

티스토리 뷰
Paper/TTS
[Paper 리뷰] PFluxTTS: Hybrid Flow-Matching TTS with Robust Cross-Lingual Voice Cloning and Inference-Time Model Fusion
feVeRin 2026. 2. 26. 13:52반응형
PFluxTTS: Hybrid Flow-Matching TTS with Robust Cross-Lingual Voice Cloning and Inference-Time Model Fusion
- Flow-matching Text-to-Speech model은 stability-naturalness trade-off, cross-lingual voice cloning의 어려움, low-rate mel-feature에 대한 합성 품질의 한계가 존재함
- PFluxTTS
- Inference-time vector-field fusion을 통해 duration-guided, alignment-free model을 combine 하는 dual-decoder design을 도입
- FLUX-based decoder의 speech prompt embedding을 활용하여 robust cloning을 수행하고 48kHz super-resolution을 지원하는 PeriodWave vocoder를 적용
- 논문 (ICASSP 2026) : Paper Link
1. Introduction
- Flow-Matching (FM) architecture는 Text-to-Speech (TTS)에서 fast, high-fidelity synthesis를 지원할 수 있지만, 여전히 다음의 한계점이 존재함
- Alignment
- Duration-guided model과 alignment-free model 간의 fluency/naturalness trade-off가 존재함
- 특히 Matcha-TTS, P-Flow와 같은 대부분의 FM-TTS model은 explicit Duration Predictor에 의존하므로 overly smoothed, low-variance duration을 가지는 음성을 생성함
- 반면 E2-TTS, F5-TTS와 같이 Duration Predictor 제거하는 경우 stability 문제가 발생할 수 있음
- Cross-lingual Voice Cloning
- 대부분의 zero-shot TTS model은 fixed dimensional speaker embedding, pre-trained encoder에 의존하므로 speaker identity preservation과 cross-lingual prompt 대응이 어려움 - Vocoder Mismatch
- 기존 vocoder는 low-rate feature로부터 full-band 48kHz audio를 reconstruct 하기 어려움
- 이때 PeriodWave와 같은 Conditional Flow Matching (CFM) vocoder를 활용하면 super-resolution reconstruction이 가능함
- Alignment
-> 그래서 alignment, voice cloning, vocoder 측면에서 기존 FM-TTS의 한계점을 개선한 PFluxTTS를 제안
- PFluxTTS
- Inference-time vector-field fusion을 통해 duration-guided model과 alignment-free model을 combine한 dual-decoder architecture를 도입
- Cross-lingual prompt를 처리하는 FLUX-based architecutre를 도입하여 voice cloning 성능을 향상
- PeriodWave-based vocoder를 활용해 48kHz waveform reconstruction을 수행
< Overall of PFluxTTS >
- FLUX와 dual-decoder architecture를 기반으로 cross-lingual voice cloning을 지원하는 FM-TTS model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- Overall Architecture
- 논문은 phoneme $\mathbf{p}$와 acoustic prompt $\mathbf{s}$로부터 mel-spectrogram $\hat{\mathbf{m}}\in\mathbb{R}^{F\times T}$를 synthesize 하는 것을 목표로 함
- 이를 위해 weight sharing이 없는 Duration-Guided (DG) model, Alignment-Free (AF) model을 independently training하여 사용함
- 각 model은 text feature $c_{text}^{DG/AF}$와 prompt feature $c_{sp}^{DG/AF}$를 생성하는 Text/Prompt Encoder를 가짐
- 여기서 Text Encoder는 language ID와 pre-trained ECAPA-TDNN speaker embedding을 기반으로 AdaLN을 통해 additionally conditioning됨
- 추론 시 DG, AF vector field는 single ODE integration 내에서 fuse 되어 $\hat{\mathbf{m}}$을 output 하고, 이는 PeriodWave-based super-resolution vocoder를 통해 48kHz speech로 변환됨
