

티스토리 뷰
Paper/TTS
[Paper 리뷰] VoiceTailor: Lightweight Plug-In Adapter for Diffusion-based Personalized Text-to-Speech
feVeRin 2024. 10. 3. 10:02반응형
VoiceTailor: Lightweight Plug-In Adapter for Diffusion-based Personalized Text-to-Speech
- Pre-trained diffusion-based model에 personalized adapter를 결합하여 parameter-efficient speaker adaptive Text-to-Speech를 수행할 수 있음
- VoiceTailor
- Parameter-Efficient Adaptation을 위해 Low-Rank Adaptation을 활용하고 adapter를 pre-trained diffusion decoder의 pivotal module에 통합
- Few parameter 만으로 강력한 adaptation을 달성하기 위해 guidance technique과 speaker information strengthening을 채택
- 논문 (INTERSPEECH 2024) : Paper Link
1. Introduction
- Adaptive Text-to-Speech (TTS)를 위해 zero-shot 방식과 one-shot 방식을 고려할 수 있음
- VoiceBox, VALL-E, P-Flow와 같은 zero-shot 방식은 speaker adaptation을 위해 reference audio에 대한 추가적인 fine-tuning 과정이 필요하지 않다는 장점이 있음
- BUT, 높은 speaker similarity를 달성하기 위해 일반적으로 training 중에 대용량의 speech corpus가 필요함 - 한편으로 AdaSpeech와 같은 one-shot 방식은 target speaker에 대한 few reference speech를 통해 pre-trained TTS model을 fine-tuning 하여 personalized TTS를 수행함
- 이때 target speaker에 대한 efficient adaptation을 위해 parameter subset을 활용하거나 Low-Rank Adaptation (LoRA)를 적용하거나, prefix-tuning 등을 사용하여 adapter의 parameter를 fine-tuning 할 수 있음
- BUT, 해당 방식은 decoder model의 한계로 인해 speaker similarity가 제한적이고, fine-tuning 과정에서도 1분 이상의 긴 speech data가 필요하다는 단점이 있음
- 한편으로 Guided-TTS, UnitSpeech와 같이 fine-tuning-based personalized generation을 위해 DDPM을 기반으로 diffusion-based one-shot TTS model을 구축할 수 있음
- 해당 방식들은 diffusion model의 adaptation 성능을 기반으로 5~10초의 짧은 reference speech 만으로도 높은 speaker similairty를 달성 가능함
- BUT, 기존 one-shot 방식과는 달리 모든 model parameter를 fine-tuning 하므로 parameter-inefficiency가 존재
- VoiceBox, VALL-E, P-Flow와 같은 zero-shot 방식은 speaker adaptation을 위해 reference audio에 대한 추가적인 fine-tuning 과정이 필요하지 않다는 장점이 있음
-> 그래서 pre-trained diffusion-based TTS model에서 parameter-subset 만을 fine-tuning 하는 parameter-efficient adaptive TTS model인 VoiceTailor를 제안
- VoiceTailor
- Pre-trained diffusion-based model을 기반으로 UnitSpeech의 fine-tuning method를 활용
- 이때 fine-tuning 전후의 module weight에 대한 change ratio를 분석하여 attention module의 효과를 검증 - 결과적으로 attention module에 LoRA를 적용하고 adaptation을 위해 inject된 low-rank matrix 만을 fine-tuning
- 추가적으로 parameter-efficient adaptation stage에서 최적 hyperparameter 선택과 inference stage에서의 guidance technique을 적용해 speaker information을 향상
- Pre-trained diffusion-based model을 기반으로 UnitSpeech의 fine-tuning method를 활용
< Overall of VoiceTailor >
- Diffusion-based speaker adaptive TTS를 위해 LoRA를 적용
- 추가적으로 LoRA module과 classifier-free guidance를 활용하여 speaker information을 향상
