

티스토리 뷰
Paper/SVS
[Paper 리뷰] PriorSinger: Singing Voice Synthesis Model with Prior Condition Cross Attention
feVeRin 2025. 3. 21. 17:56반응형
PriorSinger: Singing Voice Synthesis Model with Prior Condition Cross Attention
- Singing voice synthesis는 주어진 musical score를 기반으로 expressive, realistic singing을 생성하는 것을 목표로 함
- PriorSinger
- Denoising process 중에 prior cross-attention transformer를 사용하여 diffusion denoiser를 guiding
- Generated acoustic feature resolution을 향상하기 위해 diffusion denoiser 내에서 time/frequency domain에 대한 attention mechanism을 도입
- 추가적으로 rotary positional encoding을 통해 temporal/frequency positional information modeling을 지원
- 논문 (ICASSP 2025) : Paper Link
1. Introduction
- Singing Voice Synthesis (SVS)는 musical score에서 singing voice를 생성하는 것을 목표로 함
- 이때 SVS는 text-to-speech (TTS)와 달리 pitch/rhythm의 variation도 반영할 수 있어야 함
- 일반적으로 SVS는 acoustic model과 vocoder의 2가지 component로 구성됨
- Acoustic model은 musical note, lyrics와 같은 input으로부터 mel-spectrogram을 생성하고 vocoder는 synthesized mel-spectrogram을 waveform으로 변환함
- 특히 기존의 singing acoustic model은 $L1, L2$와 같은 loss function을 통해 acoustic feature를 reconstruction 함
- BUT, 해당 optimization은 incorrect unimodal dsitribution assumption에 기반하므로 blurry output을 생성할 수 있음 - 이를 해결하기 위해 VISinger, VISinger2와 같이 Generative Adversarial Network (GAN)을 도입할 수 있지만 discriminator로 인한 training instability 문제가 존재함
- 한편으로 Denoising Diffusion Probabilistic Model (DDPM)은 Gaussian white noise로부터 speech spectrogram을 iteratively restore 하는 방식으로 higher quality의 audio를 합성할 수 있음
-> 그래서 diffusion model을 기반으로 prior condition을 반영한 SVS model인 PriorSinger를 제안
- PriorSinger
- Lyric phoneme sequence 외에도 note duration/pitch와 같은 musical score information을 mel-spectrogram을 합성하기 위한 piror condition으로 encoding
- Diffusion denoiser를 통해 restore 된 mel-spectrogram의 time-frequency domain detail을 향상하기 위해 Prior Cross-Attention Transformer를 적용
- Prior condition을 query로 사용해 diffusion denoiser를 guiding 하는 Prior Condition Cross-Attention을 도입
- 추가적으로 musical score의 positional information을 활용하기 위해 Rotary Positional Encoding을 채택하여 embedding vector의 positional information을 encoding
< Overall of PriorSinger >
- Diffusion mechanism을 기반으로 Prior Cross-Attention Transformer를 적용한 SVS model
- 결과적으로 기존보다 뛰어난 합성 품질을 달성
2. Method
- PriorSinger에서 lyrics, pitch, duration과 같은 musical score information은 각각의 encoder를 통해 embedding token으로 변환됨
- Aligner는 embedding token을 spectrum과 align 하여 prior condition $\xi$를 얻음
- Diffusion denoiser는 noisy spectrum으로부터 generated mel-spectrogram을 restore 함
- Vocoder는 mel-spectrogram을 waveform으로 변환함

