

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] UniCodec: Unified Audio Codec with Single Domain-Adaptive Codebook
feVeRin 2025. 7. 1. 17:04반응형
UniCodec: Unified Audio Codec with Single Domain-Adaptive Codebook
- Multi-domain audio signal을 지원하는 audio codec이 필요함
- UniCodec
- 각 audio domain의 distinct characterisitc을 capture 하기 위해 domain-adaptive codebook과 Mixture-of-Expert strategy를 활용
- Auxiliary module 없이 codec의 semantic density를 enrich 하기 위해 self-supervised mask prediction modeling approach를 적용
- 논문 (ACL 2025) : Paper Link
1. Introduction
- Speech Language Model (SLM)은 speech modality와 text-based Large Language Model (LLM)을 integrate 하여 뛰어난 generation 성능을 달성함
- 이를 위해 high-rate speech signal을 discrete speech token의 finite set으로 convert 하는 discrete acoustic token model을 주로 활용함
- 대표적으로 SoundStream, DAC, EnCodec과 같은 neural audio codec은 각 quantizer가 previos quantizer의 residual에 대해 동작하는 multi-layer Residual Vector Quantization (RVQ)를 기반으로 함
- BUT, RVQ structure는 SLM의 complexity와 generation latency를 증가시킴
- 이때 WavTokenizer, Single-Codec과 같은 single-layer quantizer를 사용하면 LLM에서 rapid extraction을 지원할 수 있음
- 한편으로 ideal codec은 speech, music, sound 등의 다양한 audio domain에서 동작할 수 있어야 함
- BUT, 대부분의 neural codec은 domain-specific 하고 unified codec의 경우 domain 간의 distribution discrepancy로 인해 distinct characteristic을 capture 하기 어려움

-> 그래서 다양한 audio domain과 low-bitrate, high acoustic reconstruction을 지원하는 single codebook audio codec인 UniCodec을 제안
- UniCodec
- Partitioned Domain-Adaptive codebook과 Domain Mixture-of-Experts (MoE)를 활용하여 서로 다른 audio domain에 대한 distinct characteristic을 capture
- 추가적으로 additional module 없이 self-supervised, masked modeling approach를 적용해 semantic information을 enrich
< Overall of UniCodec >
- Speech, music, sound의 다양한 audio domain을 지원하는 single quantizer, unified codec
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- UniCodec은 single-layer encoder-VQ-decoder codec인 WavTokenizer를 기반으로 함
- 구조적으로는 input audio에서 latent feature representation을 생성하는 encoder, feature를 token으로 discretize 하는 quantizer, discrete token을 audio로 reconstruct 하는 decoder로 구성됨
- 이때 논문은 complex pattern을 capture할 수 있도록 encoder에 Transformer layer를 incorporate 하고 codebook utilization rate를 향상하여 efficienciy와 codebook usage를 maximize 함 - 추가적으로 multi-domain audio reconstruction을 위해 Partitioned Domain-Adaptive Codebook과 Domain Mixture-of-Expert (MoE) encoder structure를 도입함
- 이를 기반으로 UniCodec은 2-stage에 걸쳐 end-to-end training 됨:
- First acoustic training stage에서 model은 time, frequency domain에 대한 reconstruction loss를 optimize 하여 training 됨
- 추가적으로 서로 다른 resolution에 대한 discriminator로부터 얻어지는 perceptual loss를 활용함 - Second semantic training stage에서는 contrastive loss를 training objective에 add 함
- First acoustic training stage에서 model은 time, frequency domain에 대한 reconstruction loss를 optimize 하여 training 됨
- 구조적으로는 input audio에서 latent feature representation을 생성하는 encoder, feature를 token으로 discretize 하는 quantizer, discrete token을 audio로 reconstruct 하는 decoder로 구성됨

