

티스토리 뷰
Paper/Conversion
[Paper 리뷰] MF-Speech: Achieving Fine-Grained and Compositional Control in Speech Generation via Factor Disentanglement
feVeRin 2026. 2. 2. 13:00반응형
MF-Speech: Achieving Fine-Grained and Compositional Control in Speech Generation via Factor Disentanglement
- Expressive, controllable speech를 생성하기 위해서는 speech factor의 entanglement와 control mechanism의 coarse granularity를 해결해야 함
- MF-Speech
- Factor purifier로 사용되는 MF-SpeechEncoder를 기반으로 multi-objective optimization을 수행하여 original speech signal을 independent representation으로 decompose
- Conductor로 사용되는 MF-SpeechGenerator는 dynamic fusion과 Hierarchical Style Adaptive Normalization을 사용하여 multi-factor compositional speech generation을 수행
- 논문 (AAAI 2026) : Paper Link
1. Introduction
- Voice Conversion은 content, timbre, emotion과 같은 fundamental speech factor를 manipulate 하는 것을 목표로 함
- 대표적으로 VQMIVC, Vec-Tok-VC+ 등은 VC task에서 우수한 성능을 달성함
- BUT, 우수한 성능에도 불구하고 VC model은 여전히 다음의 한계점을 가지고 있음:
- Pure Factor Separation
- Speech에서 content, timbre, emotion 등은 naturally interwine 되어 있으므로 다양한 speech factor를 accurately separate 하기 어려움 - Lack of Fine-Grained Control
- 기존의 control mechanism은 coarse-grained로 동작하므로 content fidelity와 stlye similarity 간의 balance를 만족하지 못함
- Pure Factor Separation
-> 그래서 multi-factor disentanglement를 활용해 VC model을 개선한 MF-Speech를 제안
- MF-Speech
- 3-stream architecture를 사용하여 raw speech를 content, timbre, emotion의 highly pure, mutually independent information stream으로 decompose 하는 MF-SpeechEncoder를 도입
- Dynamic fusion과 Hierarchical Style Adaptive Normalization (HSAN)을 incorporate 한 MF-SpeechGenerator를 통해 coarse control을 개선
< Overall of MF-Speech >
- MF-SpeechEncoder, MF-SpeechGenerator를 활용한 multi-factor voice conversion model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- Overview
- MF-Speech는 fine-grained speech synthesis를 위해 3가지의 independent, high-purity speech factor를 추출한 다음, dynamically integrate 하고 timbre와 emotion을 inject 함
- MF-SpeechEncoder
- Input speech로부터 각 core factor에 대한 disentangled discrete representation을 추출하는 high-purity factor encoder - MF-SpeechGenerator
- Discrete factor representation을 기반으로 final speech를 생성하는 fine-grained waveform generator
- MF-SpeechEncoder

- MF-SpeechEncoder
- MF-SpeechEncoder는 speech content, timbre, emotion의 high-purity, mutually independent representation을 학습하는 것을 목표로 함
- 이때 MF-SpeechEncoder는 multi-objective optimization strategy 하에서 training 됨
- 구조적으로는 3가지의 specialized sub-module과 information-theoretic auxiliary module로 구성된 3-stream architecture를 사용함:
- Content Factor Module
- 먼저 pure speech content를 isolate 하기 위해 pre-trained Wav2Vec2 model을 사용하여 initial representation을 추출하고,
- Lightweight trainable sub-network가 sentence-level content contrastive learning을 통해 해당 representation을 refine 하여 residual timbre, emotion을 suppress 함
- 최종적으로 Residual Vector Quantization (RVQ)를 사용해 discrete content token으로 discretize 함 - Emotion Factor Module
- 먼저 lightweight predictor는 intermediate layer에서 $F0$, energy representation을 explicitly generate 하고 해당 predicted prosody representation으로부터 final emotion representation을 derive 함
- 이후 emotion contrastive loss는 서로 다른 emotional state 간의 representation에 대한 discriminability를 향상하고, RVQ를 통해 discretize 하여 controllable, transferable emotion representation을 얻음 - Timbre Factor Module
- Stable, generalizable timbre representation을 위해 SeaNet encoder에 input speech의 global timbre representation을 aggregate 하는 multi-head attention을 추가함
- 이후 representation robustness를 위해 timbre-specific contrastive loss를 적용하고 RVQ를 통해 discretize 함 - Information Theory Constraints
- Dedicated factor module 간의 residual entanglement를 방지하기 위해, 논문은 discretization 이후 Mutual Information (MI) minimization을 사용한 structural regularization을 수행함
- 특히 CLUB, MINE에 기반한 separate MI estimation network를 training 하여 factor representation 간의 redundant information을 penalize 함
- Content Factor Module
- 결과적으로 MF-SpeechEncoder는 multi-objective loss를 사용하여 content, emotion, timbre의 disentangled discrete representation을 생성하도록 training 됨:
(Eq. 1) $\mathcal{L}_{Encoder} =\sum_{f\in \{t,e,c\}}\lambda_{com}^{f}\cdot \mathcal{L}_{com}^{f}+\sum_{f\in\{t,e,c,\}}\lambda_{w}^{f}\cdot \mathcal{L}_{w}^{f}+\lambda_{p}\cdot\mathcal{L}_{p}+\alpha(\text{epoch})\cdot \sum_{X,Y}\mathcal{L}_{MI}(X,Y)$
- $\mathcal{L}_{w}^{f}$ : RVQ objective, $\mathcal{L}_{com}$ : factor-specific contrastive learning loss, $\mathcal{L}_{p}$ : prosody prior, $\mathcal{L}_{MI}$ : MI minimization constraints - 이때 MI constraint가 initial representation learning을 hinder 하지 않도록 warm-up schedule을 적용함
- $t,e,c$ : 각각 content, timbre, emotion factor, $\alpha(\text{epoch})$ : MI loss에 대한 warm-up weighting

