

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] ScoreDec: A Phase-Preserving High-Fidelity Audio Codec with a Generalized Score-based Diffusion Post-Filter
feVeRin 2024. 6. 21. 09:55반응형
ScoreDec: A Phase-Preserving High-Fidelity Audio Codec with a Generalized Score-based Diffusion Post-Filter
- Waveform-domain end-to-end neural codec은 low-bitrate의 coding이 가능하지만 여전히 natural audio와의 품질 차이가 존재함
- 해당 neural codec의 성능을 향상하기 위해서는 GAN training이 필요하지만, original phase information preserving을 방해한다는 문제가 있음
- ScoreDec
- GAN training에서 original phase preserving을 위해, complex spectral domain에서 score-based diffusion post-filter (SPF)를 도입
- 이후 기존의 AudioDec과 SPF를 결합한 다음 spectral loss와 score-matching loss로 training 함
- 논문 (ICASSP 2024) : Paper Link
1. Introduction
- Audio signal은 high-temporal resolution을 가짐
- 이때 audio codec은 quasi-periodic nature로 인한 redundancy를 기반으로 low-bitrate의 compact code를 생성하고, 해당 code를 waveform으로 recover 하기 위해 decoder를 활용함
- 최근에는 end-to-end (E2E) neural audio codec이 우수한 성능을 보이고 있음
- Neural codec은 3~8kpbs의 매우 낮은 low-bitrate로 compression이 가능하지만 여전히 quality saturation, tractability, phase preservation 측면에서 한계가 있음
- 특히 neural codec은 fixed network architecture로 인해 code의 동일한 temporal resolution을 유지하면서 서로 다른 codebook 수를 채택하여 bitrate를 control 함
- 결과적으로 해당 방식은 digital signal processing (DSP) 기반의 codec보다 낮은 성능을 보이고, quality saturation point에 빠르게 도달하게 만듦 - 추가적으로 neural codec은 high-fidelity reconstruction을 위해 Generative Adversarial Network (GAN) training에 의존함
- BUT, discriminator에 대한 indirect objective와 explict phase modeling의 부족으로 인해 generator는 original phase 대신 plausible phase를 생성하는 경향이 있음
- 결과적으로 broken phase relationship으로 인해 binaural audio와 ambient sound field coding에서 modeling error가 발생하게 됨
- 한편으로 speech enhancement를 위한 score-based generative model (SGMSE)은 complex spectral restoration을 explicit 하게 처리하여 original phase를 효과적으로 recover 할 수 있음
- 이때 audio codec은 quasi-periodic nature로 인한 redundancy를 기반으로 low-bitrate의 compact code를 생성하고, 해당 code를 waveform으로 recover 하기 위해 decoder를 활용함
-> 그래서 neural codec의 phase reconstruction 문제를 해결하기 위해 SGSME의 precise phase modeling을 채택한 ScoreDec을 제안
- ScoreDec
- AudioDec의 complex spectral domain에 대한 score-based diffusion post-filter (SPF)를 도입
- 이를 통해 high-fidelity의 speech reconstruction을 지원하고 original phase information을 효과적으로 presrving 함
< Overall of ScoreDec >
- Audio codec의 품질을 향상할 수 있는 score-based diffusion post-filter를 도입
- 까다로운 adversarial training 대신 interpretable metric loss 만으로 전체 모델에 대한 training을 지원
