

티스토리 뷰
Paper/Vocoder
[Paper 리뷰] LPCNet: Improving Neural Speech Synthesis Through Linear Prediction
feVeRin 2023. 12. 15. 11:17반응형
LPCNet: Improving Neural Speech Synthesis Through Linear Prediction
- 음성 합성 모델은 실시간 동작을 위해 많은 GPU를 필요로 함
- LPCNet
- 음성 합성 효율성 향상을 위해 linear prediction을 활용한 WaveRNN의 변형 모델
- 동일한 네트워크 크기에 대해 WaveRNN 보다 더 높은 품질과 낮은 복잡도를 달성
- 논문 (ICASSP 2019) : Paper Link
1. Introduction
- Neural network 기반의 음성 합성 모델은 고품질의 음성 합성을 가능하게 함
- WaveNet과 같은 1세대 모델들은 수백억 개의 GFLOPS를 제공하는 high-end GPU를 기반으로 구성됨
- 따라서 GPU가 없고 배터리가 제한된 모바일 환경에서 활용할 수 있는 음성 합성 모델이 요구됨
- Low bitrate vocoder와 같은 parametric 모델은 꾸준히 제시되었지만 음성 품질의 한계가 있음
- Linear prediction을 사용하면 음성의 spectral envelope를 모델링하기에 효율적이지만 모델 설계의 어려움이 있음
-> 그래서 spectral envelope 모델링의 부담을 줄인 효율적인 음성 합성 모델인 LPCNet을 제안
- LPCNet
- 대부분의 capacity를 spectrally flat excitation (vocal tract response)을 모델링하는 데 사용할 수 있음
- 더 적은 수의 neuron으로 모델의 복잡성을 줄이고 음성 합성 품질을 개선
< Overall of LPCNet >
- Linear prediction과 RNN을 활용한 음성 합성 모델
- WaveRNN의 변형을 통한 spectral envelope 모델링의 부담 완화
2. WaveRNN
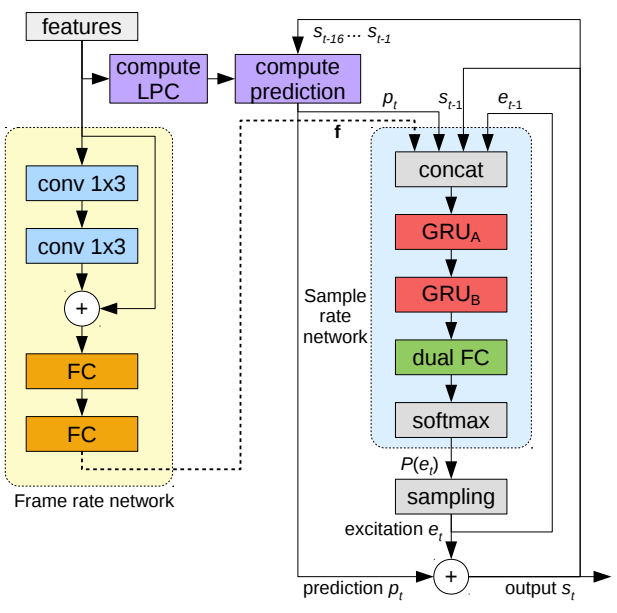
- Baseline인 WaveRNN은 conditioning parameter $\mathbf{f}$와 이전 audio sample $s_{t-1}$을 입력으로 사용해 output sample에 대한 이산 확률 분포 $P(s_{t})$를 생성
- GRU와 2개의 fully-connected layer로 구성되고 최종적으로 softmax activation을 사용함
- $\mathbf{x}_{t} = [s_{t-1};\mathbf{f}]$
- $\mathbf{u}_{t} = \sigma(\mathbf{W}^{(u)} \mathbf{h}_{t-1} + \mathbf{U}^{(u)}\mathbf{x}_{t})$
- $\mathbf{r}_{t} = \sigma(\mathbf{W}^{(r)} \mathbf{h}_{t-1} + \mathbf{U}^{(r)} \mathbf{x}_{t})$
- $\tilde{\mathbf{h}}_{t} = tanh( \mathbf{r}_{t} \circ (\mathbf{W}^{(h)} \mathbf{h}_{t-1}) + \mathbf{U}^{(h)} \mathbf{x}_{t})$
- $\mathbf{h}_{t} = \mathbf{u}_{t} \circ \mathbf{h}_{t-1} + (1-\mathbf{u}_{t-1}) \circ \tilde{\mathbf{h}}_{t}$
- $P(s_{t}) = softmax (\mathbf{W}_{2} \; relu(\mathbf{W}_{1} \mathbf{h}_{t}))$ - 합성된 output sample $s_{t}$는 확률 분포 $P(s_{t})$로부터 sampling 하여 얻어짐
- $\mathbf{W}^{(\cdot)}, \mathbf{U}^{(\cdot)}$ : GRU의 weight matrix
- $\sigma(x) = \frac{1}{1+e^{-x}}$ : sigmoid function
- $\circ$ : element-wise vector multiply
- GRU와 2개의 fully-connected layer로 구성되고 최종적으로 softmax activation을 사용함
3. LPCNet
- LPCNet은 WaveRNN을 개선하여 구성됨
- 모델의 입력은 20개의 feature (18개의 Bark-scale cepstral coefficient, 2개의 pitch parameter)로 제한
- Low-bitrte coding의 경우, cepstrum과 pitch parameter는 quantize 되어 사용됨
- Text-to-Speech의 경우, cepstrum과 pitch parameter는 추가적인 neural network를 사용하여 text에서 계산됨
- Conditioning Parameters
