

티스토리 뷰
Paper/Conversion
[Paper 리뷰] ZSDEVC: Zero-Shot Diffusion-based Emotional Voice Conversion with Disentangled Mechanism
feVeRin 2025. 9. 17. 17:00반응형
ZSDEVC: Zero-Shot Diffusion-based Emotional Voice Conversion with Disentangled Mechanism
- Emotional Voice Conversion은 emotion accuracy와 speech distortion 문제가 존재함
- ZSDEVC
- Disentangled mechanism과 expressive guidance를 가지는 diffusion framework를 활용
- Large emotional speech dataset으로 model을 training
- 논문 (INTERSPEECH 2025) : Paper Link
1. Introduction
- Emotional Voice Conversion (EVC)는 linguistic content, speaker identity를 preserve 하면서 emotional expression을 modify 하는 것을 목표로 함
- 이를 위해 대표적으로 Generative Adversarial Network (GAN), AutoEncoder가 주로 활용됨
- GAN의 경우 adversarial mechanism을 활용하여 서로 다른 emotional data distribution 간의 direct mapping을 학습함
- AutoEncoder의 경우 speech를 linguistic content, speaker identity, emotional information과 같은 distinct representation unit으로 decompose 하여 conversion control을 수행함
- BUT, 해당 방식을 사용하더라도 여전히 EVC model은 suboptimal 함
- 한편으로 MSP-Podcast와 같은 large-scale emotional speech corpus에는 다양한 context, speaker, emotional state가 포함되어 있음
- 즉, 해당 dataset을 활용하면 EVC model의 성능을 크게 향상할 수 있음
- 이를 위해 대표적으로 Generative Adversarial Network (GAN), AutoEncoder가 주로 활용됨

-> 그래서 large-scale emotional dataset을 활용해 zero-shot ability를 개선한 ZSDEVC를 제안
- ZSDEVC
- Disentangled mechanism과 expressive guidance을 포함한 diffusion framework를 도입
- Large-scale non-parallel real-world emotional speech dataset을 활용하여 training을 수행
< Overall of ZSDEVC >
- Diffusion framework와 large-scale dataset을 활용한 zero-shot EVC model
- 결과적으로 기존보다 뛰어난 conversion 성능을 달성
2. Method
- Linguistic content $c$, speaker identity $spk$, emotion information $emo$, generative process $g(\cdot)$에 대해 source $X_{src}:=g(c_{src},spk_{src},emo_{src})$, reference $X_{ref}:=g(c_{ref},spk_{ref},emo_{ref})$의 pair가 주어진다고 하자
- 그러면 ZSDEVC $G$는 content, speaker identity는 preserve 하면서 $emo_{src}$에서 $emo_{ref}$로의 emotion transform을 수행하는 conversion process $\hat{X}=G(c_{src},spk_{src},emo_{ref})$를 수행함
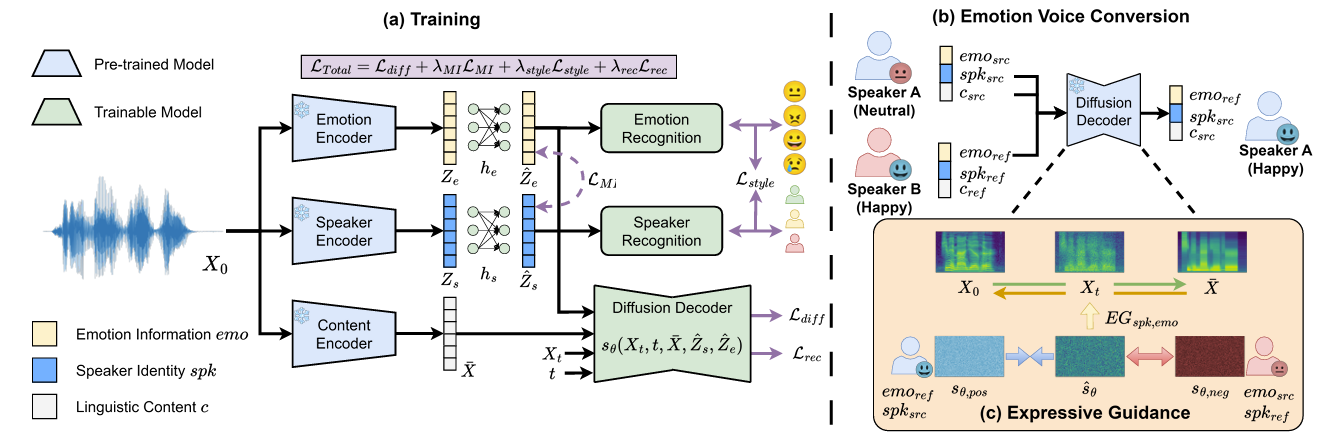
- 특히 논문은 unseen speech를 사용하는 zero-shot scenario를 목표로 함 - 먼저 multiple encoder는 disentanglement mechanism을 통해 distinct component를 추출하고, diffusion-based decoder는 해당 component를 기반으로 mel-spectrogram을 reconstruct 함
- 추론 시에는 result를 negative에서 positive condition으로 push 하기 위해 guidance method가 적용됨