- 결과적으로 정확한 phase preserving과 뛰어난 waveform reconstruction 성능을 달성
2. Background
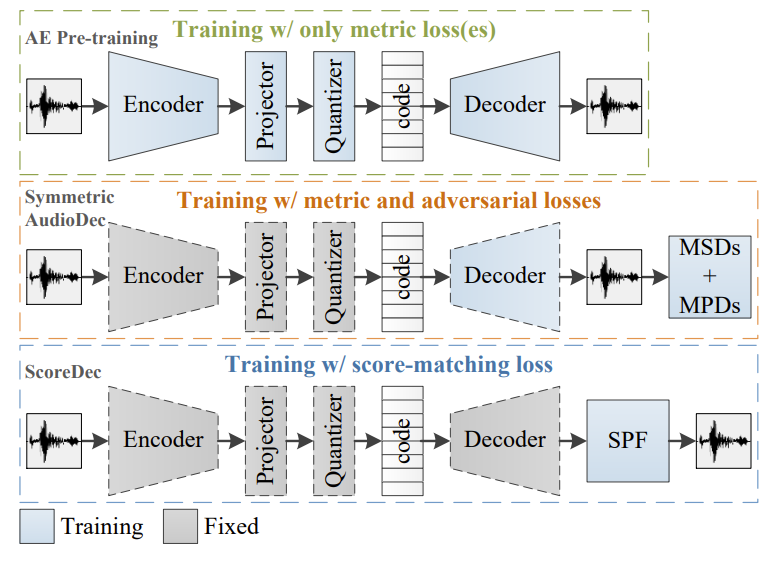
- AudioDec
- AudioDec은 아래 그림과 같이 encoder, quantizer, decoder로 구성되고, waveform domain에서 E2E training 됨
- 이때 GAN training을 통해 waveform detail을 fine-tuning 하는 decoder를 개선함
- AudioDec은 training efficiency를 향상하기 위해, two-stage training을 채택함
- First stage에서는 mel-loss와 같은 metric loss만을 사용하여 전체 autoencoder를 training 함
- Second stage에서는 encoder를 fix 하고, decoder와 mutli-scale/multi-period discriminator (MSD/MPD)를 adversarially training 함
- 이때 modularized architecture를 활용해 lightweight AudioDec decoder를 HiFi-GAN 같은 powerful vocoder로 대체할 수도 있음
- 논문에서는 symmetric encoder-decoder architecture를 가지는 AudioDec을 기반으로 함
- Score-based Generative Model for Speech Enhancement
- SGSME는 unknown clean speech distribution을 simple normal distribution으로 변환하는 forward process와 tractable distribution을 sampling 하여 estimated clean speech를 생성하는 reverse process로 구성됨
- Initial state로 clean speech $\mathbf{x}_{0}$, 해당 noisy speech $\mathbf{y}$, diffusion time step $t\in [0,T]$, standard Wiener process $\mathbf{w}$가 주어진다고 하자
- 그러면 SGSME의 stochastic forward process는 Ornstein-Uhlenbeck Variance Exploding (OUVE) stochastic differential equation (SDE)로 정의됨:
(Eq. 1) $d\mathbf{x}_{t}=\underset{:=f(\mathbf{x}_{t},\mathbf{y})}{\underbrace{\gamma(\mathbf{y}-\mathbf{x}_{t})}}dt+\underset{:=g(t)}{\underbrace{\left[\sigma_{\min}\left(\frac{\sigma_{\max}}{\sigma_{\min}}\right)^{t}\sqrt{2\log \left(\frac{\sigma_{\max}}{\sigma_{\min}}\right)}\right]}}d\mathbf{w}$
- $f(\mathbf{x}_{t},\mathbf{y})$ : drift function, $g(t)$ : diffusion coefficient
- $\gamma, (\sigma_{\min}, \sigma_{\max})$ : 각 time step에서 process의 stiffness와 Gaussian noise의 injection 양을 control 하는 constant hyperparameter - 한편으로 reverse SDE는:
(Eq. 2) $d\mathbf{x}_{t}=[-f(\mathbf{x}_{t},\mathbf{y})+g(t)^{2}\nabla_{\mathbf{x}_{t}}\log p_{t}(\mathbf{x}_{t})]dt+g(t)d\bar{\mathbf{w}}$
- 여기서 $\mathbf{x}_{t}$에 대한 logarithm distribution의 gradient $\nabla_{\mathbf{x}_{t}}\log p_{t}(\mathbf{x}_{t})$를 score function이라고 함
- $\bar{\mathbf{w}}$ : time-reversed Wiener process
- 그러면 SGSME의 stochastic forward process는 Ornstein-Uhlenbeck Variance Exploding (OUVE) stochastic differential equation (SDE)로 정의됨:
- (Eq. 1)은 Gaussian process이고, state $\mathbf{x}_{t}$의 distribution은 normal distribution으로써,
- 평균은 다음과 같은 closed-form solution을 가짐:
(Eq. 3) $\mu(\mathbf{x}_{0},\mathbf{y},t)=e^{-\gamma t}\mathbf{x}_{0}+(1-e^{-\gamma t})\mathbf{y}$ - 분산도 마찬가지로 closed-form solution으로 얻어짐:
