

티스토리 뷰
Paper/TTS
[Paper 리뷰] ClariTTS: Feature-ratio Normalization and Duration Stabilization for Code-Mixed Multi-Speaker Speech Synthesis
feVeRin 2024. 10. 9. 10:30반응형
ClariTTS: Feature-ratio Normalization and Duration Stabilization for Code-Mixed Multi-Speaker Speech Synthesis
- Text-to-Speech model에서 code-mixed text는 speaker-related feature에 source language에 대한 linguistic feature가 포함될 수 있으므로 unnatural accent를 생성할 수 있음
- ClariTTS
- Flow-based text-to-speech model에 Feature-ratio Normalized Affine Coupling Layer를 적용
- Speaker와 linguistic feature를 disentangle 하여 target speaker의 accent가 포함되는 것을 방지 - 추가적으로 stable duration prediction을 보장하기 위해 Duration Stabilization Training Objective를 도입
- Flow-based text-to-speech model에 Feature-ratio Normalized Affine Coupling Layer를 적용
- 논문 (INTERSPEECH 2024) : Paper Link
1. Introduction
- FastSpeech2, Glow-TTS, FastPitch와 같은 end-to-end Text-to-Speech (TTS)는 human-like speech를 합성할 수 있음
- BUT, multi-lingual TTS는 multi-lingual dataset을 수집하는 것이 어렵기 때문에 mono-lingual data를 결합하여 사용함
- 이때 mono-lingual data로 multi-lingual TTS model을 학습하면, source language speaker의 accent가 target language에 포함되는 speaker-language entalgement 문제로 인해 unnatural accent가 발생함 - 따라서 speaker identity와 linguistic information을 효과적으로 disentangle 해야 함
- 대표적으로 SANE-TTS는 domain adversarial training을 사용하고, CrossSpeech는 acoustic representation을 speaker-dependent/speaker-independent로 나누어 사용함 - 한편으로 cross-lingual TTS 외에도 한 sentence에 두 개 이상의 language가 포함된 code-mixed text도 고려할 수 있음
- 일반적으로 code-mixed TTS는 encoder structure를 변경하거나 pre-trained model의 additional feature를 활용하거나 transliteration으로 text input을 enriching 하는 방식을 사용함
- BUT, 해당 방식은 pre-trained external model 성능이나 transliteration에 의해 크게 좌우됨
- BUT, multi-lingual TTS는 multi-lingual dataset을 수집하는 것이 어렵기 때문에 mono-lingual data를 결합하여 사용함
-> 그래서 disentangle 문제를 해결하여 code-mixed TTS의 naturalness를 개선한 ClariTTS를 제안
- ClariTTS
- 먼저 flow-based TTS model인 VITS를 기반으로 affine coupling layer에 normalization-based conditioning method를 적용
- Training phase에서 speaker와 language embedding에 대해 separately predicted parameter를 사용하여 각 input을 normalize 한 다음, speaker/language-normalized result를 add 함
- 여기서 speaker/language-normalized result를 adding 하는 비율을 적응적으로 결정 - 결과적으로 normalizing flow는 speaker/language-dependent data distribution을 speaker/language-independent latent prior distribution으로 변환함
- 이때 논문은 speaker/language normalization을 개별적으로 사용하므로 training 과정에서 speaker/language feature를 explicitly disentangle 할 수 있음
- 추론 시 affine coupling layer는 denormalization을 통해 적절한 speaker/language information을 inject 함
- Training phase에서 speaker와 language embedding에 대해 separately predicted parameter를 사용하여 각 input을 normalize 한 다음, speaker/language-normalized result를 add 함
