

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] FocalCodec: Low-Bitrate Speech Coding via Focal Modulation Networks
feVeRin 2025. 11. 5. 13:24반응형
FocalCodec: Low-Bitrate Speech Coding via Focal Modulation Networks
- 기존의 neural codec은 high bitrate, semantic/acoustic information loss의 문제가 있음
- FocalCodec
- Focal modulation을 기반으로 single binary codebook을 사용하여 speech를 compress
- Semantic/acoustic information을 preserve 하여 다양한 downstream task에서 우수한 성능을 달성
- 논문 (NeurIPS 2025) : Paper Link
1. Introduction
- AudioLM, AudioGen과 같은 speech language model은 token-based speech processing을 주로 활용함
- Neural codec은 해당 pipeline에서 speech를 downstream model이 처리할 수 있는 token으로 compress 함
- 해당 token은 high reconstruction quality와 effective representation을 위해 acoustic/semantic information을 preserve 할 수 있어야 함
- 추가적으로 sequence length가 증가함에 따라 long-term dependency를 capture 하는 것이 어려워지므로, low token rate를 가져야 함
- 대표적으로 EnCodec, DAC, WavTokenizer와 같은 acoustic codec은 high quality reconstruction이 가능함
- BUT, multiple codebook으로 인한 complexity가 존재하고 strong semantic representation이 부족함
- SpeechTokenizer와 같은 hybrid codec 역시 complex multi-codebook design과 distillation, supervisied fine-tuning이 필요하다는 단점이 있음
- 이를 해결하기 위해 Single-codebook design을 고려할 수 있지만 low bitrate에서 compression과 reconstruction quality 간의 balance를 확보하기 어려움
- Neural codec은 해당 pipeline에서 speech를 downstream model이 처리할 수 있는 token으로 compress 함
-> 그래서 효과적인 low bitrate, single codebook codec인 FocalCodec을 제안
- FocalCodec
- Focal modulation을 기반으로 single binary codebook space로 speech를 compress
- Compressor-quantizer-decompressor로 구성되는 hybird codec design을 활용
< Overall of FocalCodec >
- Focal modulation을 활용한 single codebook neural codec
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- Architecture
- FocalCodec은 VQ-VAE framework의 encoder-decoder 사이에 compressor와 decompressor를 추가함
- Discriminator는 training에서만 사용됨 - Encoder
- Simple hybird codec design을 위해 encoder는 multiple encoder나 distillation loss 없이 acoustic/semantic information을 모두 capture 할 수 있어야 함
- 이때 HuBERT, WavLM과 같은 self-supervised model은 lower layer에서 acoustic information을 retain 한다는 특징이 있음
- 따라서 논문은 WavLM-large의 first 6-layer를 encoder로 사용함 - 이후 continuous representation을 sufficient granularity로 approximate 하기 위해 focal modulation 기반의 Compressor-Quantizer-Decompressor design을 적용함
