 계산된 여러 spectrogram loss의 합으로써:
(Eq. 1) $\mathcal{L}_{sc}^{m}(x, \hat{x})=\frac{\left|\left| \, |\mathrm{STFT}_{m}(x)|-|\mathrm{STFT}_{m}(\hat{x})|\, \right|\right|_{F}}{\left|\left|\,|\mathrm{STFT}_{m}(x)|\, \right|\right|_{F}}$
(Eq. 2) $\mathcal{L}_{mag}^{m}(x,\hat{x})=\frac{1}{N}|| \log |\mathrm{STFT}_{m}(x)|-\log|\mathrm{STFT}_{m}(\hat{x})|\,||_{1}$
(Eq. 3) $\mathcal{L}_{aux}(G)=\frac{1}{M}\sum_{m=1}^{M}\mathbb{E}_{x,\hat{x}}\left[ \mathcal{L}_{sc}^{m}(x,\hat{x})+\mathcal{L}_{mag}^{m}(x,\hat{x})\right]$
- $\mathcal{L}^{m}_{sc}(\cdot,\cdot)$ : spectral convergence loss, $\mathcal{L}^{m}_{mag}(\cdot, \cdot)$ : log STFT magnitude loss
- $||\cdot||_{F}$ : Frobenius norm, $||\cdot||_{1}$ : $L1$ norm, $M$ : STFT parameter set 수, $N$ : STFT magnitude의 element 수
- $|\mathrm{STFT}_{m}(\cdot)|$ : $m$-th STFT parameter set의 STFT magnitude - Loss는 generator $G$를 사용하여 real data $x$와 예측 data $\hat{x} = G(c)$ 간의 distance를 최소화 하는데 사용됨
- $c$ : mel-spectrogram - 결과적으로 auxiliary loss를 포함한 overall objective는:
(Eq. 4) $\mathcal{L}_{G}(G,D)=\mathcal{L}_{aux}(G)+\frac{\lambda}{K}\sum_{k=1}^{K}\mathbb{E}_{\hat{x}}\left[(D_{k}(\hat{x})-1)^{2}\right]$
(Eq. 5) $\mathcal{L}_{D}(G,D)=\frac{1}{K}\sum_{k=1}^{K}\left(\mathbb{E}_{x}\left[(D_{k}(x)-1)^{2}\right]+\mathbb{E}_{\hat{x}}[D_{k}(\hat{x})^{2}]\right)$
- $K$ : discriminator의 수, $\lambda$ : balancing parameter
- FB-MelGAN은 generator pre-training, residual stack의 receptive field 증가, multi-resolution STFT loss 등을 사용하여 더 나은 fidelity와 training stability를 보장함

- Universal MelGAN: Improvements
- 여러 speaker의 utterance에 대해 앞선 FB-MelGAN을 training 하면, single speaker의 utterance로 training 한 결과보다 낮은 품질의 음성을 생성함
- FB-MelGAN의 multi-scale discriminator는 해당 품질 저하를 완화하기 위해 사용되지만, multi-speaker training에서는 제대로 동작하지 않음
- 결과적으로 unvoiced, breathy segment에서 metallic sound를 발생시킴 - 따라서 효과적인 multi-speaker 학습을 위해 Universal MelGAN은,
- Generator의 hidden channel size를 4배로 늘리고, 각 residual stack의 마지막 layer에 Gated Activation Unit (GAU)를 추가함
- 이러한 non-linearity의 확장을 통해 multi-speaker에서도 우수한 품질을 달성할 수 있음 - 이때 multi-speaker 품질 문제는 해결했지만 high-frequency band에서 artifact와 over-smoothing 문제는 여전히 남아있음
- Temporal domain의 discriminator는 frequency domain의 문제 해결에는 충분하지 않기 때문 - 이러한 high frequency band의 over-smoothing 문제 해결을 위해, Universal MelGAN에 multi-resolution spectrogram discriminator를 추가적으로 도입함
- Generator의 hidden channel size를 4배로 늘리고, 각 residual stack의 마지막 layer에 Gated Activation Unit (GAU)를 추가함
- 결과적으로 Universal MelGAN은 다음과 같이 업데이트됨:
(Eq. 6) $\mathcal{L}'_{G}(G,D)=\mathcal{L}_{aux}(G)+\frac{\lambda}{K+M}\left(\sum_{k=1}^{K}\mathbb{E}_{\hat{x}}[(D_{k}(\hat{x})-1)^{2}]+\sum_{m=1}^{M}\mathbb{E}_{\hat{x}}[(D_{m}^{s}(|\mathrm{STFT}_{m}(\hat{x})|)-1)^{2}]\right)$
(Eq. 7) $\mathcal{L}'_{D}(G,D)=\frac{1}{K+M}\left( \sum_{k=1}^{K}(\mathbb{E}_{x}[(D_{k}(x)-1)^{2}]+\mathbb{E}_{\hat{x}}[D_{k}(\hat{x})^{2}]) \right.$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \left. + \sum_{m=1}^{M}(\mathbb{E}_{x}[(D_{m}^{s}(|\mathrm{STFT}_{m}(x)|)-1)^{2}] +\mathbb{E}_{\hat{x}}[D_{m}^{s}(|\mathrm{STFT}_{m}(\hat{x})|)^{2}] )\right)$
- $D_{m}^{s}$ : multi-resolution STFT module에 attach 된 spectrogram discriminator
- 각 $m$-th model은 $m$-th STFT loss를 최소화하기 위해 이전에 계산된 spectrogram loss를 사용함 - 구조적으로 large footprint generator에 의해 생성된 waveform은 waveform, spectrogram 모두에 대해 여러 scale로 discriminate 됨
- 실제로 아래 그림과 같이 생성된 waveform의 high-frequency band에 대한 mel-spectorgram을 확인해 보면,
- Sizeup과 GAU를 적용하면 기존 FB-MelGAN 보다 향상된 resolution을 얻을 수 있지만, 9kHz 이상의 high band에서 over-smoothing이 발생하는 것으로 나타남
- 반면 Universal MelGAN에서는 빨간색 박스와 같이 해당 문제를 완화할 수 있고, 노란색 박스와 같이 harmonic shape를 생성할 수도 있음
- Sizeup과 GAU를 적용하면 기존 FB-MelGAN 보다 향상된 resolution을 얻을 수 있지만, 9kHz 이상의 high band에서 over-smoothing이 발생하는 것으로 나타남
- FB-MelGAN의 multi-scale discriminator는 해당 품질 저하를 완화하기 위해 사용되지만, multi-speaker training에서는 제대로 동작하지 않음

