

티스토리 뷰
Paper/Conversion
[Paper 리뷰] DiffEmotionVC: A Dual-Granularity Disentangled Diffusion Framework for Any-to-Any Emotion Voice Conversion
feVeRin 2025. 9. 8. 17:03반응형
DiffEmotionVC: A Dual-Granularity Disentangled Diffusion Framework for Any-to-Any Emotional Voice Conversion
- Emotion Voice Conversion은 content, speaker characteristic 간의 entanglement로 인해 어려움이 있음
- DiffEmotionVC
- Utterance-level emotional context와 frame-level acoustic detail을 모두 capture 하는 dual-granularity emotion encoder를 도입
- Gated cross-attention을 통해 emotion feature를 disentangle 하는 orthogonality-constrained encoder를 활용
- 추가적으로 multi-objective diffusion training을 통해 emotion discriminability를 향상
- 논문 (INTERSPEECH 2025) : Paper Link
1. Introduction
- Emotional Voice Conversion (EVC)은 original linguistic content와 speaker identity를 retain 하면서 expressed emotional state를 modify 하는 것을 목표로 함
- 이를 위해 기존에는 Generative Adversarial Network (GAN)-based model을 주로 활용했음
- 한편으로 최근의 Diff-HierVC, StableVC와 같은 diffusion model을 활용하면 unseen speaker에 대한 any-to-any VC가 가능함 - BUT, EVC는 여전히 insufficient speech quality와 unnatural emotion의 문제가 있음
- 특히 MFCC와 같은 emotion representation은 content information이 부족하여 emotion task의 성능을 크게 저하시킴
- 한편으로 Emotion2Vec과 같은 self-supervised learning framework를 통해 universal emotion representation을 학습할 수도 있지만, entirely suitable 하지 않음
- 이를 위해 기존에는 Generative Adversarial Network (GAN)-based model을 주로 활용했음
-> 그래서 EVC task를 위해 utterance-/frame-level encoding을 수행하는 DiffEmotionVC를 제안
- DiffEmotionVC
- Dual-granularity emotion encoder를 활용해 global prosody와 local spectral detail을 jointly modeling
- Orthogonally constrained condition encoder를 통해 emotion, speaker, content feature 간의 dynamic fusion을 지원
- Acoustic reconstruction fidelity, Contrastive metric learning, Perceptual loss optimization을 combine 한 3-phase diffusion training을 적용
< Overall of DiffEmotionVC >
- Multi-scale representation과 diffusion training을 활용한 EVC model
- 결과적으로 기존보다 우수한 conversion 성능을 달성
2. Method
- 논문은 emotional feature를 fully express하고 서로 다른 feature를 decoupling 하여 high-quality emotional speech를 생성하는 것을 목표로 함
- 먼저 source speech segment $X_{src}=g(c_{src},\text{spk}_{src}, \text{emo}_{src})$와 reference speech segment $X_{ref}=g(c_{ref},\text{spk}_{ref},\text{emo}_{ref})$의 pair가 주어진다고 하자
- 여기서 각 segment는 linguistic content $c$, speaker identity $\text{spk}$, emotional information $\text{emo}$로 구성되고, $g(\cdot)$은 generation process를 나타냄
- 그러면 DiffEmotionVC $G$는 conversion process $\hat{X}=G(c_{src},\text{src},\text{emo}_{ref})$를 수행함
- DiffEmotionVC는 specialized encoder를 통해 speaker, content, emotion feature를 추출하고 encoding함
- 해당 feature는 cross-attention mechanism을 통해 fuse 되고, orthogonal feature constraint를 통해 independently maintain 됨 - 추가적으로 contrastive loss function은 emotion discrimination ability를 향상하기 위해 사용되고, pre-trained HiFi-GAN vocoder는 mel-spectrogram을 time-domain signal로 reconstruct 하기 위해 사용됨
- 먼저 source speech segment $X_{src}=g(c_{src},\text{spk}_{src}, \text{emo}_{src})$와 reference speech segment $X_{ref}=g(c_{ref},\text{spk}_{ref},\text{emo}_{ref})$의 pair가 주어진다고 하자
- Feature Encoders
- Speaker Feature Extraction and Encoder