- 이를 통해 semantic/acoustic detail을 효과적으로 preserve 하면서 quantization을 수행할 수 있음
- Compressor
- Compressor는 encoder representation을 compact, low-dimensional latent space로 mapping 함
- 여기서 논문은 기존의 convolutional, recurrent, Transformer-based architecture와 달리 focal downsampling module을 도입하여 compression을 수행함 - Downscaling step에서는 feature dimension을 compress 하는 linear projection을 적용한 다음, DAC를 따라 periodic pattern을 capture 하는 Snake activation을 활용함
- Focal block은 standard Transformer block의 self-attention을 focal modulation으로 replace 하여 구축됨
- Focal modulation은 self-attention의 alternative로써 fine-to-coarse modeling과 translation equivariance, explicit input dependency와 같은 useful inductive bias를 지원함
- 특히 token-wise interaction을 directly compute 하는 self-attention과 달리 focal modulation은 global context를 aggregate 한 다음 해당 representation을 기반으로 local interaction을 modulate 함
- 즉, self-attention은 token 간 pairwise similarity를 compute 한 다음 aggregate 하므로 few high-scoring neighbor에 sensitive 할 수 있음
- 반면 focal modulation은 반대로 compact, multi-scale summary (local+global context)를 생성한 다음, 해당 summary를 사용하여 각 token을 modulate 함
- 결과적으로 focal modulation은 interaction이 individual token에 의해 dominate 되지 않고 overall context에 의해 guide 됨
- Focal modulation에서 sequence $\mathbf{x}_{1:n}$의 각 input feature $\mathbf{x}_{i}$에 대한 output representation $\mathbf{y}_{i}$는:
(Eq. 1) $ \mathbf{y}_{i}=q(\mathbf{x}_{i})\odot h\left(\sum_{\ell=1}^{L+1}\mathbf{z}^{\ell}_{i} \odot \mathbf{g}_{i}^{\ell}\right)$
- $q(\cdot), h(\cdot)$ : linear projection, $\odot$ : element-wise multiplication
- $\mathbf{z}^{\ell}_{i}\in\mathbf{z}^{\ell}_{1:n}, \mathbf{g}_{i}^{\ell}\in\mathbf{g}_{1:n}^{\ell}$ : 각각 position $i$와 focal level $\ell\in \{1,...,L+1\}$에서의 context/gating vector - Context sequence $\mathbf{z}_{1:n}$은 short-to-long range dependency를 capture 하기 위해 kernel size가 증가하는 depth-wise convolution stack으로 얻어짐
- Last level feature map에는 global information을 incorporate 하기 위한 average pooling이 적용됨
- 이후 각 focal level에 대해 point-wise convolution을 사용하여 gating sequence $\mathbf{g}_{1:n}$을 compute 함
- 해당 hierarchical approach는 multiple granularity에서 동작하여 long-range dependency를 preserve 하면서 linear time 내에 efficient, scalable representation을 학습할 수 있도록 함
- Compressor는 encoder representation을 compact, low-dimensional latent space로 mapping 함
- Quantizer