- 최종적으로 pre-trained HiFi-GAN vocoder를 사용하여 generated mel-spectrogram을 time-domain signal로 convert 함
- 그러면 ZSDEVC $G$는 content, speaker identity는 preserve 하면서 $emo_{src}$에서 $emo_{ref}$로의 emotion transform을 수행하는 conversion process $\hat{X}=G(c_{src},spk_{src},emo_{ref})$를 수행함
- Encoders
- 3개의 pre-trained encoder는 linguistic content representation $c$, speaker identity, $spk$, emotional expression $emo$를 capture 하기 위해 사용됨
- Phoneme Encoding
- Linguistic content $\bar{X}$를 encode 하기 위해, 논문은 Grad-TTS의 pre-trained Transformer encoder를 adapt 함
- 이후 해당 encoder를 통해 input mel-spectrogram $X_{0}$를 speaker, emotion independent average-voice mel-feature로 convert 함
- 이때 각 phoneme-level mel-feature를 average phoneme-level mel-feature로 replace 함
- Speaker Encoding
- Speaker identity $Z_{s}\in\mathbb{R}^{256}$을 encode 하기 위해, 논문은 DiffVC를 따라 pre-trained speaker verification model을 사용함
- Emotion Encoding
- Emotional information $Z_{e}\in\mathbb{R}^{1024}$의 encoding은 Wav2Vec2-Large를 MSP-Podcast dataset에 fine-tuning 한 SSL-based SER system을 통해 얻어짐
- 최종적으로 각 representation은 speaker, emotion representation의 disentangling을 위해 $\hat{Z}_{s}=h_{s}(Z_{s}),\hat{Z}_{e}=h_{e}(Z_{e})$로 encoding 됨
- $h_{s},h_{e}$ : learnable parameter를 가지는 linear transformation
- Phoneme Encoding
- Diffusion Decoder
- ZSDEVC는 Stochastic Differential Equation (SDE)를 기반으로 한 diffusion framework를 사용해 주어진 representation $\bar{X},Z_{s},Z_{e}$에 condition 된 high-quality speech를 생성함
- Diffusion process는 real sample $X_{0}$를 timestep $t\in[0,1]$에 따라 $X_{t}$로 convert 함
- Forward process는 Gaussian noise를 add 하여 $t=1$일 때 average-voice mel-spectrogram $\bar{X}$로 terminate 됨
- Reverse process는 $\bar{X}$에서 score estimation $s_{\theta}(X_{t},t,\bar{X},\hat{Z}_{s},\hat{Z}_{e})$를 removing 하여 $X_{0}$를 생성함
- Parameter $\theta$에 대한 $s_{\theta}$는 added noise와 $s_{\theta}$ 간의 Mean Squared Error $\mathcal{L}_{diff}$를 minimize 하여 training 됨
- Diffusion process는 real sample $X_{0}$를 timestep $t\in[0,1]$에 따라 $X_{t}$로 convert 함
- Expressive Guidance
- Converted speech에 대한 diffusion model의 effectiveness를 향상하기 위해, 논문은 positive, negative direction score를 사용하여 reversed diffusion process를 manage 하는 Expressive Guidance를 도입함
- 이를 위해 추론 시 $s_{\theta}$를 $\hat{s}_{\theta}$로 modify 함:
(Eq. 1) $ \hat{s}_{\theta}=s_{\theta,neg}+\lambda_{EG}(s_{\theta, pos}-s_{\theta, neg})$ - $\lambda_{EG}>1$이면 generation process를 negative condition에서 positive condition으로 push 함
