
티스토리 뷰
Paper/Vocoder
[Paper 리뷰] Framewise WaveGAN: High Speed Adversarial Vocoder in Time Domain with Very Low Computational Complexity
feVeRin 2024. 4. 29. 10:14반응형
Framewise WaveGAN: High Speed Adversarial Vocoder in Time Domain with Very Low Computational Complexity
- GAN-based vocoder는 고품질 waveform을 합성하는데 자주 사용됨
- BUT, 대부분의 architecture는 sample-wise로 waveform을 생성하므로 상당한 GFLOPS가 필요함
- 결과적으로 accelerator나 parallel computer 없이 일반적인 CPU에서 사용하기 어려움 - Framewise WaveGAN
- Framewise로 time domain signal을 생성하기 위해 recurrent, fully-connected network를 활용하는 GAN-based vocoder
- 결과적으로 computation complexity를 크게 절감하고 GPU, CPU 모두에서 빠른 동작이 가능
- 논문 (ICASSP 2023) : Paper Link
1. Introduction
- Neural vocoder는 음성 합성을 위해 광범위하게 사용되고 있음
- 이때 time-domain에서 raw waveform data distribution을 모델링함으로써 speech signal의 detail을 capture 할 수 있고, 결과적으로 고품질의 합성이 가능함
- BUT, neural vocoder는 target sampling rate에 따라 computational cost도 빠르게 증가함
- 대표적으로 WaveNet은 autoregressive sampling으로 인해 상당한 computational cost 문제를 겪음
- LPCNet과 같이 linear prediction을 사용하여 lightweight architecture를 구성할 수도 있지만, 여전히 만족스러운 성능을 보이지는 못함 - 이때 parallel generative model은 GPU, CPU accelerator를 사용하여 computation을 parallelize 함으로써 합성 속도를 크게 높일 수 있음
- 특히 generative adversarial network (GAN) vocoder는 WaveGlow와 같은 maximum-likelihood model 보다 더 뛰어난 품질과 parallel generation을 지원할 수 있음
- 고품질 생성 측면에서는 diffusion-based vocoder를 고려할 수도 있지만, iterative denoising step으로 인해 추론 속도의 한계가 있음 - 결과적으로 GAN-based vocoder를 사용하면 높은 품질과 빠른 속도를 모두 달성할 수 있지만, 여전히 상당량의 GFLOPS가 필요함
-> 그래서 GAN-based vocoder의 computational cost를 줄일 수 있는 Framewise WaveGAN을 제안
- Framewise WaveGAN
- 기존의 sample-by-sample 방식 대신 frame-by-frame으로 time-domain에서 wide band speech signal을 합성
- Multi-resolution STFT regression과 adversarial loss를 조합하여 perceptual domain에서 모델을 training 함으로써 안정적인 성능을 달성
< Overall of Framewise WaveGAN >
- Framewise로 time domain signal을 생성하는 GAN-based vocoder
- 결과적으로 computation complexity를 크게 절감하면서 우수한 품질을 달성함
2. Framewise WaveGAN
- 대부분의 GAN vocoder는 WaveNet-based와 latent-based model로 나눌 수 있음
- WaveNet-based model에서는 모든 network parameter가 target signal과 동일한 rate로 사용됨
- 즉, $f_{s}$의 sampling rate로 음성을 생성하려면 총 FLOPS로 $f_{s}$ multiplication과 $f_{s}$ accumulation을 수행해야 함
- e.g.) Parallel WaveGAN의 경우 16kHz에서 1초의 음성을 생성하기 위해 46 GFLOPS가 필요 - Latent-based model은 network upsampling layer stack을 활용하여 computational burden을 해결함