- Frame rate network로써 20개의 feature는, filter size가 3인 2개의 convolution layer를 통과하여 5 frame의 receptive field를 생성함
- 두 convolution layer의 output은 residual connection에 더해진 다음, 2개의 fully-connected layer를 통과함
- Frame rate network는 sample rate network에서 사용되는 128차원 conditional vector $\mathbf{f}$를 생성
- Pre-emphasis and Quantization
- WaveNet과 같은 합성 모델은 8-bit $\mu$-law quantization을 사용하여 output sample 값을 256개로 줄임
- 음성 신호의 energy는 대부분 low frequency에 집중되는 경향이 있기 때문
- 특히 $\mu$-law white quantization noise는 16kHz 신호의 경우 high frequency에서 들리는 경향이 있음
- 대부분의 경우 output을 16-bit로 확장하여 문제를 해결함 - 대신 LPCNet에서는, training data에 first-order pre-emphasis filter를 적용하여 문제를 해결
- $E(z) = 1-\alpha z^{-1}$ ($\alpha = 0.85$) - 이후 합성 출력은 Nyquist rate가 16dB만큼 감소하도록 하는 inverse (de-emphasis) filter를 사용하여 filtering 됨
- $D(z) = \frac{1}{1-\alpha z^{-1}}$
-> 결과적으로 perceptive noise를 줄이고 8-bit $\mu$-law output를 생성할 수 있게 함
- 음성 신호의 energy는 대부분 low frequency에 집중되는 경향이 있기 때문
- Linear Prediction
- 음성 생성을 위한 vocal tract response 모델링은 간단한 all-pole linear filter로 표현될 수 있음
- $s_{t}$를 time $t$에서의 신호라고 하면, 이전 sample을 기반으로 한 linear prediction은:
- $p_{t} = \sum^{M}_{k=1} a_{k} s_{t-k}$
- $a_{k}$ : 현재 frame에 대한 linear prediction coefficient (LPC)의 $M$번째 order - Prediction coefficient $a_{k}$는 18-band Bark-frequency cepstrum을 linear-frequency power spectral density (PSD)로 변환하여 계산됨
- 이후 PSD는 inverse FFT를 사용하여 auto-correlation으로 변환됨
- Predictor는 auto-correlation으로부터 Levinson-Durbin algorithm을 활용하여 계산을 수행 - 계산된 LPC는 cepstrum의 낮은 resolution으로 인해 input 신호로부터 직접 계산된 것만큼 정확하지는 않음
- 대신 open-loop filtering에 비해 network가 compensate 하는 방식으로 학습될 수 있다는 이점이 있음
- $s_{t}$를 time $t$에서의 신호라고 하면, 이전 sample을 기반으로 한 linear prediction은:
- Linear predictor의 확장으로써, sample value가 아닌 excitation (prediction residual)을 예측하도록 할 수 있음
- 일반적으로 excitation이 pre-emphasize 된 신호보다 amplitude가 작기 때문에 $\mu$-law quantization의 noise도 약간 감소됨
- 이때 network는 이전 sampled excitation $e_{t-1}$과 이전 신호 $s_{t-1}$, 현재 예측 $p_{t}$를 입력으로 사용
- $e_{t-1}$만 사용하는 open-loop synthesis의 경우 합성 품질이 떨어지기 때문에 $s_{t-1}, p_{t}$이 함께 포함됨
- Output Layer
- Output 확률을 계산하기 위해 2개의 fully-connected layer를 element-wise weighted sum과 결합 (DualFC)
- $dual\_fc(\mathbf{x}) = \mathbf{a}_{1} \circ tanh(\mathbf{W}_{1}\mathbf{x}) + \mathbf{a}_{2} \circ tanh(\mathbf{W}_{2} \mathbf{x})$
- $\mathbf{W}_{1}, \mathbf{W}_{2}$ : weight matrix, $\mathbf{a}_{1}, \mathbf{a}_{2}$ : weighting vector - DualFC layer를 사용했을 때 동일한 복잡도를 가지는 일반적인 fully-connected layer에 비해 음성 품질이 향상됨