- MF-SpeechGenerator
- MF-SpeechGenerator는 MF-SpeechEncoder의 discrete factor representation을 기반으로 dynamic fusion과 HSAN을 통해 fine-grained, compositional control을 수행함
- 구조적으로는 다음 4가지 module로 구성됨:
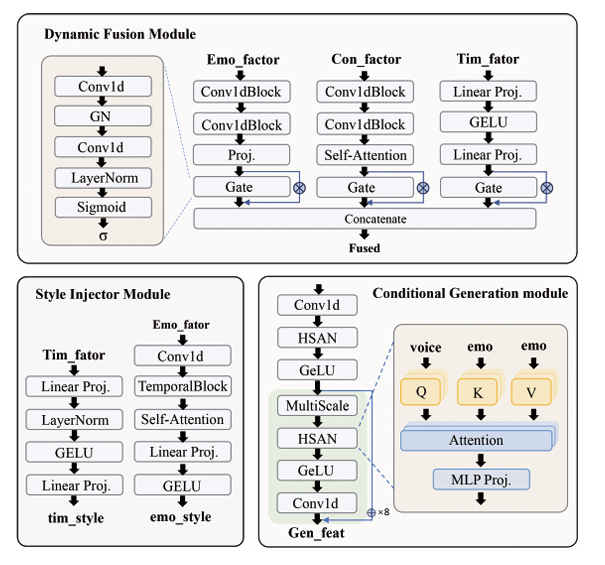
- Dynamic Fusion Module
- MF-SpeechEncoder의 discrete content, timbre, emotion representation을 dynamically integrate 하여 unified conditional representation으로 변환함
- 이를 위해 dynamic gating mechanism을 채택하여 각 factor의 영향을 time step 별로 regulate 함 - Style Injection Module
- Style injection module은 timbre, emotion의 discrete representation으로부터 multi-level style parameter representation을 추론함 - Conditional Generation Module
- Conditional generation module은 dynamically fused factor representation을 style parameter generator의 hierarchical style parameter에 따라 detailed acoustic representation sequence로 mapping 함
- 이때 backbone network는 multi-scale convolution module을 포함한 stacked residual block을 사용하여 complex temporal dependency를 capture 함
- 특히 HSAN은 cross-attention을 통해 timbre, emotion representation을 fuse 해 affine parameter $(\gamma, \beta)$와 residual modulation term $\alpha$를 생성하여 stylistic control을 지원함:
(Eq. 2) $y=\text{IN}(x)(1+\tanh(\gamma))+\beta+\lambda\tanh(\alpha)\odot x$
- $\text{IN}(x)$ : instance normalization, $x$ : input feature, $\lambda$ : scalar - Waveform Synthesis Module
- Waveform synthesis module은 generated acoustic representation을 speech waveform으로 변환함
- 구조적으로는 SeaNet decoder를 사용하고 training 시에는 phased unfreezing strategy를 통해 fine-tuning 하여 synthesis quality를 향상함
- Dynamic Fusion Module
- MF-SpeechGenerator는 adversarial learning을 통해 train 되고 pre-trained waveform decoder에 phased unfreezing strategy를 적용하여 stable convergence를 보장함
- 이때 generator에 대한 composite loss function $\mathcal{L}_{Generator}$는:
(Eq. 3) $\mathcal{L}_{Generator}=\lambda_{gate}\mathcal{L}_{gate}+\lambda_{g}\mathcal{L}_{g}+\lambda_{feat}\mathcal{L}_{feat}+\lambda_{t}\mathcal{L}_{t}+\lambda_{f}\mathcal{L}_{f}+\lambda_{sim}\mathcal{L}_{sim}$ - Multi-scale discriminator loss $\mathcal{L}_{d}$는 real speech $x$, generated speech $\hat{x}$에 대한 hinge loss로 정의됨:
(Eq. 4) $ \mathcal{L}_{d}=\frac{1}{K}\sum_{k=1}^{K}\left[\max(0,1-D_{k}(x))+\max(0,1+D_{k}(\hat{x}))\right]$
- 이때 generator에 대한 composite loss function $\mathcal{L}_{Generator}$는:
- 구조적으로는 다음 4가지 module로 구성됨:
3. Experiments
- Settings
- Dataset : ESD
- Comparisons : StyleVC, NaturalSpeech2, FACodec, DDDM-VC
- Results
- 전체적으로 MF-Speech는 우수한 성능을 보임

- Objective evaluation 측면에서도 MF-Speech가 가장 뛰어남

- $t$-SNE 측면에서 MF-SpeechEncoder는 independent, pure cluster를 구성함

- Ablation Study
- 각 component를 제거할수록 성능 저하가 발생함

반응형
'Paper > Conversion' 카테고리의 다른 글
댓글