- DG path
- FLUX를 따라 8개의 DoubleStream block과 16개의 SingleStream block으로 구성되는 decoder를 도입함
- DoubleStream에서는 prompt, content token에 대한 separate parameter를 사용하고 concatenated sequence에 대한 self-attention을 수행함
- SingleStream에서는 merged representation을 jointly refine 하고 content token만 retain 함 - 추가적으로 Length Regulator와 CFM decoder 이전에 FLUX block을 insert 하여 text embedding이 early stage에서 enriced prompt information을 가지도록 함
- FLUX를 따라 8개의 DoubleStream block과 16개의 SingleStream block으로 구성되는 decoder를 도입함
- AF path
- F5-TTS를 따라 논문은 DiT-style conditional decoder를 채택하고 learned filler token으로 phoneme sequence를 expand 하여 acoustic length $T$를 match 함
- 이를 통해 Duration Module 없이 CFM으로 mel을 predict 할 수 있음 - 추론 시에는 DG model의 Duration Predictor가 predict 한 $T$를 reuse 하여 두 path가 동일한 $(F,T)$ grid에서 operate 하도록 함
- F5-TTS를 따라 논문은 DiT-style conditional decoder를 채택하고 learned filler token으로 phoneme sequence를 expand 하여 acoustic length $T$를 match 함
- 이를 위해 weight sharing이 없는 Duration-Guided (DG) model, Alignment-Free (AF) model을 independently training하여 사용함

- Voice Cloning
- 논문은 speaker identity를 preserve 하기 위해 model을 acoustic prompt로 conditioning 하고, 각 path는 Speech Prompt Encoder를 사용함
- DG path에서 8-layer Transformer는 prompt mel-spectrogram을 encoding 함
- 이때 Speech Prompt Encoder는 learnable query pooling을 통해 variable-length sequence를 $K=16$의 embedding set로 reduce 함
- 해당 token은 FLUX decoder에서 content token과 함께 jointly attend 됨
- AF path의 경우 동일한 backbone에 self-attention을 적용하여 fixed 1024-dimensional prompt embedding $c_{sp}^{AF, emb}$를 생성함
- 특히 DG와 달리 AF에서 sequence-level prompt conditioning을 사용하면 word skipping이 발생하므로, 논문은 stability를 위해 fixed embedding을 채택함 - 추가적으로 512-dimensional ECAPA-TDNN embedding을 AdaLN을 통해 text encoder에 conditioning 하여 convergence와 cloning quality를 향상함
- Training 시에는 reference audio에서 1-6s를 random crop 하여 acoustic prompt로 사용함
- 해당 span은 target mel에서 mask 되어 content leakage를 방지함
- DG path에서 8-layer Transformer는 prompt mel-spectrogram을 encoding 함
- Flow-Matching Inference Mixing
- PFluxTTS는 mel generation을 위해 optimal transport conditional flow matching을 채택함
- $x_{1}\sim q$와 $x_{0}\sim \mathcal{N}(0,I)$가 주어졌을 때 linear path와 target field는:
(Eq. 1) $ x_{t}=(1-(1-\sigma)t)x_{0}+tx_{1},\,\,\, u_{t}(x_{0},x_{1})=x_{1}-(1-\sigma)x_{0}$
- $\sigma=0.01$ : minimum noise level - 그러면 neural vector field $v_{\theta}(t,x)$는 다음과 같이 train 됨:
(Eq. 2) $\mathcal{L}_{CFM}(\theta)=\mathbb{E}_{t\sim \mathcal{U}[0,1],x_{1}\sim q, x_{0}\sim \mathcal{N}(0,I)}\left|\left| v_{\theta}(t,x_{t})-u_{t}(x_{0},x_{1})\right|\right|_{2}^{2}$ - PFluxTTS에서 $v_{\theta}$는 text, prompt feature $(c_{text}, c_{sp})$에 condition 됨
