

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] Factorized RVQ-GAN for Disentangled Speech Tokenization
feVeRin 2025. 9. 22. 17:01반응형
Factorized RVQ-GAN for Disentangled Speech Tokenization
- Bottleneck을 factorize 하는 neural codec을 구성할 수 있음
- HAC
- Phoneme-level structure를 위한 pre-trained speech encoder와 lexical cue를 위한 text-based encoder의 objective를 활용하여 knowledge distillation objective를 구성
- Factorized bottleneck을 통해 phoneme align, word-level semantic에 대한 disentangled token set을 생성
- 논문 (INTERSPEECH 2025) : Paper Link
1. Introduction
- Neural Speech Codec (NSC)은 speech signal을 discrete token representation으로 convert 함
- 일반적으로 NSC는 phonetic (P-NSC), acoustic (A-NSC)로 나눌 수 있음
- 먼저 P-NSC는 two-stage pipeline을 따름:
- Self-Supervised Learning (SSL)을 통해 training 된 HuBERT와 같은 pre-trained Transformer encoder가 contextual acoustic frame embedding을 output 한 다음,
- Phoneme recognition task의 best layer에서 select 된 embedding에 $k$-means Vector Quantization (VQ)를 적용하여 discrete token을 생성함
- 해당 token은 phoneme label과 closely align 되므로 high-level linguistic structure를 가지지만, robotic sound와 speaker diversity가 부족하다는 단점이 있음
- SoundStream, EnCodec, DAC와 같은 A-SNC는 주로 Residual VQ-Generative Adversarial Network (RVQ-GAN) framework에 기반한 low-bitrate compression model을 통해 speech reconstruction을 수행함
- 여기서 encoder는 input speech를 acoustic frame embedding으로 mapping 하고 VQ layer를 통해 discrete token sequence로 quantize 함
- Decoder는 해당 token으로부터 speech를 reconstruct 하고 natural-sounding speech를 생성함
- BUT, A-NSC는 coherent linguistic, grammatical structure가 부족하다는 단점이 있음
-> 그래서 single framework 내에서 P-NSC, A-NSC를 combine 한 HAC (Hierarchical Audio Codec)을 제안
- HAC
- Phonetic, acoustic token 외에도 lexical abstraction을 도입하여 high-level linguistic structure, mid-level phonetic detail, fine-grained acoustic nuance를 jointly modeling
- 각 level에 대해 token space를 disentangle 하여 deeper linguistic understanding을 지원
< Overall of HAC >
- Lexicon token을 도입하여 P-NSC, A-NSC를 jointly modeling 한 unified speech codec
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- HAC은 downsampling CNN encoder $\text{ENC}$, 2개의 Transformer encoder $\text{TrfENC}_{p,l}$, 3개의 VQ module $\text{VQphn}, \text{RVQacoust}, \text{VQlex}$로 구성된 factorized bottleneck, upsampling CNN decoder $\text{DEC}$로 구성됨
- HAC은 $(x,y_{ali})$ tuple을 통해 training 되고, $x\in \mathbb{R}^{T}$는 speech utterance, $y_{ali}$는 force-aligned text transcript를 의미함
- 그러면 HAC은 $x$를 $\hat{x}$로 mapping 하고, 이때 $x$의 reconstruction은:
(Eq. 1) $Z=\text{ENC}(x)$
(Eq. 2) $Z_{Q_{a}},Q_{a}=\text{RVQacoust}(Z)$
(Eq. 3) $Z_{Q_{p}},Q_{p}=\text{VQphn}(\text{TrfENC}_{p}(Z))$
(Eq. 4) $Z_{Q_{l}}, Q_{l}=\text{VQlex}(\text{TrfENC}_{l}(Z))$
(Eq. 5) $Z_{Q}=Z_{Q_{p}}+Z_{Q_{a}}+Z_{Q_{l}}$
(Eq. 6) $\hat{x}=\text{DEC}(Z_{Q})$
- $Z,Z_{Q_{a}}, Z_{Q_{p}}, Z_{Q_{l}}\in\mathbb{R}^{F\times D}$
- $Z_{Q_{a}}, Z_{Q_{p}}, Z_{Q_{l}}$ : token set $Q_{a}\in\{1,...,A\}^{F\times N}, Q_{p}\in\{1,...,P\}^{F}, Q_{l}\in\{1,...,L\}^{F}$에 대한 codebook entry
