

티스토리 뷰
Paper/Language Model
[Paper 리뷰] KALL-E: Autoregressive Speech Synthesis with Next-Distribution Prediction
feVeRin 2026. 3. 31. 13:10반응형
KALL-E: Autoregressive Speech Synthesis with Next-Distribution Prediction
- Text-to-Speech를 위해 autoregressive language model을 활용할 수 있음
- KALL-E
- Flow-VAE를 활용하여 waveform으로부터 continuous latent speech representation을 추출
- Single AR Transformer를 통해 text로부터 해당 continuous speech distribution을 predict
- 논문 (AAAI 2026) : Paper Link
1. Introduction
- VALL-E와 같이 Text-to-Speech (TTS)를 위해 Large Language Model (LLM)을 활용할 수 있음
- BUT, 대부분의 speech LLM은 discrete speech tokenizer로 인한 한계점을 가지고 있음:
- Discrete speech token은 tokenization 시 information loss가 발생함
- Discrete speech token은 high frame rate를 가지므로 short period에서 strong similarity가 나타남
- 이를 위해 MELLE, FELLE와 같은 continuous speech representation을 고려할 수 있지만, modeling capacity의 한계가 존재함
- BUT, 대부분의 speech LLM은 discrete speech tokenizer로 인한 한계점을 가지고 있음:
-> 그래서 기존 autoregressive speech LLM의 한계를 개선한 KALL-E를 제안
- KALL-E
- Kullback-Leibler (KL) divergence loss를 통한 next-distribution prediction을 활용해 continuous space에서 quantization으로 인한 information loss를 방지
- Flow-VAE와 Test-Time Training을 도입하여 diverse, robust synthesis를 지원
< Overall of KALL-E >
- Next-distribution prediction을 활용한 autoregressive speech synthesis model
- 결과적으로 기존보다 우수한 성능을 달성
2. Preliminary
- Variational AutoEncoder (VAE)
- VAE는 latent variable과 variational inference를 사용하여 data distribution을 explicitly modeling 함
- Observed sequential data $\mathbf{X}$가 주어지면 VAE는 continuous latent variable $\mathbf{Z}^{c}=\left(\mathbf{z}_{t}^{c}\in\mathbb{R}^{d_{z}^{c}}\right)_{t=1}^{T}$를 활용해 pattern을 encode 함
- $d_{z}^{c}$ : latent variable dimension - $\theta$로 parameterize 된 generative model (Decoder) $p_{\theta}(\mathbf{X}|\mathbf{Z}^{c})$는 latent variable에 condition 된 observed data에 대한 likelihood를 정의함
- $\phi$로 parameterize 된 inference model (Encoder) $q_{\phi}(\mathbf{Z}^{c}|\mathbf{X})$는 true posterior distribution을 approximate 함
- Observed, latent variable의 joint distribution은 $p_{\theta}(\mathbf{X},\mathbf{Z}^{c})=p(\mathbf{Z}^{c})p_{\theta}(\mathbf{X}|\mathbf{Z}^{c})$와 같음
- Prior distribution은 standard Gaussian distribution $p(\mathbf{Z}^{c})=\mathcal{N}(0,I)$로 가정함
- 이때 posterior $p_{\theta}(\mathbf{Z}^{c}|\mathbf{X})$를 directly compute 하는 것은 intractable 하므로 optimization을 위해 Evidence Lower BOund (ELBO)를 도입함:
(Eq. 1) $ \log p_{\theta}(\mathbf{X})\geq \underset{\mathcal{O}_{ELBO}}{\underbrace{ \mathbb{E}_{q_{\phi}(\mathbf{z}^{c}|\mathbf{x})}\left[\log p_{\theta}(\mathbf{X}|\mathbf{Z}^{c})\right]-D_{KL}\left( q_{\phi}\left(\mathbf{Z}^{c}|\mathbf{X}\right)||p(\mathbf{Z}^{c})\right) }}$
- $\mathcal{O}_{ELBO}$를 maximize 해 encoder-decoder architecture를 train 할 수 있고, inferred latent representation $\mathbf{Z}^{c}$가 sequential data를 compactly summarize 하도록 보장할 수 있음
- Observed sequential data $\mathbf{X}$가 주어지면 VAE는 continuous latent variable $\mathbf{Z}^{c}=\left(\mathbf{z}_{t}^{c}\in\mathbb{R}^{d_{z}^{c}}\right)_{t=1}^{T}$를 활용해 pattern을 encode 함
- Speech Language Model
- Speech language model은 speech token과 같은 latent speech representation을 speech sequence로 modeling 함
- 구조적으로 token-based speech modeling은 speech tokenizer, autoregressive model, decoder로 구성됨
- 먼저 raw speech input $\mathbf{X}$가 주어지면 speech tokenizer는 $\mathbf{X}$를 discrete semantic token $\mathbf{Z}^{d}=\left(z_{t}^{d}\in\mathcal{N}_{k}\right)_{t=1}^{T}$로 mapping 함
- $\mathcal{N}_{k}=\{1,2,...,k\}$ : speech unit의 finite vocabulary - 이때 pre-trained tokenizer로 학습된 implicit distribution을 $p(\mathbf{Z}^{d}|\mathbf{X})$와 같음
- 먼저 raw speech input $\mathbf{X}$가 주어지면 speech tokenizer는 $\mathbf{X}$를 discrete semantic token $\mathbf{Z}^{d}=\left(z_{t}^{d}\in\mathcal{N}_{k}\right)_{t=1}^{T}$로 mapping 함
- $\psi$로 parameterize 된 autoregressive model은 discrete token sequence의 temporal dependency를 다음과 같이 modeling 함:
(Eq. 2) $p_{\psi}(\mathbf{Z}^{d})=\prod_{t=1}^{T}p_{\psi}\left(z_{t}^{d}|\mathbf{Z}_{1:t-1}^{d}\right)$ - 이후 decoder $\theta$는 discrete speech token $\mathbf{Z}^{d}$로부터 $p_{\theta}(\mathbf{X}|\mathbf{Z}^{d})$를 통해 speech $\mathbf{X}$를 reconstruct 함
- 구조적으로 token-based speech modeling은 speech tokenizer, autoregressive model, decoder로 구성됨
3. Method
- KALL-E는 TTS task를 next-distribution prediction으로 frame 된 conditional language-modeling으로 취급함
- 즉, KALL-E는 textual input에 condition 되어 continuous speech distribution을 directly predict 함
- 구조적으로는 Flow-VAE와 autoregressive language model로 구성됨
- Flow-VAE는 raw waveform을 fine-grained acoustic variation을 capture 하는 continuous latent space로 encoding 하고, normalizing flow module을 통해 latent distribution의 expressiveness를 향상함
- 해당 continuous latent는 autoregressive language model에 well-structured training target을 제공함

