

티스토리 뷰
Paper/TTS
[Paper 리뷰] UnitSpeech: Speaker-Adaptive Speech Synthesis with Untranscribed Data
feVeRin 2024. 10. 1. 09:50반응형
UnitSpeech: Speaker-Adaptive Speech Synthesis with Untranscribed Data
- Minimal untranscribed data를 사용하여 diffusion-based text-to-speech model을 fine-tuning 할 수 있음
- UnitSpeech
- Self-supervised unit representation을 pseudo transcript로 사용하고 unit encoder를 pre-trained text-to-speech model에 integrate 함
- Unit encoder를 training 하여 diffusion-based decoder에 speech content를 제공한 다음, single $\langle \text{unit},\text{speech}\rangle$ pair로 decoder를 fine-tuning 해 reference에 대한 speaker adaptation을 지원
- 논문 (INTERSPEECH 2023) : Paper Link
1. Introduction
- Adaptive text-to-speech (TTS) model은 target speaker의 reference speech를 사용하여 personalized voice를 생성함
- 기존에는 YourTTS, AdaSpeech와 같이 target speaker embedding을 활용하거나 few data로 fine-tuning 하는 방식을 사용했음
- BUT, fine-tuning 방식은 높은 speaker similarity를 달성할 수 있지만, 대부분 speech와 pair 되는 transcript를 요구한다는 한계가 있음 - 최근에는 diffusion model이 text-to-image에서 뛰어난 personalize 성능을 보여 adaptive TTS로 확장되고 있음
- 특히 Guided-TTS는 diffusion model과 classifier guidance를 활용하여 10초 길이의 untranscribed speech로 고품질의 adaptive TTS가 가능함
- BUT, Guided-TTS는 unconditional generative model이므로 training이 어렵고 time-consuming 하다는 단점이 있음
- 기존에는 YourTTS, AdaSpeech와 같이 target speaker embedding을 활용하거나 few data로 fine-tuning 하는 방식을 사용했음
-> 그래서 few untranscribed speech에 대해 pre-trained diffusion TTS model을 fine-tuning 하여 personalized TTS를 수행하는 UnitSpeech를 제안
- UnitSpeech
- Speaker adaptation을 위한 backbone TTS model로써 multi-speaker Grad-TTS를 채택
- Transcript 없이 diffusion decoder에 speech content를 제공하기 위해 self-supervised unit representation을 사용하는 unit encoder를 도입
- 해당 unit encoder는 input unit을 사용하여 speech content를 diffusion decoder에 condition 하도록 training 됨 - 추가적으로 speaker adaptation을 위해 target speaker의 $\langle \text{unit, speech}\rangle$ pair를 사용하여 unit encoder로 condition 된 pre-trained diffusion model을 fine-tuning
- 결과적으로 UnitSpeech는 target speaker에 맞게 diffusion decoder를 customizing 하여 다양한 adaptive speech synthesis를 지원할 수 있음
< Overall of UnitSpeech >
- Speaker adaptation을 위해 unit representation을 도입하고 adaptive synthesis에서 pronunciation accuracy를 개선하는 guidance technique을 도입
- Pre-trained TTS model에 대한 pluggable unit encoder를 사용하여 untranscribed speech로 fine-tuning이 가능
- 결과적으로 기존보다 뛰어난 합성 성능을 달성
2. Method
- UnitSpeech는 untranscribed data 만을 사용하여 diffusion-based TTS model을 personalize 하는 것을 목표로 함
- 이때 diffusion model을 transcript 없이 personalize 하기 위해, fine-tuning 중에 text encoder를 대체하고 speech content를 encode 하는 unit encoder를 도입
- 결과적으로 해당 unit encoder를 사용하여 pre-trained TTS model을 다양한 task에서 target speaker에 맞게 adapt 할 수 있음
- Diffusion-based Text-to-Speech Model
- UnitSpeech는 pre-trained diffusion-based TTS model로써 multi-speaker Grad-TTS를 채택함
- 구조적으로는 Grad-TTS와 동일하게 text encoder, duration predictor, diffusion-based decoder로 구성되고 multi-speaker를 위한 speaker information을 가짐
- 여기서 speaker information은 speaker encoder에서 추출한 speaker embedding을 사용 - 먼저 diffusion-based TTS model은 mel-spectrogram $X_{0}$를 Gaussian noise $z=X_{T}\sim\mathcal{N}(0,I)$로 변환하는 forward process를 정의한 다음, 해당 process를 reversing 하여 generation을 수행함