- 결과적으로 single GPU에서 전체 parameter의 0.25%만을 활용하여 speaker adaptation cost를 크게 절감
2. Method
- VoiceTailor는 기존 diffusion-based one-shot TTS의 parameter-inefficiency를 해결하기 위해 LoRA를 활용한 personalized TTS model을 구축하는 것을 목표로 함
- 먼저 VoiceTailor는 LoRA fine-tuning과 reference audio에서 추출한 speaker embedding을 통해 target speaker characteristic을 capture 함
- 추가적으로 논문은 UnitSpeech의 weight change ratio를 분석하여 speaker information을 향상함
- 결과적으로 VoiceTailor는 최적의 LoRA weight를 injection 하고 guidance strategy를 적용함으로써, 전체 parameter의 0.25%만을 fine-tuning 하여 personalized TTS를 달성함

- UnitSpeech
- 논문은 UnitSpeech를 기반으로 one-shot TTS를 수행함
- 먼저 UnitSpeech는 short untranscribed speech sample을 기반으로 pre-trained multi-speaker diffusion-based TTS model을 fine-tuning 해 personalized TTS model을 구성함
- 이때 multi-speaker diffusion-based TTS model은 Grad-TTS를 기반으로 mel-spectrogram $X_{0}$를 Guassian noise $X_{T}\sim\mathcal{N}(0,I)$로 변환하는 forward process를 정의함
- 해당 forward process는 pre-defined noise schedule $\beta_{t}$와 Wiener process $W_{t}$를 통해 정의됨
- 즉, forward process에서 time step $t\in[0,T]$의 noisy mel-spectrogram $X_{t}$는:
(Eq. 1) $dX_{t}=-\frac{1}{2}X_{t}\beta_{t}dt+\sqrt{\beta_{t}}dW_{t},\,\,\,t\in[0,1]$
(Eq. 2) $X_{t}=\sqrt{e^{-\int_{0}^{t}\beta_{s}ds}}X_{0}+\sqrt{1-e^{-\int_{0}^{s}\beta_{s}ds}}\epsilon_{t}$
- $\epsilon_{t}$ : standard normal distribution에서 sampling 된 noise
- 해당 forward process는 pre-defined noise schedule $\beta_{t}$와 Wiener process $W_{t}$를 통해 정의됨
- Forward process의 reverse trajectory를 따라 mel-spectrogram을 sampling 하려면 text encoder output $c_{y}$와 pre-trained speaker encoder에서 추출된 speaker embedding $e_{S}$로 condition 된 score $s(X_{t}|c_{y},e_{S})$를 사용해야 함
- 여기서 UnitSpeech의 diffusion-based decoder $\theta$는 conditional score $s_{\theta}(X_{t}|c_{y},e_{S})$를 예측하도록 training 됨
- 그러면 decoder pre-training에 대한 loss function과 sampling을 위한 predicted score는:
(Eq. 3) $\mathcal{L}=\mathbb{E}_{t,X_{0},\epsilon_{t}}\left[\left|\left| \sqrt{1-e^{-\int_{0}^{t}\beta_{s}ds}}s_{\theta}(X_{t}|c_{y},e_{S})+\epsilon_{t}\right|\right|_{2}^{2}\right]$
(Eq. 4) $X_{t-\Delta t}=X_{t}+\beta_{t}\left(\frac{1}{2}X_{t}+s_{\theta}(X_{t}|c_{y},e_{S})\right)\Delta t+\sqrt{\beta_{t}\Delta t} z_{t}$
- $z_{t}\sim\mathcal{N}(0,I)$ : Gaussian Noise
- 이를 기반으로 UnitSpeech는 pre-trained diffusion decoder를 untranscribed speech로 fine-tuning 하는 unit encoder를 도입해 text input을 없이 speaker adaptation이 가능하게 함
- 여기서 Unit encoder는 phonetic information을 포함하는 self-supervised speech representation인 acoustic unit을 input으로 하여 text encoder를 대체함