- Flow-VAE
- Continuous speech latent를 autoregressive language model에 furnish 하기 위해 논문은 unsupervised manner로 VAE를 training 함
- 먼저 vanilla VAE를 normalizing flow $f$로 augment 하여 simple prior와 complex posterior 간의 bijective transformation을 구성함
- 즉, $z\sim \mathcal{N}(\mu_{\phi}(x), \sigma_{\phi}(x))$를 sampling 하여 $\tilde{z}=f(z)$를 얻음
- Regularization objective는 transformed posterior/standard normal prior 간의 Kullback-Leibler (KL) divergence를 minimize 함:
(Eq. 3) $\mathcal{L}_{kl}=D_{KL}\left(q_{\phi}(\tilde{z}|x)||p(\tilde{z})\right)$
(Eq. 4) $q_{\phi}(\tilde{z}|x)=\mathcal{N}(f(\tilde{z});\mu_{\phi}(x),\sigma_{\phi}(x))\left| \det\frac{\partial f(\tilde{z})}{\partial \tilde{z}}\right|$
(Eq. 5) $z\sim \mathcal{N}(\mu_{\phi}(x),\sigma_{\phi}(x))$
(Eq. 6) $p(\tilde{z})=\mathcal{N}(\tilde{z},0,I)$
- 구조적으로 Flow-VAE의 encoder는 residual block을 포함한 downsampling dilated convolution layer stack으로 구성되어 speech의 abstract feature를 capture 함
- Encoding 후 생성된 mean/variance는 learned latent distribution $q_{\phi}(z|x)=\mathcal{N}(\mu_{\phi}(x), \sigma_{\phi}(x))$의 parameter로 볼 수 있음
- Decoder는 encoder architecture를 mirror 하는 대신 transposed convolution layer를 사용하여 latent representation $z$를 waveform $\hat{x}$로 upsampling 함
- 추가적으로 BigVGAN의 Snake activation function도 적용함
- 결과적으로 Flow-VAE는 다음 loss의 weighted sum으로 optimize 됨:
(Eq. 7) $\mathcal{L}_{Flow\text{-}VAE}=\lambda_{kl}\mathcal{L}_{kl}+\lambda_{recon}\mathcal{L}_{recon}+\lambda_{disc}\mathcal{L}_{disc}+\lambda_{fm}\mathcal{L}_{fm}$
- $\mathcal{L}_{recon}$ : $\ell 1$ mel-spectrogram loss, $\mathcal{L}_{disc}$ : multi-period/multi-resolution discriminator loss, $\mathcal{L}_{fm}$ : feature-matching loss, $\lambda$ : hyperparameter
- 먼저 vanilla VAE를 normalizing flow $f$로 augment 하여 simple prior와 complex posterior 간의 bijective transformation을 구성함
- Autoregressive Language Model
- KALL-E의 language model은 causal Transformer decoder를 기반으로 continuous speech distribution을 autoregressively predict 함
- Input text token은 text embedding layer를 통해 embedding 되고 linear layer는 sampled speech distribution $z$를 language model dimension으로 project 함
- 이때 speech의 small segment가 randomly extract 되어 speaker embedding $S$를 추출하는 speaker encoder에 전달되고, sequence 앞에 prepend 됨 - Multi-head self-attention과 feed-forward layer로 구성된 language model은 speaker, text, speech embedding을 input으로 concatenate 하여 semantic, acoustic information 간의 dependency를 modeling 함
- 각 time step $t$에서 language model output $h_{t}$는 linear layer를 통해 target speech distribution의 mean $\mu_{t}$, vairance $\sigma_{t}$를 predict 하고, subsequent autoregressive step의 distribution을 sampling 하는 데 사용됨:
(Eq. 8) $p(\mu,\sigma|S,\text{text},\theta)=\prod_{t=1}^{T}p(\mu_{t},\sigma_{t}| S,\text{text},Z_{<t},\theta)$
(Eq. 9) $Z_{t}\sim\mathcal{N}(\mu_{t},\sigma_{t})$
- $\theta$ : language model의 parameter - 논문은 language model의 training objective로 KL-divergence loss를 사용함
- KL loss는 predicted/real speech distribution에 대한 term과 stop prediction에 대한 term으로 구성됨
- 여기서 논문은 $\mathcal{N}(1,e)$를 stop distribution으로 정의함 - 그러면 KL loss는:
(Eq. 10) $\mathcal{L}_{LM}=\sum_{t=1}^{T}D_{KL}\left( q_{\phi}(z_{t}|X)|| p(Z_{t}|Z_{1:t-1},\text{text},S,\theta)\right) +\lambda_{end}D_{KL}\left(N_{end}||p(e|Z, \text{text},S,\theta)\right)$
- $N_{end}$ : pre-defined end distribution, $\lambda_{end}$ : hyperparameter
- KL loss는 predicted/real speech distribution에 대한 term과 stop prediction에 대한 term으로 구성됨
- Input text token은 text embedding layer를 통해 embedding 되고 linear layer는 sampled speech distribution $z$를 language model dimension으로 project 함