- 이때 Grad-TTS의 경우 mel-spectrogram-aligned text encoder output을 사용하여 prior distribution을 정의하지만 UnitSpeech는 standard normal distribution을 prior를 사용
- 그러면 diffusion model의 forward process는:
(Eq. 1) $dX_{t}=-\frac{1}{2}X_{t}\beta_{t}dt+\sqrt{\beta_{t}}dW_{t},\,\,\, t\in[0,T]$
- $\beta_{t}$ : pre-defined noise schedule, $W_{t}$ : Wiener process
- $T$는 1로 설정
- Pre-trained diffusion decoder는 reverse process를 통해 sampling에 필요한 score를 예측함
- Pre-training을 위해 data $X_{0}$는 forward process를 거쳐 noisy data $X_{t}=\sqrt{1-\lambda_{t}}X_{0}+\sqrt{\lambda_{t}}\epsilon_{t}$로 corrupt 되고,
- Decoder는 aligned text encoder output $c_{y}$와 speaker embedding $e_{S}$를 고려하여 conditional score를 추정하도록 학습됨
- 이는 다음의 training objective와 같음:
(Eq. 2) $\mathcal{L}_{grad}=\mathbb{E}_{t,X_{0},\epsilon_{t}}\left[|| \sqrt{\lambda_{t}}s_{\theta} (X_{t},t|c_{y},e_{S})+\epsilon_{t}||_{2}^{2}\right]$
- $\lambda_{t}=1-e^{-\int_{0}^{t}\beta_{s}ds},\,\,\, t\in[0,1]$
- 결과적으로 추정된 score $s_{\theta}$는 diffusion decoder output과 동일하므로 model은 다음의 discretized reverse process를 사용하여 transcript와 speaker embedding이 주어졌을 때 mel-spectrogram $X_{0}$를 생성할 수 있음:
(Eq. 3) $X_{t-\frac{1}{N}}=X_{t}+\frac{\beta_{t}}{N}\left(\frac{1}{2}X_{t}+s_{\theta}(X_{t},t|c_{y},e_{S}) \right)+\sqrt{\frac{\beta_{t}}{N}}z_{t}$
- $N$ : sampling step 수 - 한편으로 (Eq. 2)의 $\mathcal{L}_{grad}$ 외에도 pre-trained TTS model은 Glow-TTS의 Monotonic Alignment Search (MAS)를 사용하여 text encoder output을 mel-spectrogram과 align 함
- 이후 일반적으로는 encoder loss $\mathcal{L}_{enc}=\text{MSE}(c_{y},X_{0})$를 사용하여 aligned text encoder output $c_{y}$와 mel-spectrogram $X_{0}$ 간의 distance를 최소화함
- 대신 논문은 text encoder와 speaker identity를 disentangle 하기 위해 text encoder에 speaker embedding $e_{S}$를 제공하지 않고 speaker-independent representation $c_{y}$와 $X_{0}$ 간의 distance를 최소화함
- 구조적으로는 Grad-TTS와 동일하게 text encoder, duration predictor, diffusion-based decoder로 구성되고 multi-speaker를 위한 speaker information을 가짐

- Unit Encoder Training
- Pre-trained TTS model만을 사용하여 untranscribed reference data에 대한 고품질 adaptation을 수행하는 것은 어려움
- 따라서 논문은 pre-trained TTS model에 unit encoder를 결합하여 adpatation 성능을 향상함
- 구조적으로 unit encoder는 기존 TTS model의 text encoder와 동일한 구조를 가짐
- 대신 unit encoder는 transcript를 input으로 하지 않고 discretized representation인 unit을 사용하여 untranscribed data에 대한 adaptation을 가능하게 함
- 이때 unit은 self-superviesd speech model인 HuBERT로 얻어지는 discretized representation을 활용 - 먼저 unit extraction process에서 speech waveform은 HuBERT의 input으로 제공되고 output representation은 $K$-means clustering을 통해 unit cluster로 discretize 되어 unit sequence를 생성함
- 여기서 적절한 cluster 수를 설정하여 desired speech content만 포함되도록 cosntrain 할 수 있음 - 이후 HuBERT로 얻어진 unit sequence는 mel-spectrogram length로 upsampling 된 다음, unit duration $d_{u}$로 compress 되어 squeezed unit sequence $u$를 제공함
- 대신 unit encoder는 transcript를 input으로 하지 않고 discretized representation인 unit을 사용하여 untranscribed data에 대한 adaptation을 가능하게 함
- Squeezed unit sequence $u$를 input으로 하는 pre-trained TTS model에 plug 된 unit encoder는 기존의 text encoder와 동일한 역할을 수행함
