

티스토리 뷰
Paper/Representation
[Paper 리뷰] SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing
feVeRin 2025. 7. 12. 08:10반응형
SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing
- Self-supervised speech/text representation learning을 위해 encoder-decoder pre-training을 활용할 수 있음
- SpeechT5
- Shared encoder-decoder network와 6개의 modal-specific pre/post-net을 활용
- Large-scale unlabeled speech-text data를 통해 model을 pre-training 하고 textual, speech information을 unified semantic space에 align 하기 위해 cross-modal vector quantization을 도입
- 논문 (ACL 2022) : Paper Link
1. Introduction
- Speech2Vec, Wav2Vec 2.0, HuBERT 등의 self-supervised speech learning method는 richly learned representation을 제공함
- BUT, speech pre-training은 다음의 한계점이 있음:
- 대부분 unlabeled speech data만을 사용하고 spoken language task에서의 textual data를 ignore 함
- 다양한 downstream task을 위해 pre-trained speech encoder에만 의존하고, sequence-to-sequence task를 위한 pre-trained decoder는 제공하지 않음
- 결과적으로 unlabeled speech, text dataset을 활용한 unified encoder-decoder model이 필요함
- 즉, 아래 그림과 같이 동일한 encoder-decoder framework를 다양한 spoken language processing task에 적용할 수 있어야 함
- BUT, speech pre-training은 다음의 한계점이 있음:

-> 그래서 다양한 speech/text-to-speech/text processing을 지원할 수 있는 SpeechT5를 제안
- SpeechT5
- Encoder-decoder backbone network, modal-specific pre/post-net을 활용하여 speech/text-to-speech/text를 modeling
- Textual, acoustic information을 unified semantic space로 align 하기 위해, 해당 representation을 shared vector quantization space로 mapping 하고 quantized latent representation을 randomly mix
< Overall of SpeechT5 >
- 다양한 spoken language processing task를 지원하는 unified-modal pre-training framework
- 결과적으로 다양한 task에서 우수한 성능을 달성
2. Method
- Model Architecture
- SpeechT5는 encoder-decoder module과 6개의 modal-specific pre/post-net으로 구성됨
- Pre-net은 input speech $\mathbf{X}^{s}\in \mathcal{D}^{s}$ 또는 text $\mathbf{X}^{t}\in\mathcal{D}^{t}$를 unified space의 hidden representation으로 convert 함
- 이후 shared encoder-decoder에 전달하여 sequence-to-sequence conversion을 수행함 - Post-net은 decoder output을 기반으로 speech/text modality에서 output을 생성함
- Pre-net은 input speech $\mathbf{X}^{s}\in \mathcal{D}^{s}$ 또는 text $\mathbf{X}^{t}\in\mathcal{D}^{t}$를 unified space의 hidden representation으로 convert 함
- Input/Output Representation
- 다양한 spoken language processing task에 대한 single model을 training 하기 위해, 논문은 다음의 speech/text-to-speech/text task를 formulate 함
- 즉, model은 speech/text를 input으로 하여 해당하는 speech/text를 output 함
- Text는 character sequence $\mathbf{X}^{t}=(\mathbf{x}_{1}^{t},...,\mathbf{x}_{N^{t}}^{t})$로 split 됨
- Speech의 경우, raw waveform $\mathbf{X}^{s}=(\mathbf{x}_{1}^{s},...,\mathbf{x}_{N^{s}}^{s})$를 input으로 하여 log mel-spectrogram feature $\mathbf{X}^{f}=(\mathbf{x}_{1}^{f},...,\mathbf{x}_{N^{f}}^{f})$를 target output으로 사용함
- 여기서 논문은 generated feature에서 final waveform을 생성하기 위해 HiFi-GAN vocoder를 채택함
- 즉, model은 speech/text를 input으로 하여 해당하는 speech/text를 output 함
- 다양한 spoken language processing task에 대한 single model을 training 하기 위해, 논문은 다음의 speech/text-to-speech/text task를 formulate 함
- Encoder-Decoder Backbone
- Transformer encoder-decoder model은 SpeechT5 backbone으로 사용됨
- 이때 input element 간의 relative position difference를 capture 하기 위해, self-attention의 dot-product weight에 relative position embedding을 적용함
- Speech Pre/Post-Net
- Wav2Vec 2.0의 convolutional feature extractor는 raw wavefrom $\mathbf{X}^{s}$를 downsampling 하고 speech utterance sequence $\mathbf{H}=(\mathbf{h}_{1},...,\mathbf{h}_{N^{h}})$를 생성하는 speech-encoder pre-net으로 사용됨
- Speech-decoder pre-net은 ReLU activation을 가지는 3개의 fully-connected layer로 구성된 network로써, log mel-filterbank $\mathbf{X}^{f}$를 input으로 사용함
- 추가적으로 multi-speaker TTS, VC task를 지원하기 위해 x-vector를 통해 추출된 speaker embedding이 speech-decoder pre-net output에 concatenate 되고, linear layer가 추가됨 - Speech-decoder post-net은 2가지 module로 구성됨:
- First module은 decoder output을 input으로 log mel-filterbank $\mathbf{Y}^{f}=(\mathbf{y}_{1}^{f},...,\mathbf{y}_{N^{f}}^{f})$를 predict 하기 위해 linear layer를 사용함
- 이후 predicted $\mathbf{Y}^{f}$를 refine 하기 위해 residual을 생성하는 5개의 1D convolutional layer가 추가됨 - Second linear module은 decoder output을 scalar로 project 하여 stop token을 predict 함
- First module은 decoder output을 input으로 log mel-filterbank $\mathbf{Y}^{f}=(\mathbf{y}_{1}^{f},...,\mathbf{y}_{N^{f}}^{f})$를 predict 하기 위해 linear layer를 사용함
- Text Pre/Post-Net
- 논문은 text-encoder pre-net과 text-decoder pre/post-net을 shared embedding으로 사용함
- Pre-net은 token index를 embedding vector로 변환하고 post-net은 hidden state를 token의 probability distribution으로 변환함

