

티스토리 뷰
Paper/TTS
[Paper 리뷰] FastPitchFormant: Source-Filter based Decomposed Modeling for Speech Synthesis
feVeRin 2024. 12. 21. 09:55반응형
FastPitchFormant: Source-Filter based Decomposed Modeling for Speech Synthesis
- Text-to-Speech에서 large pitch-shift scale은 품질 저하와 speaker characteristic deformation을 일으킴
- FastPitchFormant
- Source-Filter theory를 기반으로 설계된 Feed-Forward Transformer model
- Text, acoustic feature를 개별적으로 modeling 하여 model이 두 feature 간의 relationship을 학습하는 것을 방지
- 논문 (INTERSPEECH 2021) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 주어진 sentence에 해당하는 natural voice를 합성하는 것을 목표로 함
- 특히 Feed-Forward Transformer (FFT) block은 mel-spectrogram의 synthetic quality를 향상하는데 중요한 역할을 함
- 대표적으로 FastSpeech, FastSpeech2와 같은 non-autoregressive FFT-based TTS model은 duration/pitch/energy와 같은 acoustic feature를 acoustic decoder에 적용하여 합성 품질을 개선함 - 한편으로 FastPitch의 경우 pitch value의 character-level을 변경하여 fine-grained prosody control이 가능함
- 특히 speaker characteristic을 preserve하면서 manipulated pitch로 음성을 생성하는 pitch shift를 지원할 수 있음
- BUT, FastPitch의 acoustic decoder는 text와 pitch information을 함께 처리하고 pitch-conditioned text information으로부터 음성을 생성함
- 따라서 decoder는 text, pitch 간의 relationship을 학습하게 됨 - 결과적으로 FastPitch는 average pitch에서 벗어나는 경우, pitch expressiveness와 speaker similarity가 떨어짐
- 이때 text/prosodic information을 개별적으로 처리하기 위해 다음의 방법을 고려할 수 있음:
- Unsupervised manner로 training된 additional neural network를 활용하여 acoustic feature의 latent variable을 추출하는 방법
- BUT, desired prosodic information이 latent variable에 포함되지 않을 수 있음 - Source-Filter theory를 활용하는 방법
- Vocal tract filter에 의해 formulate된 sound source와 formant frequency는 각각 fundamental frequency와 phonation에 영향을 미침
- BUT, 음성은 character 당 duration이 짧고 pitch 변화도 빈번하므로 modeling이 까다로움
- Unsupervised manner로 training된 additional neural network를 활용하여 acoustic feature의 latent variable을 추출하는 방법
- 특히 Feed-Forward Transformer (FFT) block은 mel-spectrogram의 synthetic quality를 향상하는데 중요한 역할을 함
-> 그래서 source-filter theory를 neural TTS에 접목한 FastPitchFormant를 제안
- FastPitchFormant
- Decomposed structure를 통해 개별적으로 modeling된 formant-/excitation-related representation을 사용하여 mel-spectrogram을 생성
- Source-Filter theory와 non-autoregressive FFT model에 적합한 learning objective를 설계
< Overall of FastPitchFormant >
- Source-Filter theory를 기반으로 한 non-autoregressive FFT-based TTS model
- 결과적으로 기존보다 뛰어난 합성 품질과 pitch controllability를 달성
2. Method
- FastPitchFormant는 text encoder, temporal predictor, formant/excitation generator, spectrogram generator로 구성됨
- 여기서 temporal predictor를 제외한 나머지는 모두 Feed-Forward Transformer (FFT) block stack으로 구성됨
- Temporal predictor는 2개의 1D convolutional layer로 구성되어 ground-truth duration/pitch를 예측함
- Multi-speaker TTS의 경우 speaker embedding lookup table을 통해 speaker embedding을 얻음
- 여기서 temporal predictor를 제외한 나머지는 모두 Feed-Forward Transformer (FFT) block stack으로 구성됨

