

티스토리 뷰
Paper/Conversion
[Paper 리뷰] MeanVoiceFlow: One-Step Nonparallel Voice Conversion with Mean Flows
feVeRin 2026. 3. 20. 13:41반응형
MeanVoiceFlow: One-Step Nonparallel Voice Conversion with Mean Flows
- Voice Conversion에서 flow-matching model은 iterative inference로 인한 한계가 있음
- MeanVoiceFlow
- Mean Flow를 기반으로 pre-training, distillation 없이 one-step non-parallel conversion을 지원
- 추가적으로 structural margin reconstruction loss, zero-input constraint를 도입하여 model의 input-output behavior를 regularize
- 논문 (ICASSP 2026) : Paper Link
1. Introduction
- Voice Conversion (VC)는 linguistic information을 preserve 하면서 voice를 convert 하는 것을 목표로 함
- 특히 DiffVC, Diff-HierVC와 같은 diffusion-based model을 활용하면 high-quality VC가 가능함
- BUT, diffusion model은 iterative denoising step으로 인해 conversion 속도가 느리다는 한계가 있음 - 한편으로 StableVC, ReFlow-VC와 같은 flow matching model을 활용하면 sampling efficiency를 향상할 수 있지만 one-step case에서 성능이 크게 저하됨
- Knowledge distillation 역시 training cost와 stable training의 어려움이 있음
- 특히 DiffVC, Diff-HierVC와 같은 diffusion-based model을 활용하면 high-quality VC가 가능함
-> 그래서 pre-training, distillation 없이 flow matching VC의 efficiency를 개선한 MeanVoiceFlow를 제안
- MeanVoiceFlow
- Flow matching의 instantaneous velocity를 average velocity로 replace 하는 mean flow를 도입하고 structural margin reconstruction loss를 통해 input-output behavior를 regularize
- Conditional diffused-input training을 통해 training-inference consistency를 확보
< Overall of MeanVoiceFlow >
- Mean flow와 conditional diffused-input training을 활용한 nonparallel VC model
- 결과적으로 기존보다 우수한 성능을 달성
2. Preliminary
- Flow Matching
- Log-mel spectrogram에 해당하는 data $x\sim p_{data}(x)$, $p_{prior}=\mathcal{N}(0,1)$의 prior $\epsilon\sim p_{prior}(\epsilon)$이 주어진다고 하자
- 여기서 flow path는:
(Eq. 1) $z_{t}=(1-t)x+t\epsilon$
- Time step $t\in [0,1]$ - 해당 conditional velocity는 $v_{t}=v_{t}(z_{t}|x)=\frac{dz_{t}}{dt}=\epsilon-x$와 같이 정의됨
- $z_{t}$가 multiple $(x,\epsilon)$ pair에 대응하지 않도록 marginal instantaneous velocity $v(z_{t},t)=\mathbb{E}_{p_{t}(v_{t}|z_{t})}[v_{t}]$를 활용함 - Training
- $\theta$로 parameterize 된 neural network $v_{\theta}(z_{t},t)$는 $v(z_{t},t)$를 approximate하도록 training됨
- Flow matching loss는 distance metric $d(\cdot, \cdot)$에 대해 $\mathcal{L}_{FM}=\mathbb{E}[d(v_{\theta}(z_{t},t), v(z_{t},t))]$와 같이 정의되지만, $v(z_{t},t)$를 compute 하기 위해 $(x,\epsilon)$에 대한 marginalization이 필요하므로 intractable 함