3. Experiments
- Settings
- Dataset : Korean Speech Dataset (internal), LJSpeech, LibriTTS, Blizzard, CSS
- Comparisons : WaveGlow, WaveRNN, FB-MelGAN

- Results
- Seen Speakers
- 제안된 Universal MelGAN은 다른 모델들보다 우수한 성능을 보임
- 즉, Universal MelGAN은 training 중에 speaker의 utterance가 자주 사용되었는지 여부에 관계없이 high-fidelity의 음성을 합성할 수 있는 robustness를 보임
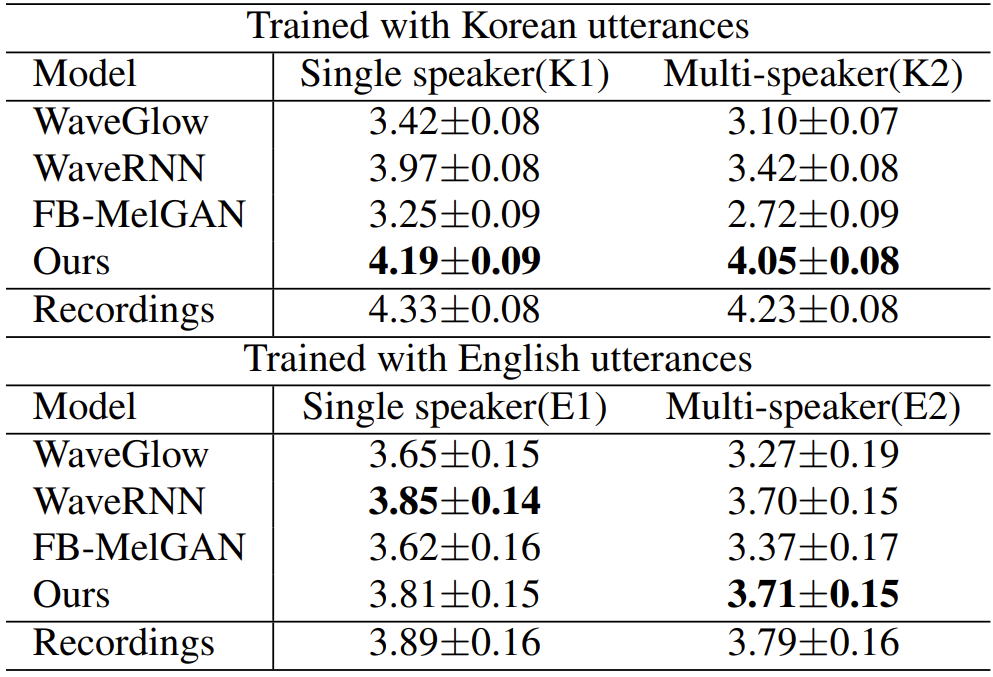
- Unseen Domains: Speaker, Emotion, Language
- Unseen domain에 대해서도 Universal MelGAN이 가장 우수한 성능을 달성함
- 특히 대부분의 모델은 speaker set에 비해 emotion, language set에서는 성능 저하를 보이는데, Universal MelGAN은 거의 일정하게 성능을 유지함

- Multi-Speaker Text-to-Speech
- JDI-T acoustic model을 사용하여 multi-speaker text-to-speech로 확장해 보면
- Universal MelGAN은 0.028 RTF의 속도로 다른 모델들보다 더 높은 MOS를 달성함

반응형
'Paper > Vocoder' 카테고리의 다른 글
댓글