- Target sampling rate에 도달할 때까지 서로 다른 resolution에서 acoustic feature를 upsampling 하는 방식 - 제안하는 Framewise WaveGAN은 upsampling layer를 사용하지 않으면서 time domain에서 acoustic feature rate로 GAN vocoder를 동작하는 것을 목표로 함
- 이를 위해 모델이 frame-by-frame으로 동작하도록 구성
- 일반적으로 WaveNet-based, latent-based model에서 feature representation은 $[\textrm{Batch_dim}, \textrm{Channel_dim}, \textrm{Temporal_dim}]$의 tensor로 구성됨
- 이때 $\textrm{Temporal_dim}$은 output layer의 target signal resolution과 동일 - 이와 달리 Framewise WaveGAN은 feature representation을 $[\textrm{Batch_dim}, \textrm{Sequence_dim}, \textrm{Frame_dim}]$으로 구성함
- $\textrm{Sequence_dim}$은 일반적으로 signal 보다 훨씬 작으면서 acoustic feature resolution과 동일함
- $\textrm{Frame_dim}$은 생성할 target frame을 나타냄
- 결과적으로 Framewise WaveGAN의 final waveform은 output으로 생성된 frame을 간단히 flattening 하여 얻어짐
- 이를 통해 large memory footprint를 가지는 모델에 대해서도 상당한 computational saving 효과를 얻을 수 있음
- WaveNet-based model에서는 모든 network parameter가 target signal과 동일한 rate로 사용됨
- Architecture Overview
- Framewise WaveGAN의 architecture는 아래 그림과 같음
- 크게 recurrent layer와 fully-connected layer에 대한 두 가지 stack으로 구성됨
- Recurrent stack에서는 signal의 long-term dependency를 모델링하기 위한 5개의 GRU를 사용
- 모든 GRU output은 acoustic feature와 concatenate 되고 fully-connected layer를 통해 lower-dimensional latent representation으로 변환됨 - 이후 해당 representation은 short-term dependency를 모델링하기 위해 framewise convolution을 사용하는 fully-connected stack에 전달됨

- Framewise Convolution
- Framewise Convolution은 element가 frame인 kernel을 의미함
- 이를 위해 fully-connected layer가 frame index $i$에서 input tensor의 index $\{i-k+1,...,i\}$에서 $k$ frame의 concatenation을 receive 하도록 설계함
- $k$ : kernel size, 나머지 operation은 일반적인 convolution과 동일
- Conditioning vector와 같은 external feature frame을 layer input으로 concatenate 하기 위해 conditional framewise convolution을 설계할 수도 있음 - Framewise WaveGAN은 kernel size가 3 frame, stride=dilation=1 frame인 previous stack에서 latent representation을 receive 하는 1개의 framewise convolution layer를 사용함
- 이때 non-causal 방식으로 padding
- e.g.) 해당 layer에 대한 input tensor의 $\textrm{Frame_dim}$이 512인 경우, fully-connected network는 $3*512=1536$의 input dimension을 가짐 - 추가적으로 previous stack에서 얻어진 same latent representation에 의해 제공되는 1개의 conditioning frame 이후에 4개의 conditional framewise convolution layer를 사용함
- 이때 same stride, dilation, padding을 causal 하게 적용하여 conditional layer의 fully-connected network가 non-conditional network와 동일한 dimensionality를 가지도록 함 - 해당 framewise convolution은 모두 single-channel 방식으로만 동작함
- 즉, layer당 하나의 fully-connected network만 사용