- Text Encoder and Temporal Predictor
- Phoneme embedding vector는 phoneme sequence와 positional embedding이 있는 lookup embedding table로 represent 됨
- 이후 phoneme embedding vector는 text encoder로 전달되어 hidden embedding을 예측함
- 여기서 hidden embedding은 duration/pitch에 대한 2가지 temporal predictor에 대한 input으로 사용됨 - Pitch embedding은 predicted pitch value를 1D convolutional layer에 통과시켜 얻어지고,
- Hidden embedding과 pitch embedding은 각각 speaker embedding과 결합됨
- 이후 두 representation을 discretely upsample 하여 predicted duration과 align 함
- Upsampled phoneme representation을 $h\in \mathbb{R}^{D\times T}$, upsampled pitch representation을 $p\in\mathbb{R}^{D\times T}$라고 할 때, 각 $h,p$는 formant/excitation generator로 전달됨
- $D$ : vector dimension, $T$ : total frame 수
- 이후 phoneme embedding vector는 text encoder로 전달되어 hidden embedding을 예측함
- Formant and Excitation Generator
- 논문은 source-filter theory를 기반으로 formant/excitation generator를 도입함
- 먼저 formant generator는 $h$만을 사용하여 linguistic information과 같은 formant-related information을 포함한 formant representation을 예측함
- Excitation generator는 $h, p$를 모두 사용하여 prosody와 같은 excitation-related information을 포함하는 excitation representation을 예측함
- 특히 excitation representation이 $p$만을 사용하는 경우 pitch control accuracy가 저하됨
- 따라서 pitch control accuracy를 개선하기 위해 self-attention mechanism을 도입함 - 결과적으로 excitation generator의 first self-attention layer에서 attention matrix와 query $Q$는:
(Eq. 1) $\text{Attention}(Q,K,V)=\text{softmax}\left(\frac{QK^{T}}{\sqrt{d}}\right)V$
(Eq. 2) $Q=W_{Q}(h+p)+b_{Q}$
- $K,V$ : self-attention mechanism의 key, value
- $W_{Q}, b_{Q}$ : query에 대한 weight matrix, bias
- 특히 excitation representation이 $p$만을 사용하는 경우 pitch control accuracy가 저하됨
- Spectrogram Decoder
- Spectrogram decoder는 2개의 stacked FFT block과 3개의 Fully-Connected (FC) layer로 구성됨
- 여기서 각 FC layer는 target mel-spectrogram을 생성함
- First spectrogram은 first FC layer를 통해 project 된 formant와 excitation representation의 summation으로 얻어짐
- 이후 second/third mel-spectrogram을 생성하기 위해 formant, excitation representation의 summation이 stacked FFT block으로 전달되고, second/third FC layer에 의해 mel-spectrogram으로 project 됨
- 일반적으로 Source-Filter theory에서 source spectrum은 vocal tract filter로 multiply 되지만, FastPitchFormant는 log-scale mel-spectrogram을 사용하므로 multiplication을 summation으로 대체하여 사용함
- 결과적으로 각 FC layer output은 $L_{2}$ loss를 iterative loss로 포함하는 learning objective에 사용됨
- 해당 iterative loss로 인해 spectrogram decoder는 formant와 excitation representation의 summation에서 final mel-spectrogram을 생성하도록 training 됨 - 추론 시에는 third FC layer의 mel-spectrogram을 FastPitchFormant의 final output으로 사용함
- 여기서 각 FC layer는 target mel-spectrogram을 생성함
- Learning Objective
- FastPitchFormant의 learning objective는:
(Eq. 3) $\mathcal{L}_{final}=\frac{1}{TM}\sum_{i=1}^{3}\mathcal{L}_{spec_{i}}+ \alpha\mathcal{L}_{p}+\beta\mathcal{L}_{d}$
- $M$ : mel-spectrogram bin 수
- $\mathcal{L}_{spec_{i}}$ : target, $i$-th FC layer의 $i$-th predicted mel-spectrogram 간의 $L_{2}$ loss
- $\mathcal{L}_{p}, \mathcal{L}_{d}$ : 각각 target, predicted pitch/duration 간의 $L_{2}$ loss
3. Experiments
- Settings
- Dataset : Korean Speaker Dataset
- Comparisons : FastPitch
- Results
- Objective Evaluation
- 먼저 $\lambda$ semitone shifted pitch value $f_{\lambda}$는 다음과 같이 계산할 수 있음:
(Eq. 4) $f_{\lambda}=2^{\frac{\lambda}{12}}\times f_{0}$
- $f_{0}$ : original pitch value
- $\lambda \in\{-8, -6, -4, 0, 4, 6, 8\}$ - Pitch control accuracy 측면에서 FastPitchFormant (FPF)는 FastPitch (FP) 보다 wider range의 pitch control이 가능함
- 먼저 $\lambda$ semitone shifted pitch value $f_{\lambda}$는 다음과 같이 계산할 수 있음:

- Excitation, formant representation에 대한 mel-spectrogram을 비교해 보면, FPF의 formant, excitation generator는 vocal cord, vocal tract의 action을 modeling하는 것으로 나타남

- Mel-Cepstral Distortion (MCD) 측면에서도 FPF는 FP 보다 우수한 성능을 보임
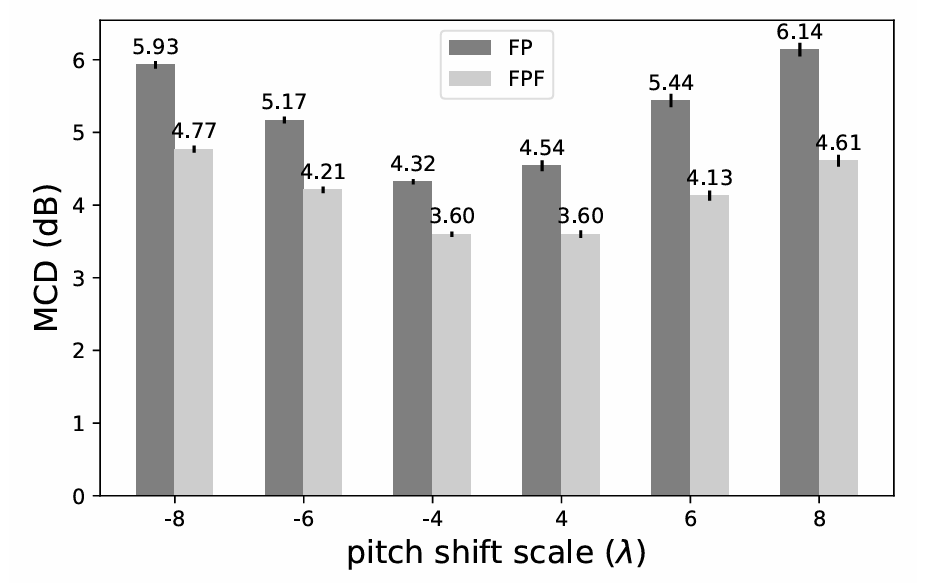
- $\lambda$에 대한 spectral envelope를 비교해보면, FPF는 original shape를 유지하지만 FP는 $\lambda$에 따라 distort 되는 것으로 나타남

- Subjective Evaluation
- MOS 측면에서도 FPF는 우수한 합성 품질을 보임

- Pitch-shifted speech에 대해서도 FP 보다 높은 MOS를 달성함
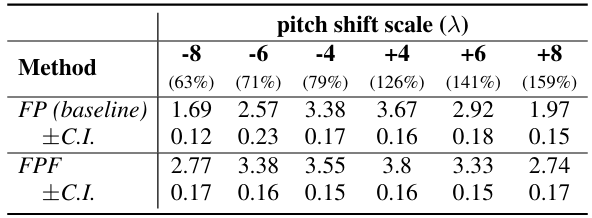
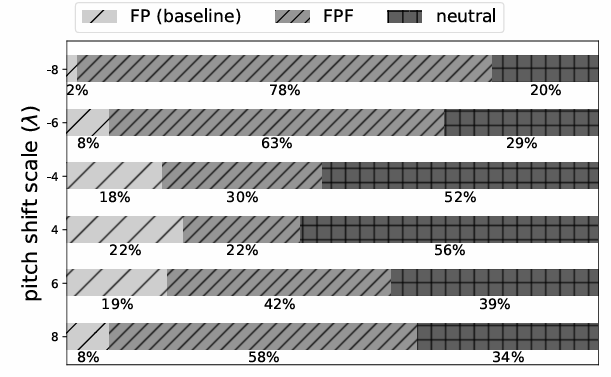
- Speaker Preservation
- Pitch-shifted scale가 작은 경우 ($|\lambda |\leq 4$)에는 speaker similarity의 차이가 크지 않음
- $| \lambda | \geq 4$인 경우에는 FPF가 FP 보다 speaker characteristic을 효과적으로 preserve 함
반응형
'Paper > TTS' 카테고리의 다른 글
댓글