- Prior Condition Encoder
- Singing voice의 rhythmic quality를 향상하기 위해서는 lyrics 뿐만 아니라 pitch, note duration도 encoding 해야 함
- 먼저 lyrics encoder는 lyrics를 phoneme sequence로 변환하고 phoneme ID를 embedding sequence에 mapping 함
- 이후 embedding sequence는 stacked transformer block을 통해 linguistic hidden sequence로 변환됨
- 각 note pitch는 MIDI standard에 따라 pitch ID로 변환되고, note duration은 musical beat에 따라 quantize 되어 frame number (phoneme frame)으로 변환됨
- 추가적으로 slur encoder는 note가 slur 되었는지 여부를 modeling 함
- Pitch encoder와 slur encoder는 각각 pitch ID, slur condition을 embedding layer를 통해 pitch embedding sequence, slur embedding sequence로 변환함
- Note duration은 linear layer를 통해 duration embedding으로 변환됨 - 최종적으로 phoneme embedding $E_{Phone}$, pitch embedding $E_{Pitch}$, duration embedding $E_{Dur}$, slur embedding $E_{Slur}$를 add 한 다음, Rotary Position Embedding (RoPE)를 통해 note의 positional information을 encode 함
- 한편으로 embedding token $E$, mel-spectrogram 사이에서 most likely alignment attention map을 찾기 위해 Monotonic Alignment Search (MAS)를 적용함
- 여기서 alignment attention map을 통해 embedding token $E$를 prior condition $\xi$로 변환함
- 이를 mel-spectrogram에 대한 rough representation으로 취급할 수 있음 - 추론 시에는 target mel-spectrogram length가 invisible 하므로 alignment attention map을 계산하기 위해서는 duration predictor가 필요함
- 이후 Gaussian noise $X_{N}$, time step $t_{N}$, prior condition $\xi$를 diffusion denoiser input으로 전달하여 mel-spectrogram을 restore 함
- 여기서 alignment attention map을 통해 embedding token $E$를 prior condition $\xi$로 변환함
- 먼저 lyrics encoder는 lyrics를 phoneme sequence로 변환하고 phoneme ID를 embedding sequence에 mapping 함
- Diffusion Denoiser
- Diffusion denoiser는 encoder-decoder architecture를 따름
- 각 encoder/decoder block에는 2개의 residual network block (ResnetBlock), linear attention, 2D convolution/deconvolution (Conv2D/DeConv2d)가 포함됨
- 이때 encoder block은 time-frequency domain에서 embedding token을 compress 하고 decoder block은 compressed token을 restore 함
- 추가적으로 논문은 encoder/decoder block 사이에 stacked prior cross-attention transformer를 도입함
- 해당 prior cross-attention transformer는 temporal-frequency dimension에서 self-attention을 수행하여 mel-spectrogram quality를 향상함
- Prior cross-attention을 도입하는 경우 prior condition을 통해 reverse diffusion process를 facilitate 할 수 있음