- 따라서 $v_{t}(z_{t}|x)$를 target으로 사용하여 Conditional Flow Matching loss를 minimize 함:
(Eq. 2) $ \mathcal{L}_{CFM}=\mathbb{E}\left[d\left( v_{\theta}(z_{t},t),v_{t}(z_{t}|x)\right)\right]$
- $\mathcal{L}_{CFM}$을 minimize 하는 것은 original flow matching loss $\mathcal{L}_{FM}$을 minimize 하는 것과 equivalent 함
- Sampling
- Sample은 $z_{1}=\epsilon\sim p_{prior}(\epsilon)$에서 ODE $\frac{dz_{t}}{dt}=v_{\theta}(z_{t},t)$를 solve 하여 얻어짐
- 이때 time step $r<t$에 대한 solution은:
(Eq. 3) $z_{r}=z_{t}-\int_{r}^{t}v_{\theta}(z_{r},\tau)d\tau$ - (Eq. 3)에 대한 exact computation 역시 intractable 하므로 flow matching은 time을 discretize 하고 Euler integration과 같은 numerical method를 사용하여 ODE를 solve 함
- 여기서 flow path는:

- Mean Flows
- Instantaneous velocity $v(z_{t},t)$를 사용한 discretization은 few time step의 경우 error가 발생할 수 있음
- 따라서 Mean Flows는 average velocity를 활용하여 flow matching을 개선함
- 이때 average velocity는 $u(z_{t},r,t)=\frac{1}{t-r}\int_{r}^{t}v(z_{\tau},\tau)d\tau$와 같이 정의되어 두 time step $r,t$ 간의 displacement를 나타냄
- 양변에 $t-r$을 multiply 하고 $t$에 대해 differentiate 하면 mean flow identity를 얻을 수 있음:
(Eq. 4) $u(z_{t},r,t)=v(z_{t},t)-(t-r)\frac{d}{dt}u(z_{t},r,t)$
- Total derivative $\frac{d}{dt}u(z_{t},r,t)$는 partial derivative $\frac{d}{dt}u(z_{t},r,t)=v(z_{t},t)\partial_{z}u+\partial_{t}u$와 같이 expand 할 수 있음
- 이는 $u$의 Jacobian matrix $[\partial_{z}u,\partial_{r}u,\partial_{t}u]$와 tangent vector $[v,0,1]$ 간의 Jacobian-Vector Product로 rewrite 됨 - Training
- Neural network $u_{\theta}(z_{t},r,t)$는 mean flow loss를 minimize 하여 mean flow identity를 만족하도록 optimize 됨:
(Eq. 5) $\mathcal{L}_{MF}=\mathbb{E}\left[d(u_{\theta}(z_{t},r,t),\text{sg}(u_{tgt}))\right]$ - Target velocity $u_{tgt}$은:
(Eq. 6) $u_{tgt}=v_{t}-(t-r)(v_{t}\partial_{z}u_{\theta}+\partial_{t}u_{\theta})$
- $\text{sg}$ : stop-gradient operation - 추가적으로 (Eq. 5)의 distance metric $d$에 대한 adaptively weighted loss를 사용하고, probability $0.75$로 $r=t$를 randomly setting 하여 instantaneous/average velocity field training을 blend 함
- $d(a,b)=\frac{||a-b||^{2}_{2}}{\text{sg}\left(||a-b||_{2}^{2}+10^{-3}\right)}$
- Neural network $u_{\theta}(z_{t},r,t)$는 mean flow loss를 minimize 하여 mean flow identity를 만족하도록 optimize 됨:
- Sampling
- Sample은 $z_{1}=\epsilon \sim p_{prior}$에 (Eq. 7)을 적용하여 생성됨:
(Eq. 7) $z_{r}=z_{t}-(t-r)u_{\theta}(z_{t},r,t)$
- (Eq. 3)의 flow matching에서 사용되는 time integral은 time duration, average velocity의 product인 $(t-r)u_{\theta}(z_{t},r,t)$로 replace 되어 discretization error를 reduce 함 - 1-step sampling의 경우, (Eq. 7)은 다음과 같이 simplify 됨:
(Eq. 8) $z_{0}=z_{1}-u_{\theta}(z_{1},0,1)$
- Sample은 $z_{1}=\epsilon \sim p_{prior}$에 (Eq. 7)을 적용하여 생성됨:
- 따라서 Mean Flows는 average velocity를 활용하여 flow matching을 개선함
3. Method
- Extension to Conditional Generation
- VC는 linguistic content를 preserve 하면서 speaker identity를 modify 해야 하므로, 논문은 speaker, linguistic information을 incorporate 한 conditional generation을 도입함
- 이를 위해 average velocity $u(z_{t},r,t)$를 speaker embedding $s$, content embedding $c$에 대한 conditional form $u(z_{t},r,t,s,c)$로 extend 함
- 해당 extension은 mean flow와 fully-compatible 하고 average velocity를 conditional form으로만 replace 함
- Zero-Input Constraint
- Mean flow에서 target velocity $u_{tgt}$은 $u_{\theta}$의 derivative에 의존하므로, training 시 inaccurate $u_{\theta}$로 인한 instability가 발생할 수 있음
- 이를 해결하기 위해 direct element-wise reconstruction loss $\mathcal{L}_{rec}=\mathbb{E}||\hat{x}-x||_{p}^{p}$를 사용하여 input-output behavior를 regularize 할 수 있음
- $\hat{x}$ : (Eq. 8)의 $z_{0}$ output, $x$ : ground-truth data, $p$ : 1 또는 2 - BUT, 해당 strong constraint는 over-smoothing으로 이어질 수 있으므로 논문은 zero-input constraint인 structural margin reconstruction loss를 도입함:
(Eq. 9) $\mathcal{L}_{zerorec}=\mathbb{E}\left[\max\left( 1-\text{SSIM}(\bar{x},x),m\right)\right]$
- $\text{SSIM}$ : SSIM similarity, $\bar{x}$ : zero-input $z_{1}=\bar{\epsilon}=0$에 대한 (Eq. 8)의 $z_{0}$ output, $m=0.3$ : margin - 즉, $\mathcal{L}_{zerorec}$은 $\mathcal{L}_{rec}$의 over-smoothing을 방지하기 위해 다음을 고려함:
- Structural Comparison
- Direct element-wise loss 대신 SSIM-based loss를 사용하여 structural similarity에 focus 함 - Margin-based Relaxation
- $\mathcal{L}_{MF}$를 통해서만 high-quality sample이 학습되도록 margin $m$을 도입해 penalize 함 - Selective Application
- Constraint는 zero-input sample에만 적용됨
- Structural Comparison
- 결과적으로 final objective는:
(Eq. 10) $\mathcal{L}_{MVF}=\mathcal{L}_{MF}+\lambda\mathcal{L}_{zerorec}$
- $\lambda=1$ : weighting hyperparameter
- 이를 해결하기 위해 direct element-wise reconstruction loss $\mathcal{L}_{rec}=\mathbb{E}||\hat{x}-x||_{p}^{p}$를 사용하여 input-output behavior를 regularize 할 수 있음