- 추가적으로 speaker-language entanglement를 해결하고 robust duration predictor를 구성하기 위해 duration stabilization training objective를 도입
- 구체적으로, mini-batch에서 paired input text, speaker embedding, language embedding을 사용하여 intra-speaker duration을 예측함
- 이후 batch dimension을 따라 speaker embedding을 randomly shuffle 하고 shuffled speaker embedding으로 cross-speaker duration을 예측함
- 해당 shuffled speaker embedding에는 mini-batch의 paired speaker embedding과 다른 speaker identity/language information이 포함됨
- 먼저 flow-based TTS model인 VITS를 기반으로 affine coupling layer에 normalization-based conditioning method를 적용
< Overall of ClariTTS >
- Feature-ratio normalization $FRN$, Feature-ratio denormalization $DFRN$과 Duration stabilization training objective를 활용한 code-mix TTS model
- 결과적으로 기존보다 뛰어난 합성 품질을 달성
2. Related Work
- Glow-TTS, VITS와 같은 flow-based TTS model은 affine coupling layer와 같은 invertible transformation을 통해 simple prior distribution와 complex data dsitribution 간의 bijective mapping을 학습함
- 이때 Speaker-Normalized Affine Coupling Layer (SNAC)을 고려할 수 있음
- Training 시 speaker embedding $e_{s}$의 예측된 평균/표준편차 parameter로 input을 explicitly nomarlize 하고, 추론 시 desired speaker embedding으로 input을 denormalize 하는 방식
- 여기서 normalization $g$와 denormalization $g^{-1}$은:
(Eq. 1) $g(x;c)=\frac{x-m_{\theta}(c)}{\exp(v_{\theta}(c))}$
(Eq. 2) $g^{-1}(x;c)=x\odot \exp(v_{\theta}(c))+m_{\theta}(c)$
- $x\in\mathbb{R}^{D}$ : input, $c$ : condition, $\odot$ : element-wise product
- $m_{\theta}, v_{\theta}$ : $c$로부터 평균/표준편차를 얻기 위한 simple linear projection - 그러면 위를 따라 speaker normalization $SN$과 speaker denormalization $SDN$을 얻을 수 있음
- e.g.) $SN(x;e_{s})=g(x;e_{s}),\,\,\, SDN(x;e_{s})=g^{-1}(x;e_{s})$ - 다음으로 SNAC layer의 forward transformation은 affine coupling layer에 $SN$을 적용하여 얻어짐:
(Eq. 3) $y_{1:d}=x_{1:d}$
(Eq. 4) $y_{d+1:D}=SN(x_{d+1:D};e_{s})\odot\exp(s_{\theta}(SN(x_{1:d};e_{s}))) + b_{\theta}(SN(x_{1:d};e_{s}))$ - Inverse transformation은:
(Eq. 5) $x_{1:d}=y_{1:d}$
(Eq. 6) $x_{d+1:D}=SDN\left(\frac{y_{d+1:D}-b_{\theta}( SN(y_{1:d};e_{s}))}{\exp(s_{\theta}(SN(y_{1:d},e_{s})))};e_{s}\right)$
- 결과적으로 위 과정은 forward process에서 speaker information을 제거하고 inverse process에서 제공하는 것으로 볼 수 있음
- 특히 SNAC은 speaker-dependent data distribution을 speaker-independent prior distribution으로 변환하여 model이 inverse process를 통해 desired speaker-dependent data distribution을 얻을 수 있도록 함 - 따라서 논문은 위 방식을 training 시 각 speaker/language embedding에 의해 normalize 된 input을 add 하고, 추론 시 denormalized input을 add 하는 speaker-language conditioning method로 확장함
- 즉, $SN, SDN$을 각각 $FRN, FRDN$으로 대체하여 speaker/language embedding에 의해 input을 selectively normalize/denormalize 하도록 함
- 이때 Speaker-Normalized Affine Coupling Layer (SNAC)을 고려할 수 있음
3. Method