- 그러면 unit encoder는 동일한 training objective $\mathcal{L}=\mathcal{L}_{grad}+\mathcal{L}_{enc}$로 training 됨
- 대신 $c_{y}$를 ground-truth duration $d_{u}$를 사용하여 extend 된 unit encoder output $c_{u}$로 대체하여 사용 - 결과적으로 $c_{u}$는 $c_{y}$와 동일한 space에 배치되므로 fine-tuning 중에 text encoder를 unit encoder로 대체 가능
- 이때 diffusion decoder는 freeze 되고 unit encoder만 training 됨
- 그러면 unit encoder는 동일한 training objective $\mathcal{L}=\mathcal{L}_{grad}+\mathcal{L}_{enc}$로 training 됨
- Speaker-Adaptive Speech Synthesis
- Pre-trained TTS model과 pluggable unit encoder를 결합하면 target speaker의 single untranscribed speech를 사용하여 다양한 speech synthesis task를 수행할 수 있음
- 먼저 reference speech에서 추출한 squeezed unit $u'$과 unit duration $d_{u'}$을 사용하고, unit encoder로 TTS model의 decoder를 fine-tuning 함
- 이때 pronunciation deterioration을 최소화하기 위해 unit encoder를 freeze 하고 $c_{y}$를 $c_{u'}$로 대체한 (Eq. 2) objective를 사용하여 diffusion decoder 만을 training 함 - 그러면 trained model은 input으로 transcript나 unit을 사용하여 adpative speech를 합성할 수 있음
- TTS의 경우 fine-tuned decoder에 $c_{y}$를 condition으로 제공하여 주어진 transcript에 대한 personalized speech를 생성 가능
- Voice Conversion (VC)의 경우 주어진 source speech로부터 HuBERT를 통해 squeezed unit $u$와 unit duration $d_{u}$를 추출함
- 이후 $c_{u}$를 output 하는 unit encoder에 input 된 다음 adaptive diffusion decoder는 $c_{u}$를 condition으로 하여 converted speech를 생성
- 추가적으로 sampling 중에 classifier-free guidance의 unconditional score를 사용하여 target condition에 대한 conditioning degree를 amplify 하는 방식으로 pronunication을 더욱 향상할 수 있음
- 먼저 classifier-free guidance는 unconditional score를 추정하기 위해 unconditional embedding $e_{\Phi}$가 필요함
- 여기서 encoder loss는 output space를 mel-spectrogram에 가깝게 drive 하므로 dataset $c_{mel}$의 mel-spectrogram 평균으로 $e_{\Phi}$를 설정함
- 결과적으로 classifier-free guidance를 위한 modified score는:
(Eq. 4) $\hat{s}(X_{t},t|c_{c},e_{S})=s(X_{t},t|c_{c},e_{S})+\gamma\cdot \alpha_{t}$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \alpha_{t}=s(X_{t},t|c_{c},e_{S})-s(X_{t},t|c_{mel},e_{S})$
- $c_{c}$ : text/unit encoder의 aligned output
- $\gamma$ : 제공되는 condition information 양을 결정하는 gradient scale
- 먼저 reference speech에서 추출한 squeezed unit $u'$과 unit duration $d_{u'}$을 사용하고, unit encoder로 TTS model의 decoder를 fine-tuning 함
3. Experiments
- Settings
- Dataset : LibriTTS
- Comparisons
- TTS task : Guided-TTS, YourTTS
- VC task : DiffVC, BNE-PPG-VC
- Results
- Adaptive Text-to-Speech
- 전체적으로 UnitSpeech가 가장 우수한 합성 품질을 보임

- Any-to-Any Voice Conversion
- VC task도 마찬가지로 UnitSpeech의 성능이 가장 우수함
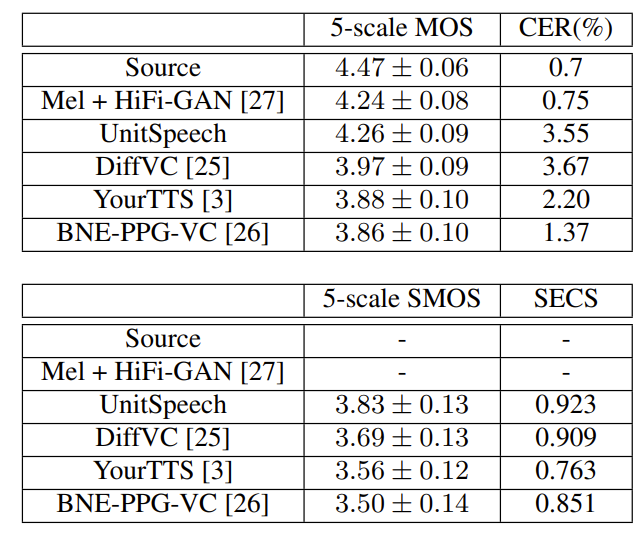
- Analysis
- Number of Unit Clusters
- Cluster 수 $K$는 TTS 성능에 큰 영향을 주지 않음
- BUT, VC task에 대해서는 $K$가 클수록 더 나은 pronunciation accuracy를 보임 - Fine-Tuning
- Fine-tuning에 사용된 reference speech 양이 증가할수록 pronunciation accuracy와 speaker similarity가 향상됨 - Gradient Scale in Classifier-Free Guidance
- Guidance는 speaker similarity를 희생하여 pronunciation을 크게 향상할 수 있음
- 이때 gradient scale $\gamma$를 TTS에 대해 1, VC에 대해 1.5로 설정하면 speaker similarity 저하를 최소화하면서 pronunciation 개선을 최대화할 수 있음
- Number of Unit Clusters

반응형
'Paper > TTS' 카테고리의 다른 글
댓글