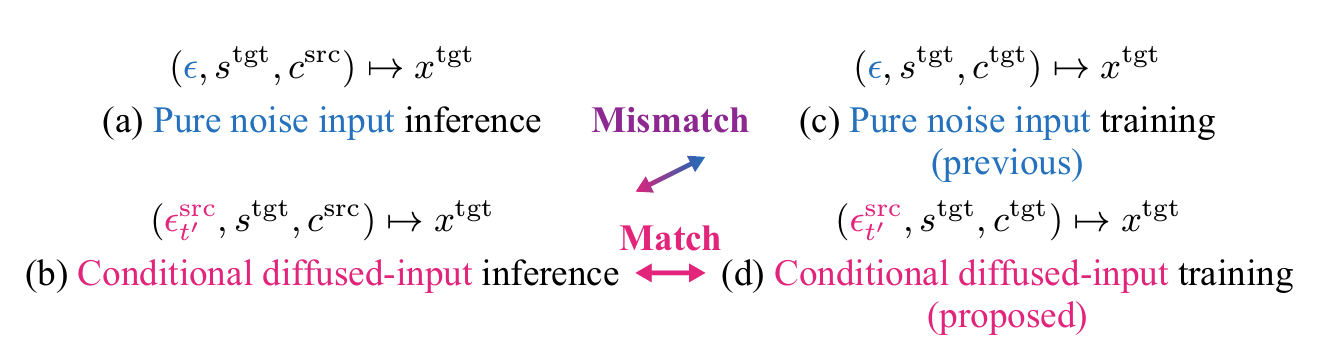
- Conditional Diffused-Input Training
- VC model은 source input을 omission, redundancy 없이 utilize 할 수 있어야 함
- 이를 위해 FastVoiceGrad와 같은 기존 diffusion-based VC model은 추론 시 pure noise $\epsilon\sim \mathcal{N}(0,1)$ 대신 diffused source data $\epsilon_{t}^{src}=(1-t')x^{src}+t'\epsilon$을 사용함
- $x^{src}$ : source data, $t'\in[0,1]$ : mixing ratio로 $0.95$로 설정 - BUT, 해당 방식은 training-inference mismatch가 발생할 수 있음
- Pure noise $\epsilon$으로 train 되지만 추론 시에는 diffused source data $\epsilon_{t'}^{src}$가 전달되기 때문 - 따라서 논문은 Conditional Diffused-Input Training을 활용하여 training 시에 diffused source data $\epsilon_{t'}^{src}$를 feed 함
- 특히 $\epsilon_{t'}^{src}$는 speaker identity가 target과 다르도록 설정됨 - 한편 nonparallel VC의 경우 paired source-target data를 확보하기 어려우므로, 논문은 model을 사용하여 $\epsilon_{t'}^{src}$를 synthesize 함
- 즉, $x^{tgt}$이 주어졌을 때 (Eq. 7)을 기반으로 diffused source data는 $\hat{\epsilon}_{t'}^{src}=\text{sg}\left(z_{1}-(1-t')u_{\theta}(z_{1},t',1,s^{src},c^{tgt})\right)$와 같이 approximately define 됨
- $z_{1}=\epsilon\sim\mathcal{N}(0,1)$, $\text{sg}$ : stop-gradient operation, $s^{src}$ : batch 내에서 $s^{tgt}$을 shuffling 하여 얻어짐 - 이후 $\epsilon,x$를 각각 $\hat{\epsilon}_{t'}^{src},x^{tgt}$으로 replace 하고 model이 input type을 distinguish 할 수 있도록 $t'$를 additional conditional input으로 사용함
- 추가적으로 stable training을 위해 batch 절반에는 $\hat{\epsilon}_{t'}^{src}$를 사용하고 나머지 절반에는 pure noise $\epsilon\sim \mathcal{N}(0,1)$을 사용함
- 즉, $x^{tgt}$이 주어졌을 때 (Eq. 7)을 기반으로 diffused source data는 $\hat{\epsilon}_{t'}^{src}=\text{sg}\left(z_{1}-(1-t')u_{\theta}(z_{1},t',1,s^{src},c^{tgt})\right)$와 같이 approximately define 됨
- 이를 위해 FastVoiceGrad와 같은 기존 diffusion-based VC model은 추론 시 pure noise $\epsilon\sim \mathcal{N}(0,1)$ 대신 diffused source data $\epsilon_{t}^{src}=(1-t')x^{src}+t'\epsilon$을 사용함
4. Experiments
- Settings
- Dataset : VCTK
- Comparisons : DiffVC, FasterVoiceGrad, FastVoiceGrad, VoiceGrad
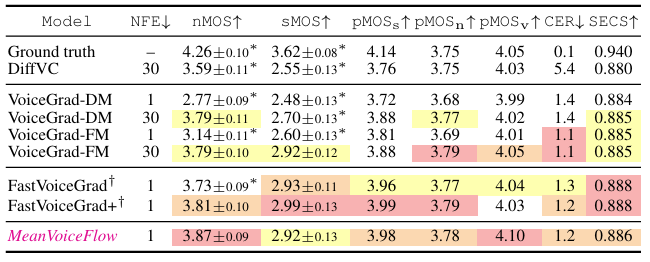
- Results
- 전체적으로 MeanVoiceFlow의 성능이 가장 우수함
- Zero-Input Constraint
- Zero-input constraint를 사용했을 때 최고의 성능을 보임

- Conditional Diffused-Input Training
- Conditional diffused-input training을 활용하면 $t'$에 대한 robustness를 향상할 수 있음

- Versatility Analysis
- LibriTTS dataset에 대해서도 우수한 성능을 보임

반응형
'Paper > Conversion' 카테고리의 다른 글
댓글