- 논문은 pre-trained Resemblyzer를 사용하여 256-dimensional speaker embedding $F_{spk}$를 추출함
- 이때 speaker encoder는 time-domain, frequency-domain path를 사용함:
- Time-domain path는 fully connected layer를 통해 static feature $F_{time}$을 추출함
- Frequency-domain path는 convolutional layer를 통해 local feature $F_{freq}$를 추출함
- Residual shortcut은 $F_{spk}$를 retain 하여 information transfer를 개선함
- 최종적으로는 각 component를 combine 하여 384-dimensional speaker representation $Z_{spk}$를 output 함
- 논문은 pre-trained Resemblyzer를 사용하여 256-dimensional speaker embedding $F_{spk}$를 추출함
- Content Feature Extraction and Encoder
- 논문은 pre-trained content feature model인 ContentVec을 사용하여 256-dimensional feature를 추출함
- ContentVec에는 content, speaker feature를 separate 하는 decoupling mechanism이 포함되어 있으므로, 논문에서는 각 feature에 대한 emotion을 decoupling 하는 것에 집중함 - 결과적으로 추출된 content feature는 content encoder를 통해 384-dimensional $Z_{cont}$로 mapping 됨
- 이때 encoder는 single fully connected layer로 구성됨
- 논문은 pre-trained content feature model인 ContentVec을 사용하여 256-dimensional feature를 추출함
- Emotion Feature Extraction and Encoder
- DiffEmotionVC는 pre-trained Emotion2Vec을 사용하여 emotional feature를 추출하고, 추출된 feature를 emotion encoder에 전달함
- Emotion feature encoder는 다음과 같이 동작함:
- 먼저 input frame-level feature $F_{fr}$과 utterance-level feature $F_{utt}$는 linear transformation을 통해 unified encoding dimension으로 mapping 됨
- 다음으로 global memory mechanism을 통해 fixed global memory matrix $M$을 학습하고 normalize 하여 emotional feature의 contextual information을 향상함
- 해당 global memory는 input feature와 combine 되어 Transformer model로 전달됨
- Transformer는 self-attention과 multi-layer encoder를 통해 feature 간의 complex relation을 추출함
- 추가적으로 global memory feature와 frame-level feature 간의 attention weight $A$를 compute 하여 frame-level feature를 개선함 - 이후 fully connected layer를 적용해 해당 feature를 further enhance 함
- Pre-training 시 emotion label의 부족으로 인해, 논문은 contrastive learning을 활용하여 emotional feature를 학습함
- 결과적으로 emotion encoder는 enhanced emotion feature $Z_{emo}$, contrastive feature $Z_{contrast}$를 output 하고, 이를 emotion-related task에 활용함:
(Eq. 1) $F'_{fr}=W_{fr}F_{fr},\,\,\,F'_{utt}=W_{utt}F_{utt}$
(Eq. 2) $M_{norm}=\frac{M}{||M||}$
(Eq. 3) $A=\text{softmax}\left(\frac{F'_{fr}M^{\top}_{norm}}{\sqrt{d_{k}}}\right)$
(Eq. 4) $Z_{emo}=\text{FC}(F'_{fr}+AM_{norm})$
(Eq. 5) $Z_{contrast}=\text{Normalize}(\text{FC}(Z_{emo}))$
- $W_{fr},W_{utt}$ : 각각 frame-level feature $F_{fr}$, utterance-level feature $F_{utt}$에 대한 weight matrix

- Condition Encoder
- Condition encoder는 emotion, content, speaker feature를 fuse 하기 위해 cross-attention과 orthogonal constraint를 사용하고, dual-path attention과 adaptive gating을 통해 independence를 preserve 함
- Cross-Attention Fusion
- Core fusion process는 서로 다른 feature modality 간의 relationship을 capture 하기 위해 Content-Emotion Attention과 Emotion-Speaker Attention을 활용함
- Content-Emotion Attention에서는 content representation $Z_{const}$가 query $Q$로 사용되고, emotion representation $Z_{emo}$는 key $K$, value $V$로 사용됨
- Emotion-Speaker Attention에서는 $Z_{emo}$가 $Q$, speaker representation $Z_{spk}$가 $K,V$로 사용됨
- Orthogonal Feature Constraints