- 즉, UnitSpeech는 text encoder를 해당 pluggable unit encoder로 대체하고 pre-trained decoder와 동일한 objective로 training 한 다음, reference audio와 unit을 통해 fine-tuning 하여 speaker adaptation을 수행함
- 추가적으로 UnitSpeech는 diffusion model에서 conditioning information을 향상하는 classifier-free guidance를 text encoder output $c_{y}$에 결합해 pronunciation accuracy를 개선함
- 이를 확장하여 VoiceTailor는 classifier-free guidance를 speaker embedding $e_{S}$에도 적용함
- 즉, multi-speaker TTS model을 pre-training 하는 동안 learnable unconditional embedding $e_{\phi}$를 도입하고 25%의 확률로 $e_{\phi}$를 $e_{S}$로 대체하도록 함
- Parameter-Efficient Speaker Adaptation
- VoiceTailor는 speaker adaptation 과정에서 모든 parameter를 fine-tuning 하는 inefficiency를 해결하기 위해 parameter-efficient adaptation method인 LoRA를 채택함
- LoRA는 trainable low-rank decomposed matrix를 결합하여 linear layer의 weight matrix를 fine-tuning 함
- Linear layer의 pre-trained weight $W\in \mathbb{R}^{d\times k}$가 주어지면 LoRA는 $W+\alpha\cdot \Delta W=W+\alpha\cdot BA$로 augment 함
- 여기서 parameter $\Delta W:=W_{LoRA}$는 $W$가 frozen 된 상태에서 fine-tuning 됨
- $B\in\mathbb{R}^{d\times r}, A\in\mathbb{R}^{r\times k}, \alpha$ : adapter matrix의 scaling factor, $r$ : rank - 결과적으로 LoRA는 original matrix의 dimension $d,k$에 비해 rank $r$을 상당히 작은 값으로($r\ll d,k$) 사용함으로써 더 적은 parameter로 adaptation을 수행함
- 이때 pre-trained model parameter를 $\theta$, fine-tuned adapter $W_{LoRA}$가 있는 model parameter를 $\theta^{*}$로 나타냄
- UnitSpeech를 기반으로 모든 decoder parameter를 fine-tuning 해 speaker adaptation을 수행한 다음, 어떤 module이 speaker adaptation에서 중요하게 사용되는지 분석할 수 있음
- 이를 위해 논문은 pre-training 전후의 각 module $\theta_{i}$에 대한 weight change ratio $||\theta_{i}^{*}-\theta_{i}||/||\theta_{i}||$를 계산함
- 결과적으로 UnitSpeech의 diffusion decoder 내에서 attention module과 다른 module 간의 평균 change ratio를 계산해 보면 각각 0.0282와 0.0050으로 얻어짐
- 즉, attention module이 one-shot diffusion TTS model의 adaptation에서 가장 중요하게 사용됨
- 따라서 VoiceTailor는 attention module에 LoRA를 inject 하여 speaker adaptation을 위한 parameter를 최적화함
- LoRA는 trainable low-rank decomposed matrix를 결합하여 linear layer의 weight matrix를 fine-tuning 함
- Speaker Information Strengthening Strategies
- Fine-tuned adapter는 pre-trained multi-speaker TTS model과 결합되어 personalized TTS를 구성할 수 있음
- VoiceTailor에서 speaker information은 speaker embedding $e_{S}$와 pluggable LoRA weight $W_{LoRA}$의 2가지 form으로 제공됨
- 이때 parameter 감소로 인한 speaker adaptation 성능 저하를 완화하기 위해, target speaker information을 strengthen 하는 sampling method를 활용 가능 - 따라서 논문은 LoRA의 scaling factor $\alpha$를 fine-tuning 중에 사용되는 값보다 큰 값으로 설정하고, classifier-free guidance를 적용함
- VoiceTailor에서 speaker information은 speaker embedding $e_{S}$와 pluggable LoRA weight $W_{LoRA}$의 2가지 form으로 제공됨
- Adjustment of LoRA Scaling Factor