- FocalCodec은 compressor에서 생성된 latent representation을 single quantizer의 codebook space로 mapping 하여 hierarchical design에 대한 의존성을 제거함
- 이때 quantizer는 reconstruction quality와 efficiency의 balance를 위해 다음을 만족해야 함:
- Original waveform이 이미 latent의 short sequence로 compress 되어 있으므로 quantizer는 quantization error를 줄이기 위해 sufficiently large codebook size를 가져야 함
- Quantizer는 codebook capacity를 efficiently use 하고 under-utilization을 avoid 해야 함
- Codebook size가 증가하더라도 code lookup은 efficient 해야 함
- 이를 위해 논문은 implicit codebook을 활용하는 Lookup-Free Quantization (LFQ) method인 Binary Spherical Quantization (BSQ)를 도입함:
(Eq. 2) $\mathcal{C}=\left\{-\frac{1}{\sqrt{L}},\frac{1}{\sqrt{L}}\right\}^{L}$
- 이는 $L$-dimensional hypercube를 unit-hypersphere로 project 하는 것을 의미함
- Codebook size는 latent representation dimension $L$에 의해 $|\mathcal{C}|=2^{L}$과 같이 결정됨 - Quantization process는 2-step으로 구성됨
- 먼저 dimension $L$의 input vector $\mathbf{v}$는 unit-hypersphere에 lie 되도록 normalize 됨:
(Eq. 3) $\mathbf{u}=\frac{\mathbf{v}}{||\mathbf{v}||_{2}}$ - $\sqrt{L}$의 normalization factor를 사용한 binary quantization이 $\mathbf{u}$의 각 dimension에 independently apply 됨:
(Eq. 4) $\hat{\mathbf{u}}=\frac{\text{sign}(\mathbf{u})}{\sqrt{L}}$
- $\text{sign}(\cdot)$ : sign function, $\text{sign}(0)$은 hypersphere에 lie 되기 위해 $1$로 remapping 됨 - 추가적으로 quantization을 differentiable 하게 만들기 위해 straight-through estimator가 사용됨
- 먼저 dimension $L$의 input vector $\mathbf{v}$는 unit-hypersphere에 lie 되도록 normalize 됨:
- 해당 BSQ는 기존 quantization method에 비해 다음의 장점을 가짐:
- Parameter-free implicit codebook 이므로 lightweight 하고 computationally efficient 함
- Large $L$ value에 대해서도 high codebook utilization을 보임
- Quantization error가 bound 되어 있어 faster convergence가 가능함
- Codebook size를 latent dimension과 연결하면 larger codebook에서 성능 저하를 방지할 수 있음
- Decompressor
- Decompressor는 quantizer output으로부터 encoder continuous representation을 reconstruct 함
- 구조적으로는 compressor의 mirror로써 downscaling layer를 upsampling layer로 replace 함
- Decoder
- 논문에서는 asymmetric design을 채택하여 encoder에 decoder 보다 $5\times$ 더 많은 parameter를 할당함
- 즉, strong encoder를 활용해 downstream task를 위한 robust, disentangled representation을 추출함
- 반면 small decoder의 경우 high compression rate에서도 high-qaulity audio와 더 빠른 추론을 제공할 수 있으므로 application에 적합하다는 장점이 있음
- 구조적으로 decoder는 Vocos를 따라 inverse STFT와 ConvNeXt block을 활용하여 waveform을 reconstruct 함
