

 [결산] 2024년도 상반기 앨범 결산
[결산] 2024년도 상반기 앨범 결산
어느새 6월도 되었고, 중간 결산도 할 겸 인상적이었던 상반기 앨범들을 뽑아봅시다.선정 기준 : 작성자 마음대로 뽑습니다.2024년도 상반기 앨범 결산 1. Bayside - - Pop Punk, Emo-Pop: 2024년 상반기 최고의 앨범은 미국의 팝 펑크 밴드 Bayside의 가 차지했습니다. 적당히 무게감 있는 장르 최적화 보컬과 중독적인 멜로디라인들이 흠결 없이 잘 어우러진 앨범입니다.Bayside - 'Good Advice' 2. Casey - - Post-Hardcore, Shoegaze: 멜로딕 하드코어를 기반으로 Alcest 식 슈게이즈 사운드를 살짝 엮어낸 올 상반기 최고의 하드코어 수작입니다. 특히 감정적인 멜로디 사이에서 간간히 폭발하는 하드코어 보컬은 그 쓸쓸한 상실감을 더욱 증폭..
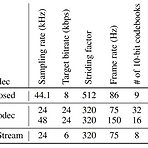 [Paper 리뷰] High-Fidelity Audio Compression with Improved RVQGAN
[Paper 리뷰] High-Fidelity Audio Compression with Improved RVQGAN
High-Fidelity Audio Compression with Improved RVQGANLanguage model의 핵심 component는 high-dimensional natural signal을 low-dimensional discrete token으로 compress 하는 neural codec임Improved RVQGANAdversarial, reconstruction loss와 vector quantization technique을 도입하여 high-fidelity의 audio compression을 보장추가적으로 speech, environment, music 등의 다양한 domain에 대한 universal compression을 지원논문 (NeruIPS 2023) : Paper Li..
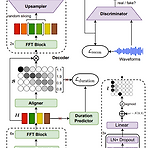 [Paper 리뷰] AutoTTS: End-to-End Text-to-Speech Synthesis through Differentiable Duration Modeling
[Paper 리뷰] AutoTTS: End-to-End Text-to-Speech Synthesis through Differentiable Duration Modeling
AutoTTS: End-to-End Text-to-Speech through Differentiable Duration ModelingText-to-Speech 모델은 일반적으로 external aligner가 필요하고, decoder와 jointly train 되지 않으므로 최적화의 한계가 있음AutoTTSInput, output sequence 간의 monotonic alignment를 학습하기 위해 differentiable duration method를 도입Expectation에서 stochastic process를 최적화하는 soft-duration mechanism을 기반으로 하여 direct text-to-waveform synthesis 모델을 구축추가적으로 adversarial train..
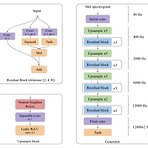 [Paper 리뷰] nVOC-22: A Low Cost Mel Spectrogram Vocoder for Mobile Devices
[Paper 리뷰] nVOC-22: A Low Cost Mel Spectrogram Vocoder for Mobile Devices
nVOC-22: A Low Cost Mel Spectrogram Vocoder for Mobile DevicesMobile CPU/GPU에서 동작할 수 있는 fully convolutional, non-autoregressive neural vocoder가 필요함nVOC-22Nearest neighbor resize와 separable convolution의 조합을 upsampling block에 적용하여 checkerboarding artifact를 최소화하고 빠른 upsampling을 지원추가적으로 Generative Adversarial Network를 기반으로 training 하여 안정적인 성능을 달성논문 (ICASSP 2023) : Paper Link1. Introduction음성 합성은 nav..
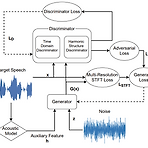 [Paper 리뷰] Harmonic WaveGAN: GAN-based Speech Waveform Generation Model with Harmonic Structure Discriminator
[Paper 리뷰] Harmonic WaveGAN: GAN-based Speech Waveform Generation Model with Harmonic Structure Discriminator
Harmonic WaveGAN: GAN-based Speech Waveform Generation Model with Harmonic Structure DiscriminatorSpeech waveform을 합성하기 위해 Generative Adversarial Network-based model을 활용할 수 있음Harmonic WaveGANTime/frequency domain에 대한 2개의 discriminator를 사용해 speech waveform의 characteristic을 capture 함특히 Harmonic Structure Discriminator는 harmonic convolution을 기반으로 harmonic structure를 모델링함논문 (INTERSPEECH 2021) : Pape..