- $F$ : acoustic frame 수, $D$ : frame embedding dimension - Codebook utilization을 maximize 하기 위해 VQ layer는 DAC의 low-dimensional code lookup process를 따름
- $\text{RVQacoust}$ module은 Residual Vector Quantization (RVQ)를 수행하고, $A$ codebook size를 가지는 $N$ VQ layer로 구성됨
- $\text{VQphn}, \text{VQlex}$는 각각 $P, L$ codebook size의 single VQ layer로 구성됨
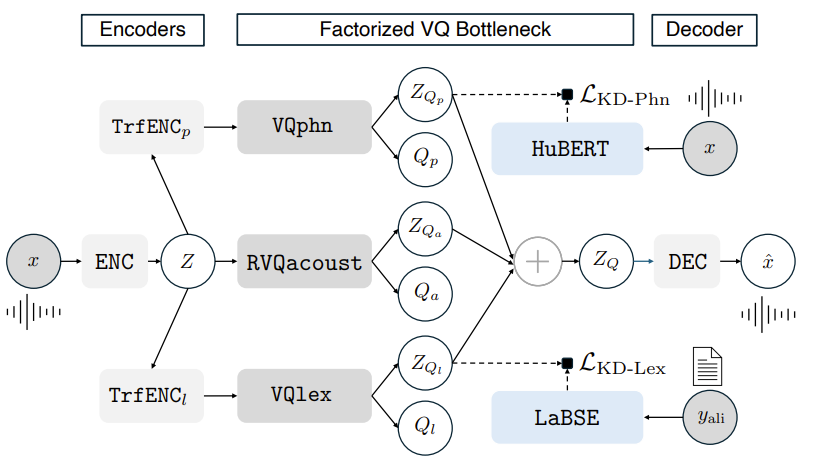
- HAC은 generator, discriminator로 구성된 adversarial framework에서 training 됨
- 그러면 overall training objective는 다음과 같이 구성됨:
- Faithful spectral recovery를 위한 frequency-domain reconstruction loss
- Natural-sounding output을 위한 adversarial loss
- Codebook entry update를 위한 codebook learning loss
- 추가적으로 각 token set이 intended information type을 encode 할 수 있도록, phonetic/lexical bottleneck에 Knowledge Distillation (KD) loss를 도입함
- $\mathcal{L}_{KD\text{-}Phn}$은 $Q_{p}$가 phoneme-level feature를 represent 하도록 함
- $\mathcal{L}_{KD\text{-}Lex}$는 $Q_{l}$이 word-level (lexical) information을 represent 하도록 함
- 즉, SpeechTokenizer를 따라 얻어지는 KD loss는:
(Eq. 7) $ \tilde{Z}_{Q_{p}}=Z_{Q_{p}}A_{p},\,\,\,\tilde{Z}_{Q_{l}}=Z_{Q_{l}}A_{l}$
(Eq. 8) $\mathcal{L}_{KD\text{-}Phn}=-\frac{1}{D'}\sum_{d=1}^{D'}\log\left(\sigma\left( \text{cos\_sim}\left(\tilde{Z}_{Q_{p}}[:,d],Z_{hubert}[:,d]\right)\right)\right)$
(Eq. 9) $\mathcal{L}_{KD\text{-}Lex}=-\frac{1}{D''}\sum_{d=1}^{D''}\log\left(\sigma\left( \text{cos\_sim}\left(\tilde{Z}_{Q_{l}}[:,d],Z_{labse}[:,d]\right)\right)\right)$
(Eq. 10) $Z_{hubert}=\text{Avg}(\text{HuBERT}(x)),\,\,\,Z_{labse}=\text{Avg}(\text{LaBSE}(y_{ali}))$
- $D', D''$ : 각각 HuBERT, LaBSE의 embedding dimension, $\text{cos_sim}(\cdot)$ : cosine similarity
- $\sigma$ : sigmoid function, $A_{p},A_{l}$ : dimension matching을 위한 projection matrix, $\text{Avg}(\cdot)$ : HuBERT/LaBSE의 모든 layer에 대한 representation average
- 이때 acoustic bottleneck $\text{RVQacoust}$는 decoder에 phonetic $Z_{Q_{p}}$, high-level lexical $Z_{Q_{l}}$ information을 제공하여 high-fidelity reconstruction을 위한 fine-grained acoustic detail에 focus 함
- HAC의 hyperparameter는 다음과 같음:
- Training input : 각 speech recording $x$의 length는 $3.8$s, sampling rate는 $16$kHz에 해당함
- Downsampling factor : $\text{ENC}$는 input time resolution을 $320\times$ reduce 함
- Frame embedding dimensionality : $D=1024$
- Phonetic and lexical codebook : $\text{VQphn},\text{VQlex}$ 모두 $16384$ codebook size ($14$-bit), $128$-dimensional codebook entry의 single VQ layer를 사용함
- Acoustic codebook : $\text{RVQacoust}$는 codebook size $A=1024$, $8$-dimensional codebook entry의 $N=7$ VQ layer로 구성됨
- 각 acoustic frame은 $7$ acoustic token, $1$ phonetic token, $1$ lexical token의 총 $9$ token으로 represent 됨
- $\text{TrfENC}_{p,l}$은 $4$ layer, $8$ attention head, $768$-dimensional embedding, $3072$ feed-forward dimensionality를 가짐
- 각 layer input에는 layer normalization이 적용되고, encoder에는 learnable convolutional positional embeddding이 포함됨
- 그러면 overall training objective는 다음과 같이 구성됨:
3. Experiments
- Settings
- Dataset : LibriSpeech
- Comparisons : SpeechTokenizer, DAC
- Results
- 전체적으로 HAC의 성능이 가장 뛰어남

