

 [Paper 리뷰] NeXt-TDNN: Modernizing Multi-Scale Temporal Convolution Backbone for Speaker Verification
[Paper 리뷰] NeXt-TDNN: Modernizing Multi-Scale Temporal Convolution Backbone for Speaker Verification
NeXt-TDNN: Modernizing Multi-Scale Temporal Convolution Backbone for Speaker VerificationConvNet structure를 활용하여 speaker verification을 위한 ECAPA-TDNN을 개선할 수 있음NeXt-TDNNECAPA-TDNN의 SE-Res2Net block을 TS-ConvNeXt block으로 대체- TS-ConvNeXt block은 temporal multi-scale convolution과 frame-wise feed-forward network로 구성됨Frame-wise feed-forward network에 global response normalization을 도입하여 selective feautre p..
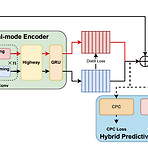 [Paper 리뷰] DualVC: Dual-mode Voice Conversion Using Intra-model Knowledge Distillation and Hybrid Predictive Coding
[Paper 리뷰] DualVC: Dual-mode Voice Conversion Using Intra-model Knowledge Distillation and Hybrid Predictive Coding
DualVC: Dual-mode Voice Conversion Using Intra-model Knowledge Distillation and Hybrid Predictive Coding일반적인 non-streaming voice conversion은 전체 utterance를 full context로 활용할 수 있지만, streaming voice conversion은 future information이 제공되지 않으므로 품질이 상당히 저하됨DualVCJointly trained separate network parameter를 활용하여 streaming/non-streaming mode를 지원하는 dual-mode conversion을 활용Streaming conversion의 성능을 향상하기 위해 i..
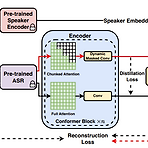 [Paper 리뷰] DualVC2: Dynamic Masked Convolution for Unified Streaming and Non-Streaming Voice Conversion
[Paper 리뷰] DualVC2: Dynamic Masked Convolution for Unified Streaming and Non-Streaming Voice Conversion
DualVC2: Dynamic Masked Convolution for Unified Streaming and Non-Streaming Voice Conversion기존의 DualVC는 streaming inference를 위해 streaming architecture, intra-model knowledge distillation, hybrid predictive coding을 활용함BUT, autoregressive decoder는 error accumulation의 문제가 있고 추론 속도가 제한적임- Causal convolution은 chunk 내의 future information을 효과적으로 사용할 수 없음- Unvoiced segment의 noise를 효과적으로 처리할 수 없어 음성 품질이 ..
 [Paper 리뷰] Vec-Tok-VC+: Residual-enhanced Robust Zero-shot Voice Conversion with Progressive Constraints in a Dual-mode Training Strategy
[Paper 리뷰] Vec-Tok-VC+: Residual-enhanced Robust Zero-shot Voice Conversion with Progressive Constraints in a Dual-mode Training Strategy
Vec-Tok-VC+: Residual-enhanced Robust Zero-shot Voice Conversion with Progressive Constraints in a Dual-mode Training StrategyVoice conversion는 decoupling process의 semantic loss와 training-inference mismatch로 인해 품질의 한계가 있음Vec-Tok-VC+Two-layer clustering process로 semantic content extraction을 향상하기 위해, residual-enhanced $K$-means decoupler를 도입Teacher-guided refinement를 사용하여 training-inference mismat..
 [Paper 리뷰] Fast DCTTS: Efficient Deep Convolutional Text-to-Speech
[Paper 리뷰] Fast DCTTS: Efficient Deep Convolutional Text-to-Speech
Fast DCTTS: Efficient Deep Convolutional Text-to-SpeechSingle CPU에서 real-time으로 동작하는 end-to-end text-to-speech model이 필요함Fast DCTTS다양한 network reduction과 fidelity improvement technique을 적용한 lightweight networkGating mechanism의 efficiency와 regularization effect를 고려한 group highway activation을 도입추가적으로 output mel-spectrogram의 fidelity를 측정하는 Elastic Mel-Cepstral Distortion metric을 설계논문 (ICASSP 2021) ..
 [Paper 리뷰] TriAAN-VC: Triple Adaptive Attention Normalization for Any-to-Any Voice Conversion
[Paper 리뷰] TriAAN-VC: Triple Adaptive Attention Normalization for Any-to-Any Voice Conversion
TriAAN-VC: Triple Adaptive Attention Normalization for Any-to-Any Voice ConversionVoice Conversion은 source speech의 content를 유지하면서 target speaker의 characteristic을 반영해야 함TriAAN-VCEncoder-Decoder architecture와 attention-based adaptive normalization block으로 구성된 Triple Adaptive Attention Normalization을 활용Adaptive normalization block을 통해 target speaker representation을 추출하고 siamese loss로 최적화를 수행논문 (ICA..