- $\alpha$는 speaker adaptation을 위해 pre-trained model에 adapter가 add 되는 intensity를 control 함
- 여기서 training 중에 사용되는 것보다 generation 중에 더 큰 $\alpha$를 사용함으로써 low-rank adapter에 stronger speaker information을 제공할 수 있음
- Classifier-Free Guidance
- VoiceTailor에서 speaker information은 $e_{S}, W_{LoRA}$ 2가지로 구성되므로 각 source에 대해 classifier-free guidance를 적용함
- 먼저 fine-tuned model $s_{\theta^{*}}(X_{t}|c,e_{S})$의 score가 주어졌을 때, unconditional score $s_{uncon}$에 대한 다음 3가지 candidate를 고려할 수 있음:
- $s_{\theta^{*}}(X_{t}|c,e_{\phi})$ : $W_{LoRA}$가 제공하는 speaker information을 유지하면서 $e_{S}$를 unconditional embedding $e_{\phi}$로 대체하여 얻어짐
- $s_{\theta}(X_{t}|c,e_{S})$ : Pre-trained model $\theta$에서 $W_{LoRA}$를 제거하고 $e_{S}$를 input으로 유지하여 얻어짐
- $s_{\theta}(X_{t}|c,e_{\phi})$ : $e_{s},W_{LoRA}$의 모든 speaker information이 없는 $s_{uncon}$
- 그러면 modified score $\hat{s}$는 앞선 unconditional score를 기반으로 다음의 classifier-free guidance를 적용하여 계산됨:
(Eq. 5) $\hat{s}_{\theta^{*}}(X_{t}|c,e_{S})=s_{\theta^{*}}(X_{t}|c,e_{S})+ \gamma_{S}\cdot \left(s_{\theta^{*}}(X_{t}|c,e_{S})-s_{uncon}\right)$
- $\gamma_{S}$ : additional speaker information의 intensity를 결정하는 gradient scale - 결과적으로 VoiceTailor는 $s_{uncon}=s_{\theta^{*}}(X_{t}|c, e_{\phi})$를 채택하여 sample을 생성함
- $\alpha$와 $s_{uncon}$에 대한 3가지 candidate audjusting과 $s_{uncon}=s_{\theta^{*}}(X_{t}|c,e_{\phi})$를 통한 classifier-free guidance 외의 방식은 speaker adaptation에 악영향을 주기 때문
3. Experiments
- Settings
- Dataset : LibriTTS
- Comparisons : UnitSpeech, XTTS, YourTTS
- Results
- Model Comparison
- 전체적으로 VoiceTailor가 가장 우수한 성능을 보임
- 특히 VoiceTailor는 0.25%의 parameter만 fine-tuning 하여 UnitSpeech 수준의 speaker similarity를 달성할 수 있음

- Parameter-Efficient Fine-Tuning
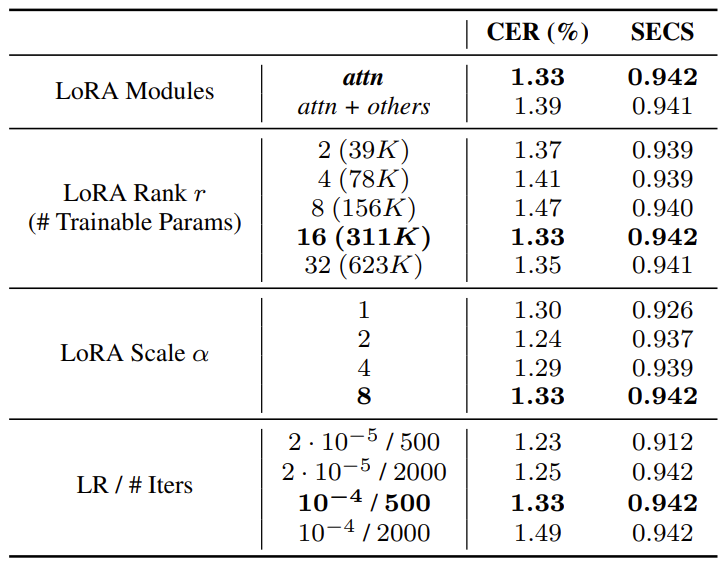
- Attention이 아닌 linear layer에 trainable low-rank matrix를 추가해도 pronunciation accuracy와 speaker similarity는 개선되지 않음
- 즉, attention module이 speaker adapatation에서 가장 중요함 - Fine-tuning 중 $W_{LoRA}$의 scale은 $\alpha$에 의해 결정됨
- $\alpha=1$과 같이 너무 작은 값을 사용하지 않는 한 비슷한 수준의 speaker similairty를 달성 가능 - $r=2$와 같은 작은 LoRA rank는 SECS를 저하하는 대신 39K의 parameter로 동작하는 VoiceTailor를 얻을 수 있음
- Attention이 아닌 linear layer에 trainable low-rank matrix를 추가해도 pronunciation accuracy와 speaker similarity는 개선되지 않음
- Speaker Information Strengthening Method
- Speaker embedding $E_{S}\,\, (S_{uncon}=s_{\theta^{*}}(X_{t}|c,e_{\phi}))$에 기반한 classifier-free guidance를 제외하면, 다른 method는 speaker adaptation 성능을 저하함
- 특히 fine-tuning에 사용된 값보다 LoRA scaling factor $\alpha$를 증가시키면 CER, SECS가 모두 저하됨
- 따라서 논문은 $\gamma_{S}=1$인 speaker embedding guidance만 사용함

반응형
'Paper > TTS' 카테고리의 다른 글
댓글