

 [Paper 리뷰] DDDM-VC: Decoupled Denoising Diffusion Models with Disentangled Representation and Prior Mixup for Verified Robust Voice Conversion
[Paper 리뷰] DDDM-VC: Decoupled Denoising Diffusion Models with Disentangled Representation and Prior Mixup for Verified Robust Voice Conversion
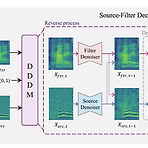
DDDM-VC: Decoupled Denoising Diffusion Models with Disentangled Representation and Prior Mixup for Verified Robust Voice ConversionDiffusion-based model은 data distribution에 많은 attribute가 존재하고 generation process에서 model parameter sharing에 대한 한계로 인해 각 attribute에 대한 specific style control이 어려움DDDM-VCDecoupled Denoising Diffusion Model을 도입하여 각 attribute에 대한 style transfer를 지원- 특히 voice conversion ta..
 [Paper 리뷰] DiffVC: Diffusion-based Voice Conversion with Fast Maximum Likelihood Sampling Scheme
[Paper 리뷰] DiffVC: Diffusion-based Voice Conversion with Fast Maximum Likelihood Sampling Scheme
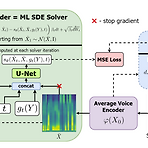
DiffVC: Diffusion-based Voice Conversion with Fast Maximum Likelihood Sampling SchemeOne-shot many-to-many voice conversion은 source/target speaker가 모두 training dataset에 속하지 않은 경우에 대해서 single reference utterance의 target voice를 copy 하는 것을 목표로 함DiffVCDiffusion probabilistic modeling을 기반으로 scalable one-shot voice conversion을 수행추가적으로 diffusion model을 가속할 수 있는 Stochastic Differential Equation solver를 ..
 [Paper 리뷰] VoiceTailor: Lightweight Plug-In Adapter for Diffusion-based Personalized Text-to-Speech
[Paper 리뷰] VoiceTailor: Lightweight Plug-In Adapter for Diffusion-based Personalized Text-to-Speech
VoiceTailor: Lightweight Plug-In Adapter for Diffusion-based Personalized Text-to-SpeechPre-trained diffusion-based model에 personalized adapter를 결합하여 parameter-efficient speaker adaptive Text-to-Speech를 수행할 수 있음VoiceTailorParameter-Efficient Adaptation을 위해 Low-Rank Adaptation을 활용하고 adapter를 pre-trained diffusion decoder의 pivotal module에 통합Few parameter 만으로 강력한 adaptation을 달성하기 위해 guidance techni..
 [Paper 리뷰] UnitSpeech: Speaker-Adaptive Speech Synthesis with Untranscribed Data
[Paper 리뷰] UnitSpeech: Speaker-Adaptive Speech Synthesis with Untranscribed Data
UnitSpeech: Speaker-Adaptive Speech Synthesis with Untranscribed DataMinimal untranscribed data를 사용하여 diffusion-based text-to-speech model을 fine-tuning 할 수 있음UnitSpeechSelf-supervised unit representation을 pseudo transcript로 사용하고 unit encoder를 pre-trained text-to-speech model에 integrate 함Unit encoder를 training 하여 diffusion-based decoder에 speech content를 제공한 다음, single $\langle \text{unit},\text{s..