

티스토리 뷰
Paper/Conversion
[Paper 리뷰] Training-Free Voice Conversion with Factorized Optimal Transport
feVeRin 2025. 9. 2. 17:02반응형
Training-Free Voice Conversion with Factorized Optimal Transport
- $k$NN-VC를 training-free pipeline으로 수정할 수 있음
- MKL-VC
- $k$NN regression을 Monge-Kantorovich Linear solution에서 derive 된 WavLM embedding subspace 내의 factorized optimal transport map으로 replace
- Dimension 간 non-uniform variance를 처리하여 effective feature transformation을 보장
- 논문 (INTERSPEECH 2025) : Paper Link
1. Introduction
- Any-to-Any Voice Conversion (VC)는 speaker-reference pair에 대한 specific model 없이 voice identity를 reference voice와 match 시키는 것을 목표로 함
- 이때 utterance의 linguistic content는 unchange 되어야 하므로 conversion은 intonation, pitch, timbre와 같은 non-linguistic feature를 target으로 함
- 이를 위해 $k$NN-VC와 같이 $k$-Nearest Neighbors regression을 활용하여 VC를 수행할 수 있음
- 즉, source sequence embedding을 target sequence의 closest embedding으로 replace 한 다음, resulting sequence를 waveform output으로 decode 함
- BUT, $k$NN-VC는 1-minute reference에 대해서는 낮은 quality를 보이고, cross-lingual conversion 측면에서 한계가 있음
- 즉, source sequence embedding을 target sequence의 closest embedding으로 replace 한 다음, resulting sequence를 waveform output으로 decode 함
- 한편으로 $k$NN-VC의 nearest-neighbor search에서 perceptually close sound는 latent space 내에서 closely encode 됨
- 이는 WavLM과 같은 contrastive self-supervised learning model의 property와 연결될 수 있으므로, optimal transport theory를 도입할 수 있음
-> 그래서 $k$NN-VC를 linear optimal transport map을 활용하여 개선한 MKL-VC를 제안
- MKL-VC
- $k$NN regression을 linear optimal transport map으로 replace
- Multivariate Gaussian distribution 간의 optimal transport에 대한 explicit formula를 정의하고, quadratic transportation cost를 통해 minimize
< Overall of MKL-VC >
- Linear optimal transport map을 활용한 any-to-any VC model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- 논문은 encoder-converter-vocoder architecture를 따름
- 이때 $k$NN-VC와 마찬가지로 WavLM-large를 encoder로 사용하고 HiFi-GAN vocoder를 사용함