- Zero-shot EVC에서 positive condition은 source linguistic content $c_{src}$, source speaker identity $spk_{src}$, reference emotion information $emo_{ref}$를 사용함
- Negative condition은 $EG_{spk}$에 대해 $spk_{src}$를 $spk_{ref}$로 change 하거나 $EG_{emo}$에 대해 $emo_{ref}$를 $emo_{src}$로 change 함
- $EG$ : expressive guidance
- 이를 위해 추론 시 $s_{\theta}$를 $\hat{s}_{\theta}$로 modify 함:
- Disentangled Loss
- Emotion information과 speaker identity 간의 correlation을 reduce 하기 위해, ZSDEVC는 representation 간의 Mutual Information (MI) loss를 minimize 함
- 이때 MI loss는 $\mathcal{L}_{MI}=\hat{I}(\hat{z}_{s},\hat{z}_{e})$와 같음
- $\hat{I}$ : vCLUB을 사용한 unbiased estimation - 추가적으로 논문은 Speaker identity를 preserve 하고 disentangled emotion representation을 residing 하기 위해 다음의 2가지 auxiliary supervised model을 도입함:
- Disentangled speaker representation $\hat{z}_{s}$로부터 speaker identity를 predict 함
- Disentangled emotion representation $\hat{z}_{e}$로부터 emotion label (Neutral, Angry, Happy, Sad, Surprise)과 emotion attribute (Arousal, Valence)를 predict 함
- 해당 supervised model은 categorical prediction task에서는 negative log-likelihood loss를, regression task에서는 concordance correlation coefficient loss를 사용하는 $\mathcal{L}_{style}$을 minimize 함
- Diffusion-based decoder training을 위한 $\mathcal{L}_{diff}$ 외에도 논문은 mel-spectrogram reconstruction loss $\mathcal{L}_{rec}$를 도입하여 $X_{0},\hat{X}_{0}$ 간의 $L1$ norm을 compute 함
- $\hat{X}_{0}$ : $X_{t},\bar{X},s_{\theta}$에 대한 Tweedie's formula의 single-step approximation
- 이때 $\lambda_{rec}=(1-t^{2})$으로 설정하여, $t$가 커질수록 Gaussian noise를 add 하는 방식으로 noisy $X_{t}$에 대한 importance loss를 reduce 함 - 결과적으로 final objective loss는:
(Eq. 2) $\mathcal{L}_{total}=\mathcal{L}_{diff}+\lambda_{MI}\mathcal{L}_{MI}+\lambda_{style}\mathcal{L}_{style}+\lambda_{rec}\mathcal{L}_{rec}$
- $\lambda$ : hyperparameter
- 이때 MI loss는 $\mathcal{L}_{MI}=\hat{I}(\hat{z}_{s},\hat{z}_{e})$와 같음
3. Experiments
- Settings
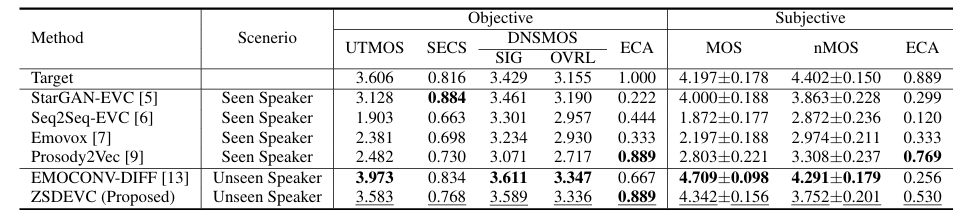
- Dataset : MSP-Podcast
- Comparisons : StarGAN-EVC, Seq2Seq-EVC, EmoVox, Prosody2Vec
- Results
- 전체적으로 ZSDEVC의 성능이 가장 뛰어남
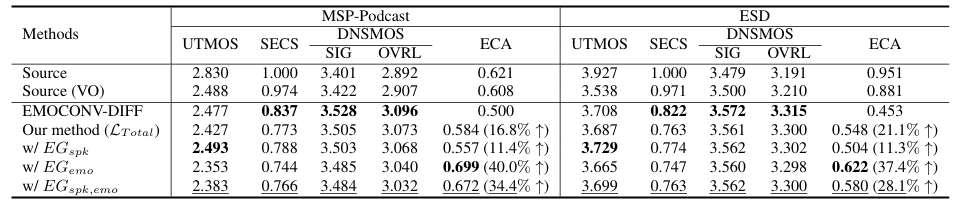
- Ablation Study
- 각 component를 제거하는 경우 성능 저하가 발생함
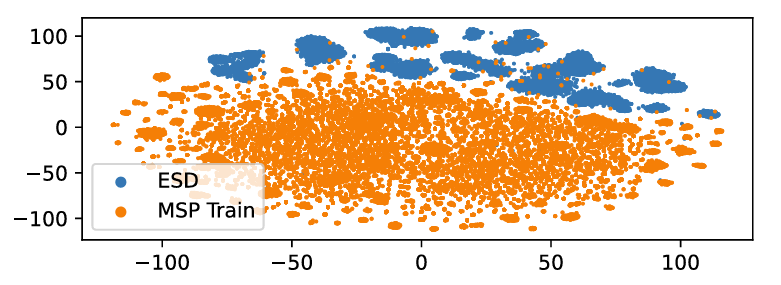
- Zero-Shot EVC
- $t$-SNE 측면에서 speaker embedding을 비교해 보면, 각각의 dataset은 distinct distribution을 가짐
반응형
'Paper > Conversion' 카테고리의 다른 글
댓글