- 한편으로 해당 layer에 sparsification을 적용하여 모델의 효율성을 높일 수도 있음
- 이를 위해 fully-connected layer가 frame index $i$에서 input tensor의 index $\{i-k+1,...,i\}$에서 $k$ frame의 concatenation을 receive 하도록 설계함
- Activation Layers
- Recurrent, framewise convolution stack의 모든 layer에 대해,
- 다음의 Gated Linear Unit (GLU)를 적용하여 feature representation을 activate 함:
(Eq. 1) $GLU(X)=X\otimes \sigma(FC(X))$
- $FC$ : sigmoid gate를 학습하기 위한 simple fully-connected network로 $X$와 동일한 output dimension을 가짐
- $\otimes$ : element-wise multiplication - 추가적으로 모든 layer에 대한 bias를 disable 함
- 이를 통해 reconstruction artifact를 줄이고 빠른 수렴을 가능하게 함
- 다음의 Gated Linear Unit (GLU)를 적용하여 feature representation을 activate 함:
- Conditioning Acoustic Features
- Framewise WaveGAN을 condition 하기 위해 LPCNet의 acoustic feature를 사용함
- 이는 18개의 Bark-Frequency Cepstral Coefficient (BFCC), Pitch period, Pitch correlation으로 구성됨
- 16kHz waveform에서 100Hz frame rate로 20ms overlapping window를 통해 추출됨
- 결과적으로 모델은 conditioning vector 당 10ms의 frame을 생성 - Pitch period는 256 level과 128 dimension의 embedding layer에 제공되고, pitch correlation이 있는 BFCC는 128 output channel과 3 kernel size로 구성된 simple causal convolution layer에 제공됨
- 이후 두 layer의 output은 concatenate 되어 256 output channel, 3 kernel size, Leaky ReLU로 구성된 causal convolution layer에 전달되어 framewise generation을 위한 acoustic feature representation을 얻음
- 이때 LPCNet feature는 5ms look-ahead가 있는 10ms frame에서 계산되고, Framewise WaveGAN은 하나의 feature frame look-ahead만 필요함
- 따라서 total delay는 framing을 위한 10ms와 look-ahead 15ms를 더하여 25ms로 계산됨
- 이는 18개의 Bark-Frequency Cepstral Coefficient (BFCC), Pitch period, Pitch correlation으로 구성됨
3. Training Procedure
- Training in the Perceptual Domain
- Speech signal은 bandwidth가 넓어짐에 따라 high dynamic range를 가짐
- Training 이전에 pre-emphasis filter를 적용하면 vocoder는 normal signal domain에서 training 하는 것보다 더 빠르게 high-frequency component를 학습할 수 있음
- 따라서 논문에서는 perceptual filtering을 도입하여 vocoder가 high-frequency content를 빠르게 학습하도록 함 - 이때 perceptual weighting filter는:
(Eq. 2) $W(z)=\frac{A(z/\gamma_{1})}{(1-\gamma_{2}z^{-1})}$
- $A(z)$ : BFCC의 coefficient로부터 계산되는 linear prediction (LPC) filter, $\gamma_{1}=0.92, \gamma_{2}=0.85$
- 해당 filtering은 training 중에 signal의 spectral flatness를 증가시켜 빠른 수렴을 가능하게 함 - Final signal을 얻기 위해 inverse filtering을 적용할 때, reconstruction artifact noise는 $W^{-1}(z)P^{-1}(z)$와 같이 형성됨
- $P^{-1}(z)$ : 합성 마지막에 적용되는 de-emphasis - 결과적으로 이러한 perceptual filtering의 computational cost는 상당히 저렴하므로 전체 complexity 역시 낮게 유지될 수 있음