- Structure of WavLM Embeddings
- WavLM embedding에서는 위 그림과 같이 time-axis를 따라 numerical variability를 가지는 dimension의 small subset을 observe 할 수 있음
- 이는 두 WavLM embedding 간의 $L2$ (cosine) distance가 significant 100 component에 의해 primarily determine 되고 1024개의 component 중 900개는 ignore 된다는 것을 의미함
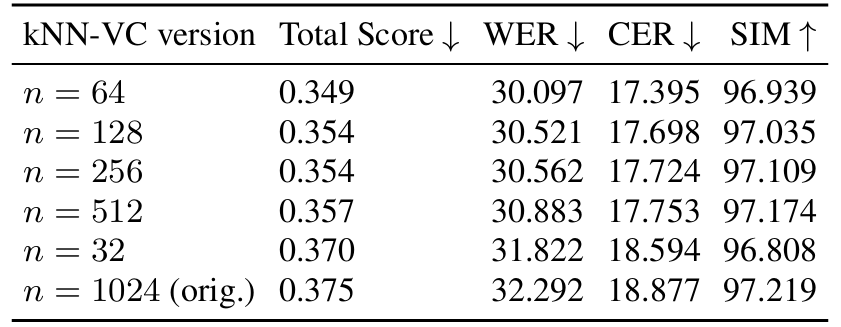
- 실제로 아래 표와 같이 time에 따른 standard deviation으로 sort 된 first $n$ componet에 대한 trimmed $k$NN-VC의 성능을 비교해 보면, trimmed $k$NN-VC는 baseline과 거의 동일한 성능을 가짐
- 한편으로 embedding의 less significant part를 random constant 등으로 replace 하는 경우, reconstruction quality 저하가 발생함
- 위의 characteristic으로 인해 WavLM embedding space에서 optimal transport의 applicability가 제한됨
- 따라서 optimal transport의 straightforward application은 suboptimal 할 수 있으므로, WavLM embedding의 inherent structure를 고려해야 함
- 이는 두 WavLM embedding 간의 $L2$ (cosine) distance가 significant 100 component에 의해 primarily determine 되고 1024개의 component 중 900개는 ignore 된다는 것을 의미함
- Factorized Optimal Transport
- Information loss를 방지하기 위해 논문은 factorized optimal transport를 도입함
- Factorized optimal transport는 standard deviation에 따라 dimension을 sort 하고 embedding을 lower-dimensional group으로 split 한 다음, 각 group에 대해 optimal transport problem을 separately solve 함
- 이를 통해 각 group 내의 feature value가 유사할 때 information을 discarding 하지 않으면서 transformation을 수행하는 transport plan을 얻을 수 있음
- 추가적으로 high-dimensional distribution을 smaller chunk로 split 하면 optimal transport computation이 tractable 하고 numerically stable 해짐
- 이때 각 group 내의 feature distribution은 approximately multivariate normal을 따름
- 두 개의 Gaussian distribution $p_{0}(x)=\mathcal{N}(x|\mu_{1},\Sigma_{1}), p_{1}(x)=\mathcal{N}(x|\mu_{2},\Sigma_{2})$가 있다고 하자
- Monge-Kantrovich Linear (MKL) map은 둘 사이의 quadratic optimal transport에 대한 analytical solution을 define 함:
(Eq. 1) $T(x)=\mu_{2}+\Sigma_{1}^{-1/2}\left(\Sigma_{1}^{1/2}\Sigma_{2}\Sigma_{1}^{1/2}\right)^{1/2} \Sigma_{1}^{-1/2}(x-\mu_{1})$ - 논문의 factorized approach는 $N$-dimensional input $x$를 dimension $K$의 $N/K$ subvector $x=[x^{(1)},...,x^{(N/K)}]$로 partition 함
- Mean vector $\mu_{1},\mu_{2}$도 마찬가지로 partition 됨
- Monge-Kantrovich Linear (MKL) map은 둘 사이의 quadratic optimal transport에 대한 analytical solution을 define 함:
- 한편으로 논문은 covariance matrix $\Sigma_{1},\Sigma_{2}$가 approximately block-diagonal 하다고 가정함
- 이때 각 block $i$에 대해 (Eq. 1)을 통해 $K$-dimensional MKL transport map $T^{(i)}$를 정의할 수 있음
- 그러면 factorized map $T:\mathbb{R}^{N}\rightarrow \mathbb{R}^{N}$은 해당 $K$-dimensional map의 direct product로 얻어짐:
(Eq. 2) $T(x)=\left[T^{(1)}(x^{(1)}),...,T^{(N/K)}(x^{(N/K)})\right]$
- 해당 map은 각 $K$-dimensional subspace 내에서 independent 하게 optimal transport를 수행하여 $p_{0}(x)$를 $p_{1}(x)$로 transport 함

- Validity of Gaussian Assumption
- 아래 그림과 같이 WavLM embedding segment와 동일한 mean, covariance를 가지는 Normal distribution 간의 Wasserstein distance를 비교해 보면
- Wasserstein distance의 identity of indiscernible에 따라 distance가 $0$에 가까우면 empirical distribution은 multivariate Normal을 따름
- 이때 lower MKL dimension $K$는 Gaussian distribution에 대해 smaller Wasserstein distance로 이어짐 - 추가적으로 Wasserstein distance는 WavLM dimension이 낮을수록 더 높은 값을 가짐
- 이는 dimension이 낮을수록 큰 standard deviation을 가지기 때문
- 따라서 standard deviation value가 $a$로 scaling 되면, distance도 $\text{d}(ax,ay)=a\text{d}(x,y)$에 따라 multiply 되므로, Wasserstein distance도 factor $a$에 따라 scaling 됨
- 결과적으로 Gaussian assumption은 lower variance 뿐만 아니라 모든 dimension에서 hold 됨
- Wasserstein distance의 identity of indiscernible에 따라 distance가 $0$에 가까우면 empirical distribution은 multivariate Normal을 따름

3. Experiments
- Settings
- Results
- 전체적으로 MKL-VC의 성능이 가장 뛰어남

- Cross-lingual conversion에서도 우수한 성능을 달성함

- Human evaluation 측면에서도 MKL-VC는 높은 평가를 받음

반응형
'Paper > Conversion' 카테고리의 다른 글
댓글