- Phoneme Normalized Mutual Information (PNMI) 측면에서도 HAC은 우수한 성능을 보임

- VQ token에 대한 F1 Score 측면에서 HAC은 baseline 보다 더 나은 word detection을 보임

- Layer-wise comparison에서 HAC은 baseline에 비해 strong disentanglement를 보임

- $\text{VQlex}$는 word detector로 사용되는 경우, 다른 layer 보다 더 많은 codebook entry를 가짐
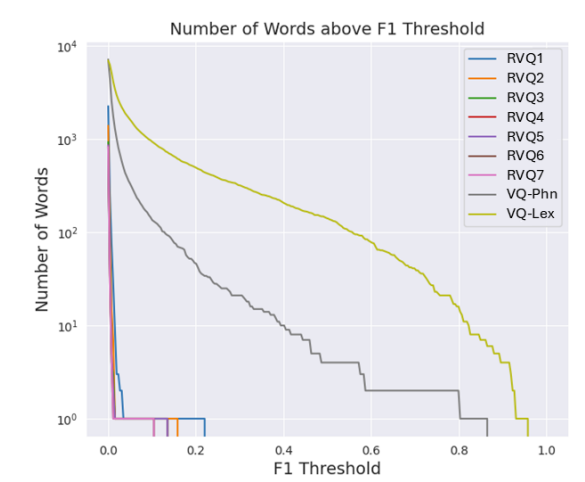
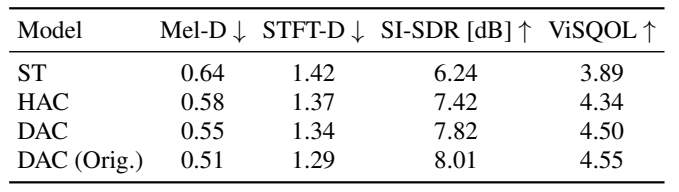
- Reconstruction 측면에서도 HAC은 우수한 성능을 달성함
반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글