- Speaker Voice Distribution Modeling
- 논문은 high voice diversity를 위해 speaker voice distribution modeling을 도입함
- 이를 위해 ECAPA-TDNN으로 speaker embedding을 추출하고 linear layer에 project 해 latent distribution을 얻음
- Training 시 KL-term은 latent를 isotropic Gaussian prior로 regularize 함 - 추론 시 reference utterance가 주어지면 해당 speaker latent $S$를 추출하여 condition으로 사용함
- Reference가 주어지지 않는 경우, $\tilde{S}\sim\mathcal{N}(0,I)$를 sampling 함
- 이때 random seed $\tilde{S}$는 store 될 수 있으므로 KALL-E는 single latent framework 내에서 repeatable, controllable voice cloning을 지원할 수 있음
- 이를 위해 ECAPA-TDNN으로 speaker embedding을 추출하고 linear layer에 project 해 latent distribution을 얻음

- Test Time Training
- 논문은 하나의 utterance 만으로 language model을 새로운 speaker에 adapt 할 수 있는 lightweight Test-Time Training (TTT)를 도입함
- 먼저 prompt utterance $S$에 대해 pre-trained Flow-VAE를 사용하여 prompt speech $S$의 distribution을 추출한 다음, 해당 distribution을 통해 TTT의 supervised signal을 구성함
- Reparameterization trick을 사용하여 $N$ latent sequence를 추출하고, TTT dataset에 collect 함:
(Eq. 11) $z_{i}\sim\mathcal{N}(\mu_{\phi}(S),\sigma_{\phi}(S))$
(Eq. 12) $\mathcal{D}_{TTT}=\{z_{1},z_{2},...,z_{n}\}$ - TTT 시에는 speaker encoder를 freeze 하고 language model만 fine-tuning 함
- End-of-Sequencce distribution은 loss에서 exclude 되고, model은 fixed transcript, sampled latent prefix를 기반으로 frame-level distribution을 predict 함
- Loss는 predicted/target distribution 간의 KL-divergence로 정의됨 - 이를 통해 single-sample adaptation으로 인한 overfitting을 mitigate 하면서 style, accent와 같은 speaker-specific detail을 효과적으로 capture 할 수 있음
- End-of-Sequencce distribution은 loss에서 exclude 되고, model은 fixed transcript, sampled latent prefix를 기반으로 frame-level distribution을 predict 함
4. Experiments
- Settings
- Dataset : Emilia
- Comparisons : CosyVoice, CosyVoice2, Seed-TTS, FireRedTTS, Llasa
- Results
- 전체적으로 KALL-E의 성능이 가장 뛰어남

- MOS 측면에서도 최고의 성능을 보임

- KALL-E는 가장 적은 FLOPS를 가짐

- KALL-E는 emotional speech prompt 없이도 appropriate emotion을 infer 할 수 있음

- VAE Evaluation
- Flow-VAE는 뛰어난 audio reconstruction이 가능함

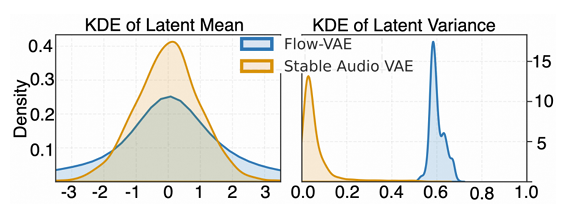
- Flow-VAE의 mean distribution은 Stable Audio VAE 보다 broad 하고 variance distribution은 상당히 다르게 나타남
- Ablation Study
- 512 dimension의 Flow-VAE를 사용했을 때 최적의 결과를 달성함

- Training set size $N=200$일 때 가장 낮은 CER을 보임

반응형
'Paper > Language Model' 카테고리의 다른 글
댓글