- Enhanced Encoder and Quantizer
- WavTokenizer의 encoder는 convolutional block과 two-layer LSTM과 final 1D convolutional layer로 구성되므로 feature 추출이 제한적임
- 이때 논문은 audio를 compact representation으로 encode 하면서 high-quality audio reconsturction을 보장하기 위해 encoder의 LSTM sequence modeling을 contextual Transformer architecture로 replace 함
- 해당 Transformer는 8 layer, 8 attention head, RoPE position encoding, GELU activation을 가지고, 512 hidden size와 2048 MLP dimension을 사용함 - 한편으로 model을 multiple audio domain을 포함한 training data로 scaling 하기 위해서는 codebook을 concurrently scaling 해야 함
- BUT, 이 경우 vector quantization process에서 codebook utilization을 optimize 하기 어려움
- 따라서 논문은 codebook utilization과 efficiency를 개선하기 위해 SimVQ algorithm을 채택함
- 이때 논문은 audio를 compact representation으로 encode 하면서 high-quality audio reconsturction을 보장하기 위해 encoder의 LSTM sequence modeling을 contextual Transformer architecture로 replace 함
- Domain-Adaptive Codebook
- Speech, music, sound의 3가지 domain을 unified audio tokenizer로 seamless integrate 하기 위해, 논문은 Partitioned Domain-Adpative Codebook을 도입함
- 이때 codebook은 3가지의 specialized region으로 divide 됨:
- $0$부터 $4095$ index까지의 first region은 speech domain
- $4096$부터 $8191$ index 까지의 second region은 music domain
- $8192$부터 $16383$ index 까지의 third region은 sound domain
- Training 시 model은 input sample의 domain에 해당하는 codebook entry만 update 하여 domain-specific feature가 accurately capture 되고 학습되도록 함
- 특히 Partitioned Codebook approach는 각 domain의 unique characteristic을 handle 하여 multi-domain audio representation에 대한 unified audio tokenizer를 구축할 수 있도록 함
- 이때 codebook은 3가지의 specialized region으로 divide 됨:
- Domain MoE
- Multiple audio domain의 data를 활용하여 codec을 training 하기 위해 논문은 Mixture-of-Experts (MoE)를 도입함
- 이때 MoE는 fine-grained expert를 기반으로 shared expert, routed expert를 designate 하여 사용함
- 이를 통해 computational efficiency를 보장하면서 domain-specific feature를 capture 할 수 있음 - 그러면 $t$-th token의 Feed-Forward Network (FFN) input $u_{t}$에 대해, FFN hidden output $h_{t}$는:
(Eq. 1) $ h_{t}=u_{t}+\sum_{i=1}^{N_{s}}\text{FFN}_{i}^{s}(u_{t})+\sum_{i=1}^{N_{r}}g_{i,t}\text{FFN}_{i}^{r} (u_{t})$
(Eq. 2) $g_{i,t}=\frac{g'_{i,t}}{\sum_{j=1}^{N_{r}}g'_{j,t}}$
(Eq. 3) $g'_{i,t}=\left\{\begin{matrix} s_{i,t}, & s_{i,t}\in\text{Topk}(s_{j,t}|1\leq j\leq N_{r},K_{r}) \\ 0, & \text{otherwise} \\ \end{matrix}\right.$
(Eq. 4) $s_{i,t}=\text{Sigmoid}\left(u_{t}^{\top}e_{i}\right)$
- $N_{s}, N_{r}$ : 각각 shared expert, routed expert 수, $\text{FFN}_{i}^{s}(\cdot), FFN_{i}^{r}(\cdot)$ : 각각 $i$-th shared expert, routed expert
- $g(i,t)$ : $i$-th expert의 gating value, $K_{r}$ : activated routed expert 수
- $s_{i,t}$ : token-to-expert affinity, $e_{i}$ : $i$-th routed expert의 centroid vector
- $\text{Topk}(\cdot,K)$ : $t$-th token과 모든 routed expert에 대해 calculate 된 affinity score의 $K$ highest score set - 여기서 논문은 $N_{s}=1,N_{r}=3, K_{r}=1$로 설정함
- 이때 MoE는 fine-grained expert를 기반으로 shared expert, routed expert를 designate 하여 사용함
- Semantic Training Stage
- High reconstruction ability를 preserving 하면서 semantic representation capability를 향상하기 위해, domain-agnostic masked modeling을 UniCodec에 적용함
- 먼저 convolutional layer에서 output feature의 일부를 mask 한 다음, contextual Transformers layer로 전달함
- Wav2Vec 2.0의 masking strategy를 따라 모든 time step에서 proportion $p$를 random sample 하여 starting index로 선정한 다음
- 각 sampled index에서 subsequent $M$ consecutive time을 masking 하여 overlapping span을 allow 함
- Contextual Transformer layer와 quantizer를 통해 얻어지는 masked time step $t$에 center 된 quantized output $q_{t}$는:
- $c_{t}$와 $K$ distractor를 포함한 $K+1$ convolutional latent representation $\hat{c}\in C_{t}$에서 unmasked convolutional latent representation $c_{t}$를 identify 하도록 함
- 여기서 distractor는 same utterance 내의 other masked time step에서 uniformly sample 됨 - 그러면 contrastive loss는:
(Eq. 5) $\mathcal{L}_{m}=-\log \frac{\exp\left(\text{sim}\left(q_{t},c_{t}\right)/K\right)}{\sum_{\hat{c}\in C_{t}} \exp\left(\text{sim}\left(q_{t},\hat{c}\right)/K\right)}$
- $ \text{sim}(a,b)=a^{\top}b/||a||||b||$ : quantized token, unmasked convolutional latent representation 간의 cosine similarity
- $c_{t}$와 $K$ distractor를 포함한 $K+1$ convolutional latent representation $\hat{c}\in C_{t}$에서 unmasked convolutional latent representation $c_{t}$를 identify 하도록 함
- 한편으로 reconstruction, masked modeling, contrastive loss를 scratch로 training 하는 것은 어려움
- Single-quantizer codec이 reconstruction과 mask prediction을 simultaneously perform 하지 못하기 때문 - 따라서 논문은 initial acoustic training stage에서 masking strategy를 omit 한 다음, reconstruction-related loss로 model을 먼저 training 함
- 이후 semantic training stage를 통해 codec이 high-level semantic information을 encapsulate 하도록 함
- 먼저 convolutional layer에서 output feature의 일부를 mask 한 다음, contextual Transformers layer로 전달함
3. Experiments
- Settings
- Dataset : LibriLight, LibriTTS, VCTK, CommonVoice, Jamendo, MusicDB, AudioSet
- Comparisons : DAC, EnCodec, WavTokenizer, SpeechTokenizer, TAAE, Mimi, BigCodec
- Results
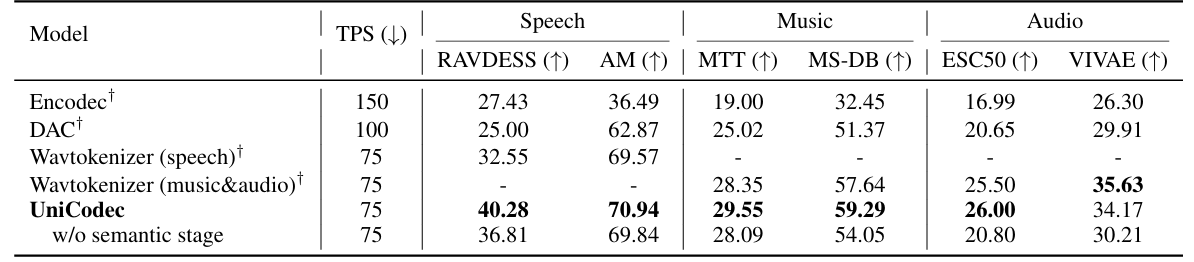
- UniCodec은 speech domain에 대해 가장 우수한 성능을 달성함