(Eq. 4) $\sigma(t)^{2}=\frac{\sigma_{\min}^{2}\left(\left(\frac{\sigma_{\max}}{\sigma_{\min}}\right)^{2t}-e^{-2\gamma t}\right)\log\left(\frac{\sigma_{\max}}{\sigma_{\min}}\right)}{\gamma+\log \left(\frac{\sigma_{\max}}{\sigma_{\min}}\right)}$
- 평균은 다음과 같은 closed-form solution을 가짐:
- 결과적으로 score function은:
(Eq. 5) $\nabla_{\mathbf{x}_{t}}\log p_{t}(\mathbf{x}_{t}|\mathbf{x}_{0},\mathbf{y})=-\frac{\mathbf{x}_{t}-\mu(\mathbf{x}_{0},\mathbf{y},t)}{\sigma(t)^{2}}$ - Training stage에서는 주어진 clean-noisy pair $(\mathbf{x}_{0}, \mathbf{y})$를 기반으로 arbitrary $\mathbf{x}_{t}$를 사용할 수 있지만, 추론 시에는 clean speech $\mathbf{x}_{0}$는 agnoistic 함
- 따라서 reverse process를 사용하여 noisy speech를 기반으로 clean speech를 추정하기 위해, SGSME는 추론 중에 score estimator로써 neural network를 활용함
- 그러면 sampled Gaussian noise $\mathbf{z}$가 주어졌을 때, $\mathbf{x}_{t}$는:
(Eq. 6) $\mathbf{x}_{t}=\mu(\mathbf{x}_{0},\mathbf{y},t)+\sigma(t)\mathbf{z}$ - (Eq. 6)을 (Eq. 5)에 대입하면 score estimator $\mathbf{s}_{\theta}$는 다음의 score-matching objective로 training 됨:
(Eq. 7) $\arg\min_{\theta}\mathbb{E}_{\mathbf{x}_{t}|(\mathbf{x}_{0},\mathbf{y}),\mathbf{y},\mathbf{z},t}\left[\left|\left| \mathbf{s}_{\theta}(\mathbf{x}_{t},\mathbf{y},t)+\frac{\mathbf{z}}{\sigma(t)} \right|\right|_{2}^{2}\right]$
- Initial state로 clean speech $\mathbf{x}_{0}$, 해당 noisy speech $\mathbf{y}$, diffusion time step $t\in [0,T]$, standard Wiener process $\mathbf{w}$가 주어진다고 하자
3. Method
- Problems of GAN-based E2E Neural Codec
- Explicit phase modeling은 principal value interval $(-\pi,\pi]$를 가지는 white-noise-like signal의 phase에 기반함
- 이때 significant pattern의 부족은 phase modeling을 어렵게 하고, angular space의 phase prediction error는 phase wrapping을 위해 complicated form으로 formulate 되어야 함:
(Eq. 8) $\min \{ |\hat{\mathbf{p}}-\mathbf{p}|, 2\pi -|\hat{\mathbf{p}}-\mathbf{p}|\}$ - 이때 대부분의 neural codec은 multi-resolution spectral loss나 waveform loss와 같이 phase를 implicitly tackling 하는 loss만 사용해 GAN training에서 모델이 magnitude와 phase의 consistency를 학습함
- 결과적으로 해당 loss는 signal envelope에 초점을 맞추므로, over-smoothing과 high-frequency aliasing 문제가 발생할 수 있음
- 실제로 아래 그림의 (b)와 같이 mel-spectrogram loss 만으로 training 된 AudioDec은 subtle detail을 반영하지 못하고, high-frequency carrier wave와 같은 undesired detail을 생성하여 buzzy sound를 발생시킴
- 여기서 앞선 defect는 discriminator를 통해 detect 할 수 있으므로, high-fidelity의 합성을 위해서는 GAN training을 적용해야 함
- BUT, discriminator는 generated speech를 natural speech로 classify 할 probability를 최대화하는 fuzzy training objective를 가지므로 original phase를 preseving 한다는 보장이 없음