- Pre-Training
- SpeechT5는 large-scale unlabeled speech, text corpus에서 pre-training 됨
- 특히 joint pre-training method를 통해 textual, acoustic information을 unified semantic space로 align 함 - Speech Pre-Training
- Unlabeled speech data $\mathcal{D}^{s}$에서 general speech representation을 학습하기 위해, SpeechT5는 다음 2가지 task로 training 됨:
- Bidirectional Masked Prediction
- Sequence-to-Sequence generation
- Bidirectional masked prediction은 HuBERT와 같이 masked language model을 활용하여 acoustic unit discovery model이 frame-level target $\mathbf{Z}=(\mathbf{z}_{1},...,\mathbf{z}_{N^{h}})$를 제공하도록 함
- 이를 위해 speech-encoder pre-net output $\mathbf{H}$에 대해 span mask strategy를 적용하여, $8\%$의 timestep을 start index로 randomly select 하고 10 step의 span을 mask 함
- Transformer encoder는 masked $\mathbf{H}$를 input으로 하여 hidden representation $\mathbf{U}=(\mathbf{u}_{1},...,\mathbf{u}_{N^{h}})$를 생성함
- 해당 hidden representation을 기반으로 masked timestep에 대한 cross-entropy loss를 얻을 수 있음:
(Eq. 1) $\mathcal{L}_{mlm}^{s}=\sum_{n\in \mathcal{M}}\log p\left( \mathbf{z}_{n}| \hat{\mathbf{H}}, n\right) $
- $\hat{\mathbf{H}}$ : $\mathbf{H}$의 masked version, $\mathcal{M}$ : masked timestep set, $\mathbf{z}_{n}$ : $\mathbf{Z}$에서 timestep $n$의 frame-level target
- Sequence-to-Sequence generation task는 bidirectional masked prediction에서 얻어진 randomly masked input을 사용하여 original speech를 reconstruct 함
- 즉, speech-decoder pre-net, Transformer decoder, speech-decoder post-net으로 생성된 predicted output $\mathbf{Y}^{f}$가 original $\mathbf{X}^{f}$에 close 하도록 $L1$ distance를 minimize 함:
(Eq. 2) $\mathcal{L}_{1}^{s}=\sum_{n=1}^{N^{f}} \left|\left| \mathbf{y}_{n}^{f}-\mathbf{x}_{n}^{f}\right|\right|_{1}$
- $\mathbf{x}_{n}^{f}$ : $\mathbf{X}^{f}$의 $n$-th 80-dimensional log mel-filterbank - 추가적으로 stop token에 대해 Binary Cross-Entropy (BCE) loss $\mathcal{L}_{bce}^{s}$를 적용함
- 즉, speech-decoder pre-net, Transformer decoder, speech-decoder post-net으로 생성된 predicted output $\mathbf{Y}^{f}$가 original $\mathbf{X}^{f}$에 close 하도록 $L1$ distance를 minimize 함:
- Unlabeled speech data $\mathcal{D}^{s}$에서 general speech representation을 학습하기 위해, SpeechT5는 다음 2가지 task로 training 됨:
- Text Pre-Training
- Unlabeled text data $\mathcal{D}^{t}$에서 SpeechT5는 corrupted text $\hat{\mathbf{X}}^{t}=(\hat{x}_{1}^{t},...,\hat{x}_{M}^{t})$를 input으로 하여 $\mathbf{Y}^{t}=(\mathbf{y}^{t}_{1},...,\mathbf{y}_{N^{t}}^{t})$를 original text $\mathbf{X}^{t}$로 reconstruct 하도록 train 됨
- 이를 위해 논문은 text span의 $30\%$를 randomly sample 하여 mask 함
- Text span length는 Poisson distribution $\lambda =3.5$에서 추출되고, 각 span은 single mask token으로 replace 됨 - 결과적으로 text-encoder pre-net, encoder-decoder, text-decoder pre/post-net을 포함한 SpeechT5는 maximum likelihood estimation을 통해 original sequence를 생성하도록 optimize 됨:
(Eq. 3) $\mathcal{L}_{mle}^{t}=\sum_{n=1}^{N^{t}} \log p\left( \mathbf{y}_{n}^{t}| \mathbf{y}_{<n}^{t},\hat{\mathbf{X}}^{t}\right)$
- Joint Pre-Training
- 논문은 speech-text 간의 corss modality mapping을 위해, modality-invariant information을 capture 하는 representation을 학습하기 위한 cross-modal vector quantization method를 도입함
- 이때 SpeechT5는 vector quantized embedding을 speech, text representation을 shared codebook에서 align 하는 bridge로 사용함
- 먼저 quantizer를 통해 encoder output의 continuous speech/text representation $\mathbf{u}_{i}$를 fixed-size codebook $\mathbf{C}^{K}$의 discrete representation $\mathbf{c}_{i}$로 변환함
- $K$ : learnable embedding 수 - 이후 $L2$ distance를 통해 각 latent code embedding과 encoder output 간의 nearest neighbor search를 수행함:
(Eq. 4) $\mathbf{c}_{i}=\arg\min_{j\in [K]}\left|\left| \mathbf{u}_{i}-\mathbf{c}_{j}\right|\right|_{2}$
- $\mathbf{c}_{j}$ : codebook의 $j$-th quantized vector
- 먼저 quantizer를 통해 encoder output의 continuous speech/text representation $\mathbf{u}_{i}$를 fixed-size codebook $\mathbf{C}^{K}$의 discrete representation $\mathbf{c}_{i}$로 변환함
- 다음으로 논문은 해당하는 timestep에서 contextual representation의 일부 ($10\%$)를 quantized latent representation으로 randomly replace 하고, mixed representation에 대한 cross-entropy를 compute 함
- 이를 통해 quantizer는 cross-modal information을 사용하도록 explicitly guide 됨
- Diversity loss는 averaged Softmax distribution의 entropy를 maximize 하여 더 많은 code를 sharing 하도록 encourage 함:
(Eq. 5) $\mathcal{L}_{d}=\frac{1}{K}\sum_{k=1}^{K}p_{k}\log p_{k}$
- $p_{k}$ : codebook에서 $k$-th code를 choice 하는 average probability
- 결과적으로 얻어지는 final pre-training loss는:
(Eq. 6) $\mathcal{L}=\mathcal{L}_{mlm}^{s} +\mathcal{L}_{1}^{s}+\mathcal{L}_{bce}^{s}+\mathcal{L}_{mle}^{t}+\gamma \mathcal{L}_{d}$
- $\gamma=0.1$
- Fine-Tuning
- Pre-training 이후 ASR, TTS, ST, VC, SE, SID 등의 downstream loss를 통해 encoder-decoder backbone을 fine-tuning 함
- 모든 spoken language processing task는 encoder-decoder backbone output과 해당 pre/post-net을 concatenate 하여 학습할 수 있음
- e.g.) ASR의 경우, final model은 speech-encoder pre-net, encoder-decoder, text-decoder pre-net, text-decoder post-net으로 구성됨
- 해당 model은 SpeechT5로 initialize 된 다음, training data의 cross-entropy loss로 fine-tuning 됨 - 한편으로 downstream task의 input이 speech인 경우, baseline encoder는 HuBERT로 initialize 됨
- 모든 spoken language processing task는 encoder-decoder backbone output과 해당 pre/post-net을 concatenate 하여 학습할 수 있음
3. Experiments
- Settings
- Dataset : Unlabeled Speech-Text corpus (internal)
- Comparisons : Wav2Vec 2.0, HuBERT
- Results
- Automatic Speech Recognition (ASR) task에 대해, SpeechT5를 사용하면 가장 우수한 WER을 달성할 수 있음