- Prior Cross-Attention Transformer
- Prior Cross-Attention Transformer는 frequency self-attention (FA), temporal self-attention (TA), prior condition corss-attention (CA), Multi-Layer Perceptron (MLP)를 포함함
- 먼저 $C, T,F$를 각각 channel size, frame 수, frequency dimension이라고 하자
- Frequency self-attention의 경우, input feature $X\in \mathbb{R}^{B\times T \times F\times C}$는 $X'\in\mathbb{R}^{BT\times F\times C}$로 reshape 됨
- 이후 input feature는 linear layer를 통해 query $Q_{FA}\in\mathbb{R}^{BT\times F\times C}$, key $K_{FA} \in\mathbb{R}^{BT\times F\times C}$, value $V_{FA}\in\mathbb{R}^{BT\times F\times C}$로 변환됨
- 그러면 $Q_{FA},K_{FA}$는 layer normalization, RoPE와 함께 다음과 같이 적용됨:
(Eq. 1) $Q'_{FA}=\text{RoPE}(\text{LayerNorm}(Q_{FA}))$
(Eq. 2) $K'_{FA}=\text{RoPE}(\text{LayerNorm}(K_{FA}))$ - 결과적으로 FA는 다음과 같이 계산됨:
(Eq. 3) $A_{FA}=\text{Linear}\left(\text{Softmax}\left(\frac{Q'_{FA}\times {K'_{FA}}^{\top}}{\sqrt{C}}\right)\times V_{FA}\right)$
- $\top$ : matrix transpose
- (Eq. 3)과 같이 FA 계산 시, time impact는 고려하지 않고 channel 간의 frequency point만 고려함
- 마찬가지로 TA 계산은 FA와 동일하지만 frequency 대신 temporal dimension 만을 고려함 - TA 이후에는 prior condition cross-attention이 적용됨
- 먼저 $m$-stacked ResnetBlock과 Conv2D를 사용하여 time-frequency domain에서 prior condition $\xi$를 $\xi'$로 compress 해 TA의 output dimension $A_{TA}$ match 하도록 함
- 여기서 $\xi'$ query 역할을 하고 linear layer, layer normalization, RoPE를 통과해 $Q'_{CA}\in\mathbb{R}^{B\times TF\times C}$를 생성함
- $K_{CA}\in\mathbb{R}^{B\times TF\times C}, V_{CA}\in\mathbb{R}^{B\times TF\times C}$는 $A_{TA}$를 3-linear layer를 통과시켜 얻어짐
- $K'_{CA}$는 $K_{CA}\in\mathbb{R}^{B\times TF\times C}$를 layer normalization, RoPE에 전달하여 얻어짐 - 결과적으로 CA output은:
(Eq. 4) $A_{CA}=\text{Linear}\left(\text{Softmax}\left(\frac{Q'_{CA}\times {K'_{CA}}^{\top} }{\sqrt{C}}\right)\times V_{CA}\right)$
- CA는 entire time-frequency domain의 all point를 처리하여 denoising process를 guide 함
- 먼저 $C, T,F$를 각각 channel size, frame 수, frequency dimension이라고 하자
- Loss Function
- PriorSinger는 duration loss, prior loss, diffusion loss에 대한 combined loss function을 통해 training 됨
- 먼저 duration predictor를 사용하여 각 phoneme의 duration을 추정하고, 이때 loss function은:
(Eq. 5) $\mathcal{L}_{dur}=||\log(d_{pred})-\log(d_{GT})||^{2}$
- $d_{GT},d_{pred}$ : 각각 ground-truth/estimated phoneme duration - Prior condition $\xi$는 prior loss function을 통해 추정됨:
(Eq. 6) $\mathcal{L}_{prior}=||\xi-\text{mel}_{GT}||^{2}$
- $\text{mel}_{GT}$ : ground-truth mel-spectrogram - Diffusion loss는:
(Eq. 7) $\mathcal{L}_{diff}=||D(X_{t},t,\xi)-X_{0}||^{2}$
- $X_{t}$ : step $t$에서의 state, $D(X_{t},t,\xi)$ : denoising 이후의 state - 결과적으로 PriorSinger의 combined loss function은:
(Eq. 8) $\mathcal{L}_{comb}=\mathcal{L}_{diff}+\mathcal{L}_{dur}+\mathcal{L}_{prior}$
- 먼저 duration predictor를 사용하여 각 phoneme의 duration을 추정하고, 이때 loss function은:
3. Experiments
- Settings
- Dataset : PopCS
- Comparisons : CoMoSpeech
- Results
- 전체적으로 PriorSinger의 성능이 가장 우수함

- Mel-spectrogram 측면에서도 PriorSinger는 richer spectral detail을 가짐
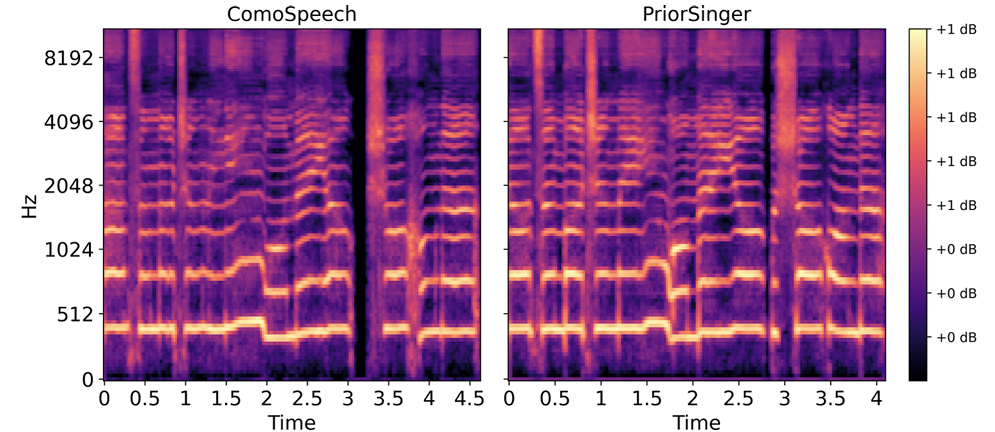
- Ablation Study
- 각 component를 제거하는 경우 성능 저하가 발생함

반응형
'Paper > SVS' 카테고리의 다른 글
댓글