- 따라서 단순한 GAN training의 obscurity는 input speech의 subtle frequency detail이나 original phase에 대한 reconstruction ability를 저해함
- 이때 significant pattern의 부족은 phase modeling을 어렵게 하고, angular space의 phase prediction error는 phase wrapping을 위해 complicated form으로 formulate 되어야 함:

- Architecture Overview
- GAN training ($\text{AD}_{\text{stage1}}$)이 없는 AudioDec의 생성 결과는 over-smoothing 되어 있고 high-frequency-noise corrputed magnitude spectrum을 가지므로, speech enhancement task로 취급할 수 있음
- 따라서 SGMSE를 post-filter로 채택하여 $\text{AD}_{\text{stage1}}$ coded speech의 real/imaginary spectra를 enhance 하는 것으로 기존 GAN training의 original phase restoring 문제를 해결할 수 있음
- 결과적으로 ScoreDec은 symmetric neural audio codec인 AudioDec과 score-based diffusion post-filter (SPF)로 구성되고, 각각 mel-loss와 score-matching loss를 사용하여 개별적으로 training 됨
- 먼저 symmetric AudioDec은 speech를 low-bitrate discrete code로 encode 한 다음, SPF processing을 위해 preliminary speech를 decode 하여 final speech를 생성함
- 즉, AudioDec의 1st stage와 같이 mel-loss 만을 사용하여 training 됨 - 다음으로 clean speech $\mathbf{x}_{w}$, noisy speech인 $\text{AD}_{\text{stage1}}$ coded wavform $\hat{\mathbf{x}}_{w}$에 대한 paired input waveform이 주어지면, SPF는 (Eq. 7)의 score-matching objective로 training 됨
- 이때 complex spectral domain에서 SPF를 training 하기 위해, waveform signal $\mathbf{x}_{w},\hat{\mathbf{x}}_{w}$는 STFT를 통해 complex spectra $\mathbf{x}_{c}, \hat{\mathbf{x}}_{c}$로 변환됨
- 추가적으로 high-energy component에 dominate 되는 것을 방지하기 위해 amplitude modulation을 $\mathbf{x}_{c}, \hat{\mathbf{x}}_{c}$ 모두에 적용:
(Eq. 9) $\mathbf{x}_{a}=\beta | \mathbf{x}_{c}|^{\alpha}e^{i \angle (\mathbf{x}_{c})}$
- $\angle (\cdot)$ : complex number의 angle
- $\alpha\in (0,1]$ : amplitude companding constant
- $\beta$ : final amplitude를 $[0,1]$ 내로 normalize 하는 scaling constant - 그러면 해당 demodulation은 inverse STFT 이전에 enhanced complex spectra에 적용됨:
(Eq. 10) $\mathbf{x}_{c}=\beta^{-1}|\mathbf{x}_{a}|^{\frac{1}{\alpha}}e^{i\angle (\mathbf{x}_{a})}$
- 먼저 symmetric AudioDec은 speech를 low-bitrate discrete code로 encode 한 다음, SPF processing을 위해 preliminary speech를 decode 하여 final speech를 생성함
4. Experiments
- Settings
- Dataset : VCTK
- Comparisons : AudioDec, Opus
- Results
- 정량적 지표 측면에서 ScoreDec은 가장 우수한 성능을 달성함
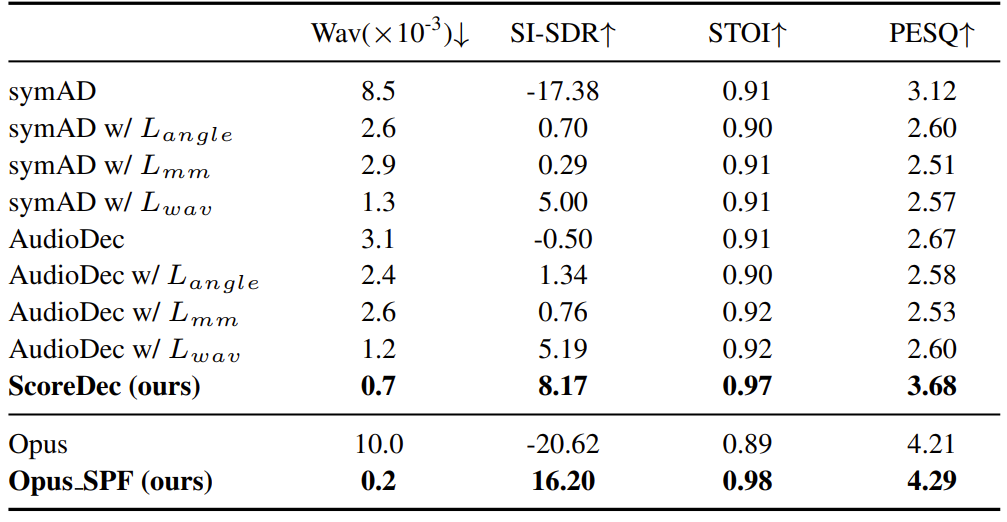
- ScoreDec의 합성 결과는 natural waveform과 well-align 되고 original phase를 well-preserving 함

- MOS 측면에서도 ScoreDec은 가장 우수한 성능을 보임

반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글