- Text encoder, duration predictor, normalizing flow, posterior encoder/decoder를 가지는 VITS를 backbone으로 사용함
- 먼저 각 language에 대해 native character와 one-hot language ID를 사용하고, reference encoder를 통해 linear-scale spectrogram에서 speaker-related feature를 추출함
- 해당 reference encoder output은 speaker embedding으로 사용됨 - 추가적으로 빠른 추론을 위해 VITS의 decoder를 multi-stream iSTFT-VITS decoder로 대체하고, 안정적인 추론을 위해 stochastic duration predictor를 deterministic duration predictor로 대체함
- 위를 기반으로 ClariTTS는 다음의 구성요소를 도입:
- Normalzing flow의 affine coupling layer에서 $FRN, FRDN$을 적용
- Duration predictor를 위한 duration stabilization training objective를 사용
- 이때 ClariTTS는 speaker와 language feature를 disentangle 하는 것을 목표로 하므로 normalizing flow와 duratino predictor에만 speaker/language embedding을 제공함
- 먼저 각 language에 대해 native character와 one-hot language ID를 사용하고, reference encoder를 통해 linear-scale spectrogram에서 speaker-related feature를 추출함
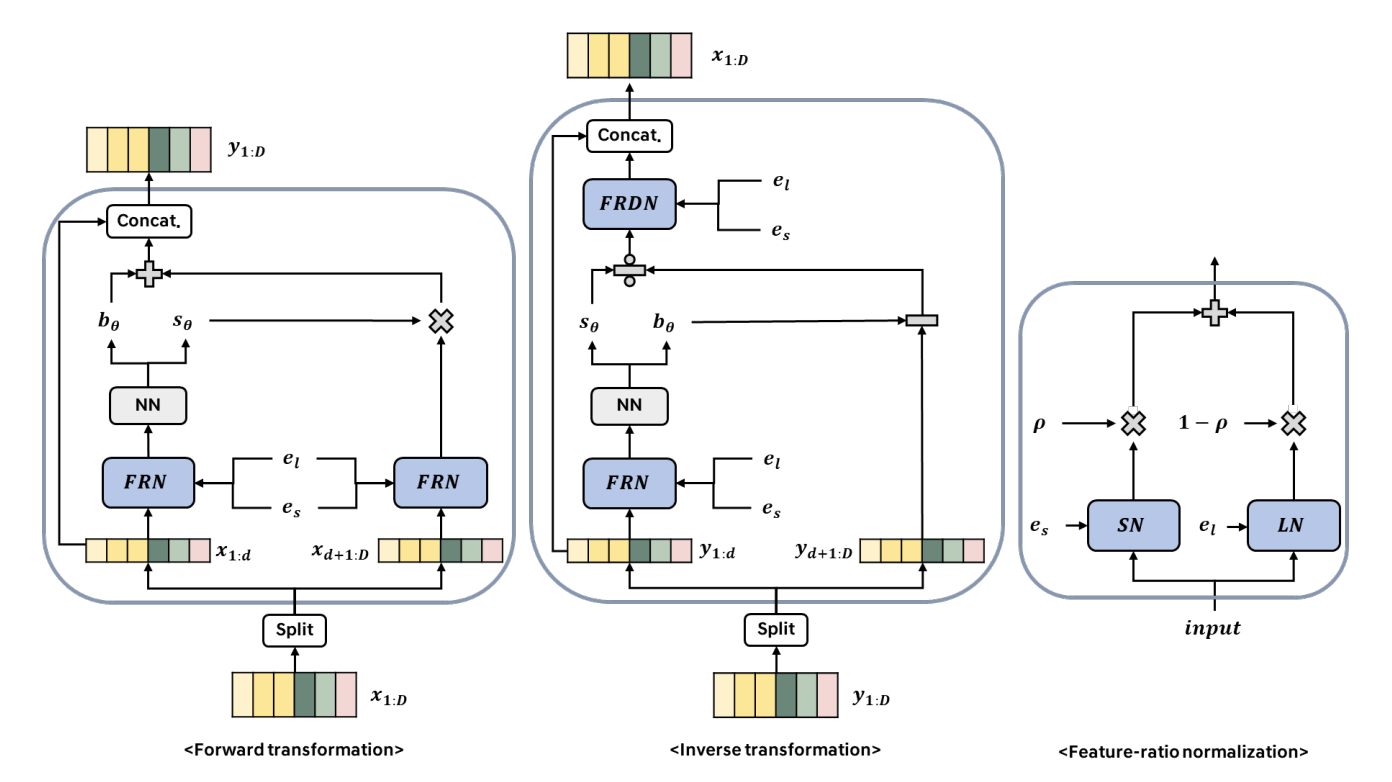
- Feature-ratio Normalized Affine Coupling Layer
- ClariTTS architecture는 SNAC에서 $SN, SDN$을 $FRN, FDRN$으로 대체하여 구성됨
- $FRN, FDRN$은 각각 speaker embedding $e_{s}$와 language embedding $e_{l}$에서 얻은 평균/표준편차 parameter로 normalize/denormalize 됨
- (Eq. 1), (Eq. 2)의 $c$에 $e_{l}$를 대입하면, language normalization $LN$과 language denormalization $LDN$을 얻을 수 있음
- 여기서 shared convolutional neural network $W_{r}$에서 $e_{s},e_{l}$을 사용하여 feature-ratio $\rho$를 얻음:
(Eq. 7) $\rho=\sigma\left(W_{r}(m_{\theta}(e_{s}),v_{\theta}(e_{s}))+W_{r} (m_{\theta}(e_{l}),v_{\theta}(e_{l}))\right)$
- $\sigma$ : sigmoid function - 그러면 $FRN$은:
(Eq. 8) $FRN(x;e_{s,l})=\rho(SN(x;e_{s}))+(1-\rho)(LN(x;e_{l}))$
- $FRDN$은 $FRN$의 inverse transformation - 결과적으로 affine coupling layer의 forward transformation은 다음과 같이 유도됨:
(Eq. 9) $y_{1:d}=x_{1:d}$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, y_{d+1:D}=FRN(x_{d+1:D};e_{s,l})\odot \exp(s_{\theta}(FRN(x_{1:d};e_{s,l})))+b_{\theta}(FRN (x_{1:d;e_{s,l}}))$
- $s_{\theta},b_{\theta}$ : 각각 scale, bias function, $d<D$ - Inverse transformation은:
(Eq. 10) $x_{1:d}=y_{1:d}$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, x_{d+1:D}=FRDN\left(\frac{y_{d+1:D}-b_{\theta}(FRN(y_{1:d};e_{s,l}))}{\exp(s_{\theta}( FRN(y_{1:d};e_{s,l})))}; e_{s,l}\right)$
- 여기서 shared convolutional neural network $W_{r}$에서 $e_{s},e_{l}$을 사용하여 feature-ratio $\rho$를 얻음:
- 한편으로 coupling structure로 인해 Jacobian은 lower triangular matrix로 얻어짐
- 이때 Jacobian은:
(Eq. 11) $\frac{\partial y_{d+1:D}}{\partial x_{d+1:D}}=\text{diag}\left(\exp(s_{\theta}(FRN(x_{1:d};e_{s,l})))\odot \frac{\rho\exp(v_{\theta}(e_{l})) + (1-\rho)\exp(v_{\theta}(e_{s}))}{\exp(v_{\theta}(e_{s}))\exp(v_{\theta}(e_{l}))} \right)$
(Eq. 12) $\frac{\partial y}{\partial x}=\begin{bmatrix}
I_{d\times d} & 0 \\
