

 [Paper 리뷰] IST-TTS: Interpretable Style Transfer for Text-to-Speech with ControlVAE and Diffusion Bridge
[Paper 리뷰] IST-TTS: Interpretable Style Transfer for Text-to-Speech with ControlVAE and Diffusion Bridge
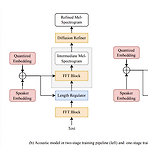
IST-TTS: Interpretable Style Transfer for Text-to-Speech with ControlVAE and Diffusion BridgeText-to-Speech에서 style transfer는 중요해지고 있음IST-TTSVariational autoencoder (VAE)와 diffusion refiner를 결합하여 refined mel-spectrogram을 얻음- 이때 audio 품질과 style transfer 성능을 향상하기 위해 two-stage, one-stage system을 각각 설계함Quantized VAE의 diffusion bridge를 통해 complex discrete style representation을 학습하고 transfer 성능을 향상더 나..
 [Paper 리뷰] ProDiff: Progressive Fast Diffusion Model for High-Quality Text-to-Speech
[Paper 리뷰] ProDiff: Progressive Fast Diffusion Model for High-Quality Text-to-Speech
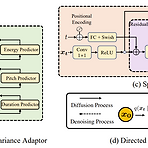
ProDiff: Progressive Fast Diffusion Model for High-Quality Text-to-SpeechDiffusion model은 text-to-speech에서 우수한 성능을 보이고 있지만, iterative sampling process로 인해 accleration의 한계가 있음특히 gradient-based model은 높은 품질을 보장하기 위해 수천번의 iteration이 필요함ProDiff고품질의 text-to-speech를 위한 progressive fast diffusion modelSampling accleration 시 발생하는 품질 저하를 방지하기 위해 clean data를 직접 예측하여 desnoising model을 parameterizationDiffu..
 [Paper 리뷰] PAVITS: Exploring Prosody-Aware VITS for End-to-End Emotional Voice Conversion
[Paper 리뷰] PAVITS: Exploring Prosody-Aware VITS for End-to-End Emotional Voice Conversion
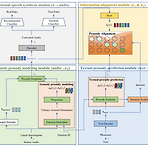
PAVITS: Exploring Prosody-Aware VITS for End-to-End Emotional Voice ConversionEmotional voice conversion은 high content naturalness와 high emotional naturalness를 만족해야 함PAVITSContent naturalness를 향상하기 위해 VITS를 기반으로 하는 end-to-end architecture를 채택- Acoustic converter와 vocoder를 seamlessly integrating 하여 emotional prosody training과 runtime conversion 간의 mismatch 문제를 해결Emotional naturalness를 위해 다양한 emot..
 [Paper 리뷰] VQTTS: High-Fidelity Text-to-Speech Synthesis with Self-Supervised VQ Acoustic Feature
[Paper 리뷰] VQTTS: High-Fidelity Text-to-Speech Synthesis with Self-Supervised VQ Acoustic Feature
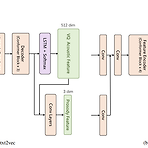
VQTTS: High-Fidelity Text-to-Speech Synthesis with Self-Supervised VQ Acoustic Feature대부분의 text-to-speech 모델은 acoustic model과 vocoder로 구성된 cascade system을 기반으로 함이때 acoustic feature로써 일반적으로 mel-spectrogram을 활용하는데, 이는 time-frequency axis를 따라 high-correlated 되어 있기 때문에 acoustic model로 예측하기 어려움VQTTS일반적인 mel-spectrogram이 아닌 self-supervised Vector-Quantized acoustic feature에 대해 acoustic model로써 txt2vec..
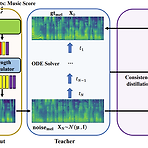 [Paper 리뷰] CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model
[Paper 리뷰] CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model
CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency ModelDenoising Diffusion Probabilistic Model은 음성 합성에서 우수한 성능을 보이고 있지만, 고품질의 sample을 얻기 위해서는 많은 iterative step이 필요함- 결과적으로 추론 속도 저하로 이어짐CoMoSpeechSingle diffusion sampling step만으로 고품질의 합성을 수행하는 Consistency model-based 음성 합성 모델Consistency constraint는 diffusion-based teacher model에서 consistency model을 distill 하기 위해 사용됨논문 (MM 20..
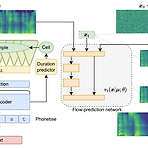 [Paper 리뷰] Matcha-TTS: A Fast TTS Architecture with Conditional Flow Matching
[Paper 리뷰] Matcha-TTS: A Fast TTS Architecture with Conditional Flow Matching
Matcha-TTS: A Fast TTS Architecture with Conditional Flow MatchingOptimal-transport conditional flow matching을 사용하여 text-to-speech에서의 acoustic modeling 속도를 향상할 수 있음Matcha-TTS Optimal-transport conditional flow matching을 기반으로 기존의 score matching 방식보다 더 적은 step으로 고품질의 output을 제공하는 ODE-based decoder를 얻음Probabilistic, non-autregressive 하게 동작하고 external alignment 없이 scratch로 학습 가능논문 (ICASSP 2024) : Pa..