- Music, audio domain에 대해서도 우수한 reconstruction 성능을 보임

- MUSHRA test 측면에서도 UniCodec은 뛰어난 성능을 달성함

- Semantic Evaluation
- Semantic representation 측면에서도 UniCodec은 우수한 성능을 보임
- Ablation Study
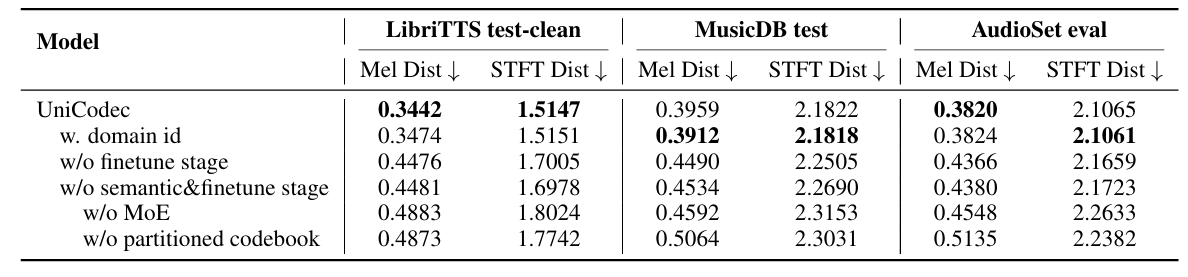
- 각 component를 제거하는 경우 성능 저하가 발생함
반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글