\frac{\partial y_{d+1:D}}{\partial x_{1:d}} & \frac{\partial y_{d+1:D}}{\partial x_{d+1:D}} \\
\end{bmatrix}$
- $I_{d\times d}$ : identity matrix - Simplicity를 위해 논문은 normalizing flow를 volume-preserving transformation으로 설계함
- 즉, scale function $\exp(s_{\theta}(FRN(x_{1:d};e_{s,l}))) = 1$이 됨 - 따라서 ClariTTS의 normalizing flow에 대한 Jacobian log-determinant는:
(Eq. 13) $\log \left|\det\frac{\partial f_{\theta}(x)}{\partial x} \right|=\log \sum_{j}\frac{\rho \exp(v_{\theta}(e_{l})_{j})+(1-\rho)\exp(v_{\theta}(e_{s})_{j})}{\exp(v_{\theta}(e_{s})_{j}) \exp(v_{\theta}(e_{l})_{j})}$
- 이때 Jacobian은:
- Affine coupling layer는 $FRN$을 통해 forward transformation에서 speaker, language information을 제거함
- 이때 $FRN$은 각 hidden channel에 대해 $\rho$를 사용하여 speaker, language information을 adaptively eliminate 함
- 이를 통해 normalizing flow는 data distribution을 speaker/language-independent latent prior distribution으로 변환 가능 - $FRDN$은 inverse transformation 동안 target speaker/language embedding을 통해 information을 제공함
- 이를 통해 prior distribution을 speaker/language-dependent data distribution으로 변환
- 이때 $FRN$은 각 hidden channel에 대해 $\rho$를 사용하여 speaker, language information을 adaptively eliminate 함
- Duration Stabilization Training Objectives
- Cross-lingual TTS 성능을 향상하기 위해서는 speaker-language entanglement 문제를 해결해야 함
- 따라서 ClariTTS는 $FRN, FRDN$ 외에도 duration predictor를 stabilize 하고 speaker-language entanglement를 완화하는 training objective를 도입함
- 구체적으로, mini-batch가 주어졌을 때 $(\text{text}, \text{audio}, e_{s}, e_{l})$과 같은 paired input이 있다고 하자
- 그러면 duration predictor는 intra-speaker duration $d_{intra}$를 생성함:
(Eq. 14) $d_{intra} = W_{d}(x;e_{s,l})$
- $W_{d}$ : duration predictor, $x$ : input text embedding - 이때 mini-batch에서 $e_{s}$를 randomly shuffle 하여 shuffled speaker embedding $\bar{e}_{s}=\text{shuffle}(e_{s})$를 얻을 수 있음
- $\bar{e}_{s}$를 통해 duration을 생성하는 경우, $\bar{e}_{s}$는 $e_{s}$와 비교하여 other speaker나 language에 대한 information을 포함하고 있으므로 duration predictor는 cross-speaker duration $d_{cross}$를 생성한다고 볼 수 있음 - 따라서 duration stabilization loss는:
(Eq. 15) $\mathcal{L}_{dur}=\mathcal{L}_{d_{intra}}+\mathcal{L}_{d_{cross}}= \text{MSE}(d_{mas},d_{intra})+\text{MSE}(d_{mas},d_{cross})$
- $\text{MSE}$ : Mean Squared Error, $d_{mas}$ : monotonic alignment search를 통한 duration
- 그러면 duration predictor는 intra-speaker duration $d_{intra}$를 생성함:
- $\mathcal{L}_{dur}$를 통해 duration predictor는 speaker embedding에서 linguistic feature를 추출하지 않고도 speaker-related feature를 추출할 수 있음
- 결과적으로 해당 duration predictor는 speaker와 language embedding을 개별적으로 활용하기 때문에 robust cross-lingual TTS가 가능
4. Experiments
- Settings
- Results
- Intra-lingual/Cross-lingual/Code-mixed 모두에서 ClariTTS가 가장 우수한 성능을 달성함

- Parameter 수 측면에서 ClariTTS가 가장 효율적임

반응형
'Paper > TTS' 카테고리의 다른 글
댓글