- DualFC는 output값이 $\mu$-law quanitzation 범위 내에 속하는지 여부를 판별하는 2번의 비교와 tanh를 통한 1번의 최종 판별을 의미함
- DualFC의 output은 softmax activation과 함께 사용되어 $e_{t}$에 대해 가능한 excitation의 확률 $P(e_{t})$를 계산
- Sparse Matrices
- 모델의 복잡도를 줄이기 위해 GRU에서 sparse matrix를 사용함
- Vectorization을 위해 일반적인 element-by-element sparsness 대신 block-sparse matrix를 활용
- Desne matrix에서 시작하여 원하는 sparseness를 가질 때까지 magnitude가 가장 작은 block이 점진적으로 0으로 바뀜
- $16 \times 1$ block을 사용했을 때 가장 효과적인 vectorization이 가능 - Non-zero block에 대해, sparse matrix에 diagonal term을 포함
- 수평/수직 정렬이 되어있지 않더라도 diagonal term은 vector operand와 element-wise multiplication을 하기 때문에 vectorize 하기 쉬움
- Embedding and Algebric Simplifications
- Scalar sample value를 network에 제공하기 전에 $\mu$-law 값의 이산적 특징을 활용해 embedding matrix $\mathbf{E}$를 학습
- Embedding은 각 $\mu$-law level을 vector에 mapping 하는 non-linear function
- Embedding matrix를 시각화해 보면, embedding이 $\mu$-law scale을 linear 하게 변환하는 것을 학습하는 것을 확인할 수 있음
- Embedding matrix의 곱을 GRU의 non-recurrent weight $\mathbf{U}^{(\cdot)}$의 submatrix와 미리 계산하여 모델의 복잡도 증가를 방지할 수 있음
- $\mathbf{U}^{(u,s)}$를 $s_{t-1}$ input sample의 embedding에 적용되는 column들로 구성된 $\mathbf{U}^{(u)}$라고 가정하면:
- 새로운 embedding matrix $\mathbf{V}^{(u,s)} = \mathbf{U}^{(u,s)}\mathbf{E}$는, sample $s_{t-1}$을 update gate computation의 non-recurrent term에 mapping 함
- 미리 계산된 9개의 $\mathbf{V}(\cdot, \cdot)$ matrix에 대해, 모든 gate ($u,r,h$)와 모든 embedded input ($s,p,e$)에 대해 동일한 변환이 적용됨
-> 결과적으로 embedding contribution은 gate, embedded input 당 한 번의 추가 작업으로 단순화됨 - 비슷하게 frame conditioning vector $\mathbf{f}$의 contribution은 전체 frame에 대해 constant한 것으로 단순화 할 수 있음
- 각 GRU gate에 대한 $\mathbf{f}$의 contribution, $\mathbf{g}^{(\cdot)} = \mathbf{U}^{(\cdot)}\mathbf{f}$는 frame당 한 번으로 계산됨
- $\mathbf{U}^{(u,s)}$를 $s_{t-1}$ input sample의 embedding에 적용되는 column들로 구성된 $\mathbf{U}^{(u)}$라고 가정하면:
- 위의 simplification들을 통해 GRU의 모든 non-recurrent input의 계산 비용을 무시할 수 있음
- 따라서, 이를 통해 앞선 WaveRNN의 식들을 재작성하면:
- $\mathbf{u}_{t} = \sigma (\mathbf{W}_{u} \mathbf{h}_{t} + \mathbf{v}^{(u,s)}_{s_{t-1}} + \mathbf{v}^{(u,p)}_{p_{t-1}} + \mathbf{v}^{(u,e)}_{e_{t-1}} + \mathbf{g}^{(u)} )$
- $\mathbf{r}_{t} = \sigma ( \mathbf{W}_{r} \mathbf{h}_{t} + \mathbf{v}^{(r,s)}_{s_{t-1}} + \mathbf{v}^{(r,p)}_{p_{t-1}} + \mathbf{v}^{(r,e)}_{e_{t-1}} + \mathbf{g}^{(u)} ) $
- $\tilde{\mathbf{h}}_{t} = tanh (\mathbf{r}_{t} \circ (\mathbf{W}_{h} \mathbf{h}_{t}) + \mathbf{v}^{(h,s)}_{s_{t-1}} + \mathbf{v}^{(h,p)}_{p_{t-1}} + \mathbf{v}^{(h,e)}_{e_{t-1}} + \mathbf{g}^{(h)} ) $