- 논문에서는 asymmetric design을 채택하여 encoder에 decoder 보다 $5\times$ 더 많은 parameter를 할당함
- Discriminator
- FocalCodec은 HiFi-GAN을 따라 Multi-Period Discriminator, Multi-Scale Discriminator를 채택함
- Multi-resolution/STFT-based Discriminator는 medium frequency range와 맞지 않으므로 사용하지 않음

- Training
- Training process는 2-stage로 구성됨
- 해당 decoupled training approach를 통해 FocalCodec은 token에서 semantic/acoustic information을 모두 preserve 하여 high reconstruction quality를 유지할 수 있음
- First stage에서는 compressor, quantizer, decompressor를 jointly training 하여 encoder continuous representation을 reconstruct 함
- 이때 encoder는 freeze 하여 token이 semantic/acoustic information을 retain 할 수 있도록 함
- Training objective는 reconstruction loss와 entropy loss를 사용함
- Reconstruction loss는 reconstructed/original encoder feature 간의 squared $L2$ distance로 얻어짐
- Entropy loss는 confident prediction과 uniform code utilization을 위해 사용됨 - BSQ에서는 quantization error가 bound 되어 embedding divergence가 발생하지 않으므로 commitment loss는 사용되지 않음
- Second stage에서는 continuous representation으로부터 audio를 resynthesize 하도록 decoder를 training 함
- Training objective는 adversarial loss, reconstruction loss, feature matching loss로 구성됨
- Reconstruction loss는 reconstructed/original log-mel spectrogram 간의 $L1$ distance로 얻어지고, feature matching loss는 $k$-th sub-discriminator의 $l$-th feature map 간 distance의 mean으로 얻어짐
- Training objective는 adversarial loss, reconstruction loss, feature matching loss로 구성됨
- 추론 시에는 동일한 decoder가 compressor-quantizer-decompressor pipeline에서 생성된 dequantized feature에 대해 동작함
- Decompressor는 discrete code로부터 original continuous feature를 reconstruct 하도록 training 되므로 해당 dequantized feature는 original을 closely approximate 함
- 결과적으로 decoder는 input으로 dequantized feature를 사용하더라도 additional fine-tuning 없이 strong performance를 유지할 수 있음
3. Experiments
- Settings
- Dataset : LibriTTS
- Comparisons : EnCodec, DAC, WavTokenizer, SpeechTokenizer, WavLM, SemantiCodec, Mimi, StableCodec, BigCodec
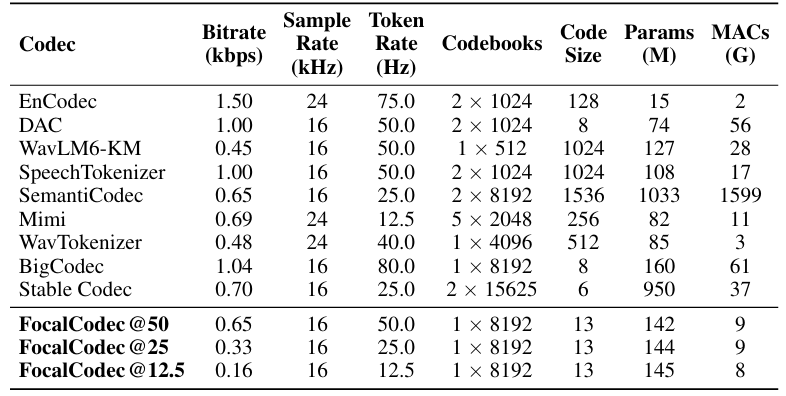
- Results
- Speech resynthesis 측면에서 FocalCodec은 우수한 성능을 보임
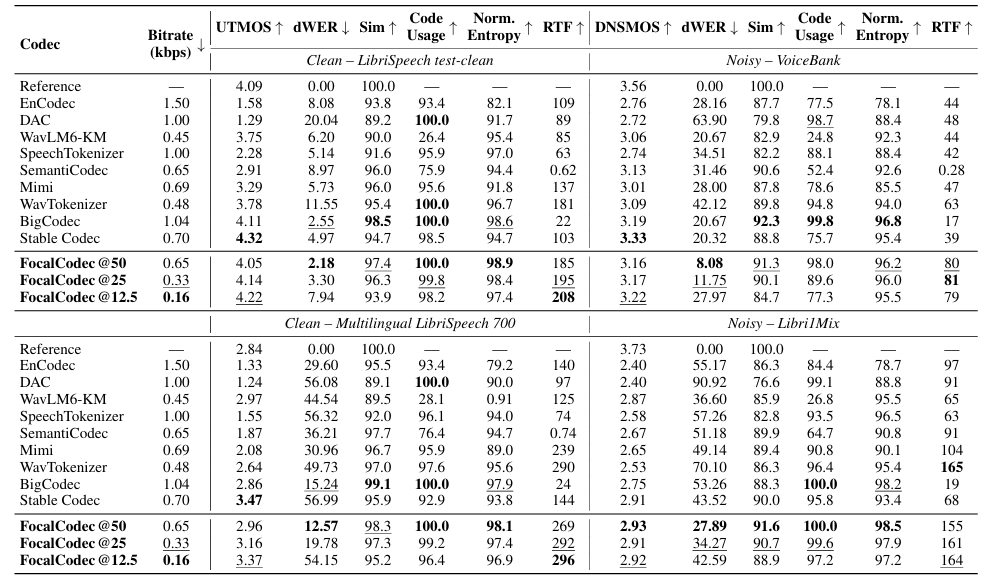
- Voice Conversion
- Voice conversion에서도 높은 similarity를 달성함
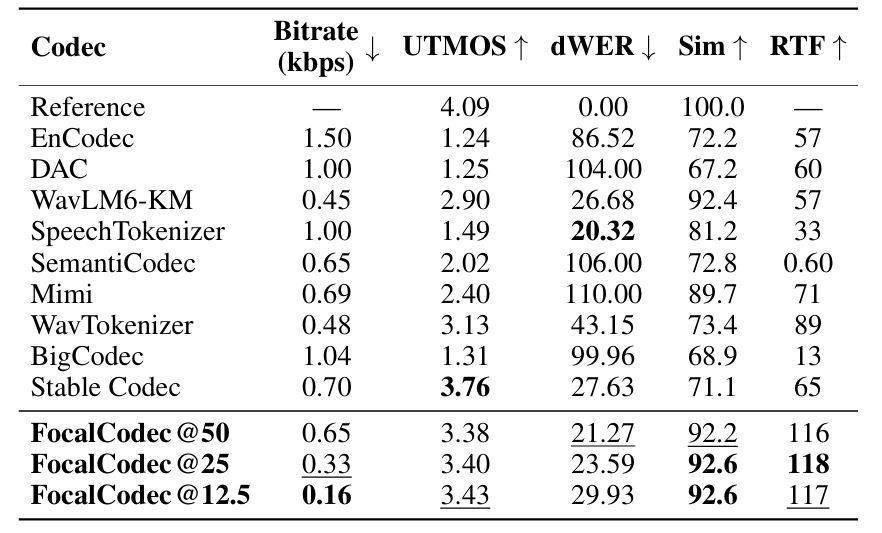
- Downstream Task
- Discriminative, generative task 모두에서 최고의 성능을 달성함

- Ablation Study
- 각 component 모두 성능 향상에 유효함

반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글