- Training 이전에 pre-emphasis filter를 적용하면 vocoder는 normal signal domain에서 training 하는 것보다 더 빠르게 high-frequency component를 학습할 수 있음
- Spectral Pre-Training
- 먼저 Parallel WaveGAN의 spectral reconstruction loss $\mathcal{L}_{aux}$를 사용하여 모델을 pre-training 함
- 여기서 64~2048 까지의 FFT size를 사용하고 75% window overlap을 적용
- 한편으로 Parallel WaveGAN의 spectral magnitude loss $\mathcal{L}_{mag}$는 non-linearity로써 $\log$ 대신 $\textrm{sqrt}$를 사용하여 더 빠른 수렴을 가능하게 함
- 결과적으로 해당 spectral pre-training을 통해 over-smoothed high-frequency content를 포함하는 metallic-sound를 얻을 수 있으므로 realistic reconstruction을 위한 adversarial training에 도움을 줌
- Spectral Adversarial Training
- Framewise WaveGAN의 adversarial training을 위해 일반적으로 사용되는 time-domain discriminator를 고려할 수 있지만, 안정적인 training을 제공하지 못함
- 대신 multi-resolution sepctrogram discriminator를 사용하면 안정적인 training과 고품질의 합성 결과를 얻을 수 있음
- 이를 위해 UnivNet의 spectrogram discriminator를 활용 - Adversarial training은 discriminator의 output을 evaluate 하기 위해 least-square loss를 metric으로 하여, HiFi-GAN의 loss 구성을 따름
- 여기서 spectral reconstruction loss는 adversarial training을 regularize 하는 역할 - 결과적으로 final generator objective는:
(Eq. 3) $\min_{G}\left(\mathbb{E}_{z}\left[\sum_{k=1}^{6}(D_{k}(G(s))-1)^{2}\right]+\mathcal{L}_{aux}(G)\right)$
- $s$ : conditioning feature
- 추가적으로 weight normalization이 discriminator $D_{k}$의 모든 convolution layer와 generator $G$의 모든 fully-connected layer에 적용됨
- 대신 multi-resolution sepctrogram discriminator를 사용하면 안정적인 training과 고품질의 합성 결과를 얻을 수 있음
4. Experiments
- Settings
- Dataset : PTDB-TUG, NTT Multi-Lingual Speech Database
- Comparisons : LPCNet
- Results
- Complexity
- 1초의 음성을 생성하는데 필요한 total computational complexity는:
(Eq. 4) $C=N*2*S$
- $C$ : FLOPS, $N$ : model parameter 수, $S$ : generation step - 결과적으로 Framewise WaveGAN은 7.8M의 parameter 수에 대해 총 1.5 GFLOPS의 complexity를 가짐
- 이때 LPCNet과 같이 마지막 3개의 layer를 제외한 모든 fully-connected layer에 대해 0.65의 weight density를 적용하여 dense model을 sparsifiying 함으로써 complexity를 줄일 수 있음
- 이를 적용하면 active parameter 수를 5.9M으로 줄이고 total complexity를 1.2 GFLOPS로 줄일 수 있음
- 한편으로 RTF 측면에서 해당 Framewise WaveGAN은 CPU에서 20배, GPU에서 75배 빠르게 실행됨
- 1초의 음성을 생성하는데 필요한 total computational complexity는:
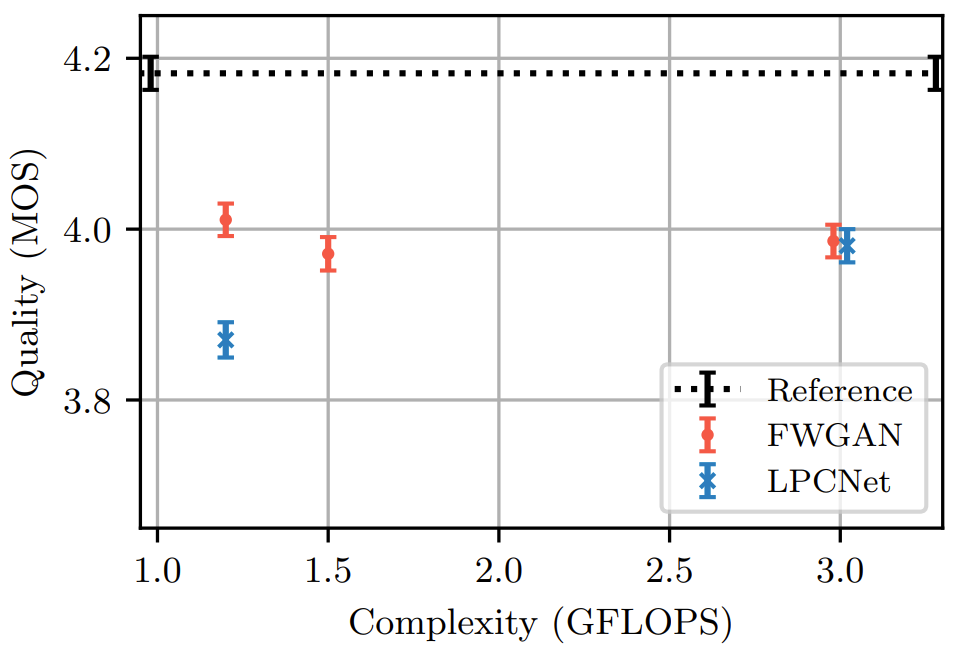
- Quality
- MOS 측면에서 Framewise WaveGAN은 동일한 complexity의 LPCNet 보다 더 우수한 성능을 달성함
- Pitch consistency 측면에서도 Framewise WaveGAN이 더 우수한 성능을 보임

반응형
'Paper > Vocoder' 카테고리의 다른 글
댓글