 [Algorithm] 문자열 검색 - 라빈-카프 알고리즘
[Algorithm] 문자열 검색 - 라빈-카프 알고리즘
* Python을 기준으로 합니다문자열 검색 - 라빈-카프 알고리즘 (Rabin-Karp Algorithm)- 개념문자열 검색 (String Matching) : 주어진 문자열 내에서 특정한 패턴을 가진 문자열을 탐색하는 것e.g.) `This is Rabin Karp Algorithm`라는 문자열이 주어졌을 때, 패턴 `Karp`는 14번째 index에 있음이때 naive 한 문자열 검색 방법으로써 전체 문자열을 순회하면서 주어진 패턴과 일치하는지 여부를 판단하는 방식을 고려할 수 있음- BUT, 해당 방식은 $N$ 길이의 문자열과 $M$ 길이의 패턴에 대해 $O(NM)$의 time complexity가 소모되므로 길이가 긴 문자열에 적용하기 어려움라빈-카프 알고리즘해시를 사용하여 일치하는 패턴을 탐색..
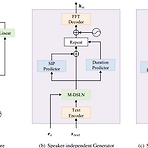 [Paper 리뷰] CrossSpeech: Speaker-Independent Acoustic Representation for Cross-Lingual Speech Synthesis
[Paper 리뷰] CrossSpeech: Speaker-Independent Acoustic Representation for Cross-Lingual Speech Synthesis
CrossSpeech: Speaker-Independent Acoustic Representation for Cross-Lingual Speech SynthesisCross-lingual Text-to-Speech 성능은 여전히 intra-lingual 성능보다 떨어짐CrossSpeechSpeaker와 language information의 disentangling을 acoustic feature space level에서 효과적으로 disentangling 하여 cross-lingual text-to-speech 성능을 향상이를 위해 Speaker-Independent Generator와 Speaker-Dependent Generator를 도입하고 각 information을 개별적으로 처리함으로써 dis..
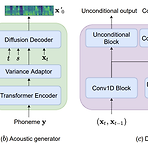 [Paper 리뷰] DiffGAN-TTS: High-Fidelity and Efficient Text-to-Speech with Denoising Diffusion GANs
[Paper 리뷰] DiffGAN-TTS: High-Fidelity and Efficient Text-to-Speech with Denoising Diffusion GANs
DiffGAN-TTS: High-Fidelity and Efficient Text-to-Speech with Denoising Diffusion GANsDenoising Diffusion Probabilistic Model (DDPM)은 음성 합성에서 우수한 성능으로 보이고 있지만, 높은 sampling cost의 문제가 있음DiffGAN-TTSDenoising distribution을 근사하기 위해 adversarially-trained expressive model을 채택한 denoising diffusion generative adversarial network (GAN)을 기반으로 함추가적으로 추론 속도를 더욱 향상하기 위해 active shallow diffusion mechanism을 도입Tw..
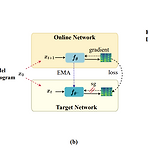 [Paper 리뷰] CM-TTS: Enhancing Real Time Text-to-Speech Synthesis Efficiency through Weighted Samplers and Consistency Models
[Paper 리뷰] CM-TTS: Enhancing Real Time Text-to-Speech Synthesis Efficiency through Weighted Samplers and Consistency Models
CM-TTS: Enhancing Real Time Text-to-Speech Synthesis Efficiency through Weighted Samplers and Consistency ModelsText-to-Speech에서 diffusion model을 사용하면 high-fidelity의 음성을 합성할 수 있지만 multi-step sampling으로 인해 real-time synthesis에는 한계가 있음한편으로 GAN과 diffusion model을 결합하여 denoising distribution을 근사하는 방식으로 추론 속도를 개선할 수 있지만, adversarial training으로 인해 모델 수렴의 어려움이 있음CM-TTSConsistency Model (CM)을 기반으로 advers..