

 [Paper 리뷰] Differentiable Signal Processing with Black-Box Audio Effects
[Paper 리뷰] Differentiable Signal Processing with Black-Box Audio Effects
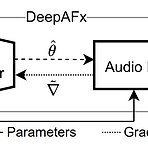
Differentiable Signal Processing with Black-Box Audio Effects Audio effect를 deep neural network로 통합하여 automate audio signal processing을 수행할 수 있음 DeepAFx Non-differentiable black-box effect layer를 학습시키기 위해 stochastic gradient approximation을 활용하여 end-to-end backpropagation을 생성 Tube amplifier emulation, automatic mastering, breath removal에 대한 audio production 작업에 적용 가능 논문 (ICASSP 2021) : Paper Link..
 [Paper 리뷰] iSTFTNet: Fast and Lightweight Mel-Spectrogram Vocoder Incorporating Inverse Short-Time Fourier Transform
[Paper 리뷰] iSTFTNet: Fast and Lightweight Mel-Spectrogram Vocoder Incorporating Inverse Short-Time Fourier Transform
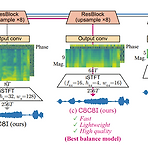
iSTFTNet: Fast and Lightweight Mel-Spectrogram Vocoder Incorporating Inverse Short-Time Fourier Transform Mel-spectrogram vocoder는 3가지 inverse 작업을 해결할 수 있어야 함 - Original-scale magnitude spectrogram의 복구, Phase reconstruction, Frequency-to-time conversion 이를 위해 temporal upsampling layer를 활용하지만, mel-spectrogram 내의 time-frequency structure를 효과적으로 사용할 수 없음 iSTFTNet Upsampling layer를 통해 frequency dime..
 [Paper 리뷰] Flow-TTS: A Non-Autoregressive Network for Text to Speech Based on Flow
[Paper 리뷰] Flow-TTS: A Non-Autoregressive Network for Text to Speech Based on Flow
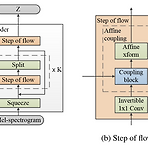
Flow-TTS: A Non-Autoregressive Network for Text to Speech Based on Flow Non-autoregressive Text-to-Speech를 위해 generative flow를 활용할 수 있음 Flow-TTS Single feed-forward network 만을 사용하여 고품질의 음성을 합성 Spectrum 생성을 위해 flow를 활용하고 single network를 통해 alignment와 spectrogram 생성을 jointly learn 논문 (ICASSP 2020) : Paper Link 1. Introduction Text-to-Speech (TTS)는 input text sequence $\{ x_{1}, x_{2}, ..., x_{N}\}..
 [Paper 리뷰] YourTTS: Toward Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for Everyone
[Paper 리뷰] YourTTS: Toward Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for Everyone
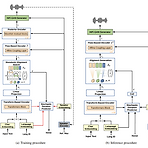
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for Everyone Zero-Shot multi-speaker Text-to-Speech를 위해 multilingual approach가 필요 YourTTS VITS를 기반으로 multi-speaker, multilingual task로 확장 Low-resource zero-shot 환경에서 우수한 합성 품질을 달성하고 1분 미만으로 fine-tuning이 가능 논문 (ICML 2022) : Paper Link 1. Introduction 대부분의 Text-to-Speech (TTS) 모델은 single speaker의 음성에만 특화되어 있음 이때 Zero-Shot ..
 [Paper 리뷰] PriorGrad: Improving Conditional Denoising Diffusion Models with Data-Dependent Adaptive Prior
[Paper 리뷰] PriorGrad: Improving Conditional Denoising Diffusion Models with Data-Dependent Adaptive Prior
PriorGrad: Improving Conditional Denoising Diffusion Models with Data-Dependent Adaptive Prior Denoising diffusion probabilistic model은 data densitiy의 gradient를 추정하여 고품질의 sample을 생성할 수 있음 일반적으로 prior noise를 standard Gaussian 분포로 정의하지만, 해당하는 data 분포는 더 복잡할 수 있음 - Data와 prior 사이의 discrepancy로 인해 data sample에서 prior noise를 제거하는 것이 어려워짐 PriorGrad Conditional information 기반의 data statistics로부터 도출된 ad..
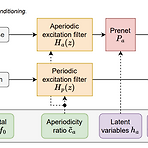 [Paper 리뷰] Embedding a Differentiable Mel-Cepstral Synthesis Filter to a Neural Speech Synthesis System
[Paper 리뷰] Embedding a Differentiable Mel-Cepstral Synthesis Filter to a Neural Speech Synthesis System
Embedding a Differentiable Mel-Cepstral Synthesis Filter to a Neural Speech Synthesis SystemEnd-to-End controllable speech synthesis를 위해 Mel-cepstral synthesis filter를 활용할 수 있음Differentiable Mel-Cepstral Synthesis FilterMel-cepstral synthesis filter를 통해 voice characteristics와 pitch는 각각 frequency warping parameter와 fundamental frequency를 통해 control 될 수 있음이때 End-to-End 방식으로 최적화할 수 있도록 diffetentiab..