- Feature entanglement를 방지하고 distinct feature space를 유지하기 위해, feature space를 constrain 하는 다음의 loss function을 도입함:
(Eq. 6) $ \mathcal{L}_{ortho}=\lambda_{1}\left|\left| Z^{\top}_{cont}Z_{emo}\right|\right|_{F}+\lambda_{2} \left|\left| Z_{emo}^{\top}Z_{spk}\right|\right|_{F}$
- $|| \cdot||_{F}$ : Frobenius norm으로써 feature matrix 간의 orthogonality를 measure 하는 역할
- $\lambda_{1},\lambda_{2}$ : coefficient
- Feature entanglement를 방지하고 distinct feature space를 유지하기 위해, feature space를 constrain 하는 다음의 loss function을 도입함:
- Adaptive Gating Mechanism
- Final representation은 emotion-enhanced feature와 learned attention weight를 사용해 다른 feature를 combine 하는 adaptive gating mechanism을 통해 얻어짐
- 이때 gating mechanism은:
(Eq. 7) $g=\sigma\left(W_{g}\left[Z_{emo};Z_{other}\right]\right)$
(Eq. 8) $Z_{final}=g\odot Z_{emo}+(1-g)\odot Z_{other}$
- $\sigma$ : sigmoid function, $W_{g}$ : learnable parameter matrix, $\odot$ : element-wise multiplication
- $g$ : dynamic weighting coefficient, $g\in (0,1)$ - Gating mechanism은 model이 input data에 따라 다양한 feature modality의 contribution을 dynamically balance 하도록 보장함
- Classifiers and Contrastive Learning
- DiffEmotionVC의 supervisory capacity를 향상하기 위해 논문은 speaker/emotion classifier를 도입함
- Speaker classifier는 speaker category를 predict 하고 emotion classifier는 cross-entropy loss를 통해 emotion recognition accuracy를 optimize 함
- 한편 emotion label에 의존하면 emotional feature의 fine-grained variation을 capture 하기 어려우므로, distinguishability를 개선하기 위해 contrastive loss를 적용함
- 이때 contrastive loss는 sample similarity를 adjust 하여 emotional label boundary를 build 함
- 특히 논문은 cosine-similarity-based contrastive learning을 활용하여 emotional feature 간의 차이를 학습함
- 결과적으로 사용되는 contrastive loss function은:
(Eq. 9) $ \mathcal{L}_{contrast}=-\frac{1}{B}\sum_{i=1}^{B}\log\left(\frac{\sum_{pos}\exp(\text{sim}_{pos})}{\sum_{pos}\exp(\text{sim}_{pos})+ \sum_{neg}\exp(\text{sim}_{neg})}\right)$
- Training Objectives
- 논문은 conditional mel-spectrogram generation을 위해 DDPM-based diffusion model을 사용함
- Total loss function은 다음과 같이 구성됨:
- Spectrum reconstruction loss (audio quality)
- Speaker classification loss (speaker category prediction)
- Emotion classification loss (emotion category prediction)
- Contrastive learning loss (emotion feature compactness)
- Orthogonal constraint loss (emotion/speaker/content feature independence)
- 이때 formulation은:
(Eq. 10) $\mathcal{L}_{total}=\mathcal{L}_{diff}+\lambda_{1}\mathcal{L}_{spk}+\lambda_{2}\mathcal{L}_{emo}+\lambda_{3}\mathcal{L}_{contrast}+\lambda_{4}\mathcal{L}_{ortho}$
- $\mathcal{L}_{diff}$ : diffusion model의 $L2$ loss
- $\mathcal{L}_{spk}$ : speaker classification loss
- $\mathcal{L}_{emo}$ : emotion cross-entropy loss
- $\lambda_{i}$ : weight coefficient
- Total loss function은 다음과 같이 구성됨:
3. Experiments
- Settings
- Dataset : Emilia, ESD
- Comparisons : StableVC, CycleGAN-EVC, StarGAN-EVC, Seq2Seq-EVC, EmoVox, Prosody2Vec, Any-to-Any-EVC
- Results
- 전체적으로 DiffEmotionVC의 성능이 가장 우수함

- Impact of Content Extraction Methods
- ContentVec을 사용했을 때 최상의 성능을 달성할 수 있음

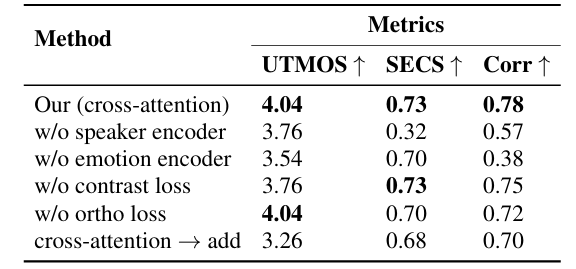
- Ablation Study
- 각 component를 제거하는 경우 성능 저하가 발생함
반응형
'Paper > Conversion' 카테고리의 다른 글
댓글