- $\mathbf{h}_{t} = \mathbf{u}_{t} \circ \mathbf{h}_{t-1} + (1-\mathbf{u}_{t}) \circ \tilde{\mathbf{h}}_{t}$
- $P(e_{t}) = softmax (dual\_fc (GRU_{B}(\mathbf{h}_{t})))$ - $\mathbf{v}_{i}^{(\cdot, \cdot)}$ : $\mathbf{V}^{(\cdot,\cdot)}$ matrix에 대한 column vector $i$의 lookup
- $GRU_{B}(\cdot)$ : WaveRNN의 ReLU activation을 포함한 fully-connected layer를 대체하는 non-sparse GRU
- 따라서, 이를 통해 앞선 WaveRNN의 식들을 재작성하면:
- Sampling from Probability Distribution
- Output 분포에서 직접 sampling을 하는 경우, noise가 발생할 수 있음
- 일반적으로는 voice sound에 대한 constant $c=2$를 logit에 곱하는 것으로 문제를 해결함
- 대신 LPCNet에서는:
- Constant $c = 1 + max(0, 1.5g_{p} - 0.5)$
- $g_{p}$ : pitch correlation ($0 < g_{p} < 1$) - 다음으로 낮은 확률로 인한 impulse noise를 방지하기 위해 threshold $T$ 미만의 확률이 0이 되도록 분포에서 constant를 뺌
- $P'(e_{t}) = \mathcal{R} (max [ \mathcal{R} ([ P(e_{t})]^{c}) - T, 0]) $
- $\mathcal{R}(\cdot)$ : 분포를 noramlize 하는 역할
- Constant $c = 1 + max(0, 1.5g_{p} - 0.5)$
- Training Noise Injection
- 음성 합성 시 network는, 생성된 sample이 training sample과 다르므로 training 과정과 다른 조건에서 동작함
- Training과 Inference의 불일치는 합성 과정에서 distortion을 발생시킬 수 있음
- Network를 더 robust 하게 구성하기 위해, training 과정에 noise injection을 추가함
- LPCNet은 linear prediction을 사용하기 때문에 noise injection 설계가 중요함
- Amplitude에 비례하는 noise를 만들기 위해 $\mu$-law 영역에 직접 injection 함
- Output이 prediction residual임에도 불구하고 input 중 하나가 해당 residual을 계산하는 데 사용된 것과 동일한 prediction이기 때문
- $Q$ : $\mu$-law quantization, $Q^{-1}$ : $\mu$-law to linear conversion
- $P(z) = \sum^{M}_{k=1} a_{k}z^{-k}$ : prediction filter - Excitation은 clean, unquantized input과 prediction 간의 차이로 계산됨
- Amplitude에 비례하는 noise를 만들기 위해 $\mu$-law 영역에 직접 injection 함

4. Experiments
- Settings
- Dataset : NTT Multi-Lingual Speech Database for Telephonmetry
- Comparison : WaveRNN+
- Complexity
- LPCNet의 복잡도는:
- $C = (3dN^{2}_{A} + 3N_{B} (N_{A} + N_{B}) + 2N_{B}Q) \cdot 2F_{s}$
- $N_{A}, N_{B}$ : 각각 2개 GRU의 크기, $d$ : Sparse GRU의 density
- $Q$ : $\mu$-law level의 수, $F_{s}$ : sampling rate
-> $N_{A} = 384, N_{B} = 16, Q=256, F_{s} = 16000$이라고 했을 때, 총복잡도는 2.8 GFLOPS - 다른 모델들과 비교해 보면,
- WaveRNN은 10 GFLOPS, SampleRNN은 50 GFLOPS, WaveNet은 16 GFLOPS
-> LPCNet의 복잡도가 가장 낮음
- Quality Evaluation
- MUSHRA 방법론을 활용하여 주관적인 청취 품질 평가를 수행
- LPCNet의 품질이 동일한 복잡도에 대해 WaveRNN의 성능을 크게 앞지름
- 추가적으로 LPCNet에 적용된 pre-emphasis는 synthesis artifactr에 비해 $\mu$-law quantization noise의 효과를 무시할 수 있게 만들어 줌

반응형
'Paper > Vocoder' 카테고리의 다른 글
댓글