- Text-to-Speech (TTS) task에 대해 SpeechT5를 사용하면 naturalness를 향상할 수 있음

- Voice Conversion (VC) task에서도 SpeechT5가 우수한 성능을 보임

- Speech Translation (ST) 측면에서도 SpeechT5가 적합함
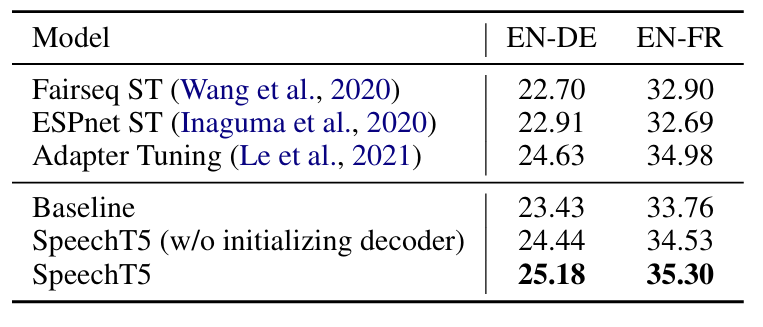
- Speech Enhancement (SE) task 역시 SpeechT5를 사용하면 WER을 향상할 수 있음

- SpeechT5는 Speech Identification (SID)에서도 우수한 성능을 보임

- Ablation Study
- 각 component를 제거하는 경우 성능 저하가 발생함

반응형
'Paper > Representation' 카테고리의 다른 글
댓글