- DG의 경우 sequence $c_{sp}^{DG, seq}$를 사용하고 AF의 경우 fixed embedding $c_{sp}^{AF, emb}$를 사용함
- 추가적으로 joint Classifier-Free Guidance (CFG)를 적용하면:
(Eq. 3) $v_{\theta}^{cfg}(t,x)=v_{\theta}(t,x|c_{text},c_{sp})+\gamma\left[ v_{\theta}(t,x|c_{text},c_{sp})-v_{\theta}(t,x|\varnothing)\right]$
- $\gamma$ : guidance strength
- 이때 conditional dropout $p=0.1$을 적용하여 $c_{text}$, $c_{sp}$를 independently zeroing 함
- Mixing
- 추론 시에는 2개의 independently trained TTS model의 vector field를 fusing 함
- Duration-guided field를 $v_{\theta}^{DG}(t,x)$, alignment-free field를 $v_{\phi}^{AF}(t,x)$라고 하면, 각 solve step에서 single-field upate는 다음과 같이 replace 할 수 있음:
(Eq. 4) $\hat{v}(t,x_{t})=\alpha(t)v_{\theta}^{DG,cfg}(t,x_{t})+(1-\alpha(t))v_{\phi}^{AF, cfg}(t,x_{t})$
- 이후 $t\in [0,1]$에서 midpoint ODE solver를 사용해 $\frac{dx_{t}}{dt}=\hat{v}(t,x_{t})$를 integrate 함 - $\alpha(t)$는 piecewise-constant로써 $N$ solver step에서 first $N_{1}$은 $\alpha(t)=\alpha$로 설정하고 remaining step에서는 $\alpha(t)=0$으로 설정함
- 이를 통해 early step에서는 DG field가 alignment를 stabilize 하고 final step에서는 AF model의 fluency benefit을 preserve 할 수 있도록 함
- $\alpha = 0$인 경우 word skipping으로 인해 CER이 증가할 수 있고 $\alpha=1$인 경우 stable alignment를 얻을 수 있지만 over-regularize timing으로 인해 naturalness가 감소함
- Temporal alignment를 위해 AF model은 DG model이 predict 한 duration $T$를 사용하므로 두 field 모두 동일한 mel shape $(F,T)$에서 동작함
- $x_{1}\sim q$와 $x_{0}\sim \mathcal{N}(0,I)$가 주어졌을 때 linear path와 target field는:
- PeriodWave Vocoder with Super-Resolution
- 논문은 PeriodWave를 waveform decoder로 채택하고 다음 2가지 modification을 적용함:
- Time-Downsampled Conditioning & 48kHz synthesis
- PFluxTTS decoder는 24kHz에서 hop size 512로 compute 된 low frame-rate mel-feature를 output 함
- 따라서 해당 low-rate conditioning을 사용할 수 있도록 PeriodWave를 re-train 함 - 추가적으로 Period-Aware Estimator에 additional upsampling block과 downsampling block을 insert 하여 48kHz audio를 reconstruct 하도록 함
- PFluxTTS decoder는 24kHz에서 hop size 512로 compute 된 low frame-rate mel-feature를 output 함
- Prompt-Aware Conditioning
- Global prompt embedding $c_{sp}$는 48kHz audio에서 ConvNeXt V2-P encoder를 사용하여 추출됨
- Linear projection 이후 $c_{sp}$는 PeriodWave Mel Encoder의 activation에 add 되어 24kHz/hop-512 mel representation의 high-frequency detail loss를 compensate 하는 speaker information을 제공함 - Training 시 $c_{sp}$는 target과 disjoint 한 short prompt segment에서 compute 되어 content leakage를 방지함
- Global prompt embedding $c_{sp}$는 48kHz audio에서 ConvNeXt V2-P encoder를 사용하여 추출됨
- Time-Downsampled Conditioning & 48kHz synthesis
3. Experiments
- Settings
- Dataset : Yodas
- Comparisons : ChatterBox, ElevenLabs, FishSpeech
- Results
- 전체적으로 PFluxTTS의 성능이 가장 우수함
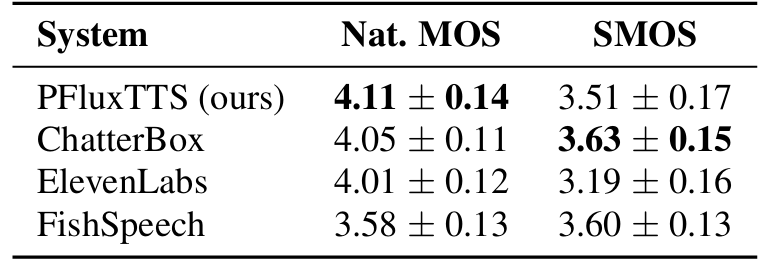
- Objective evaluation 측면에서도 우수한 성능을 보임
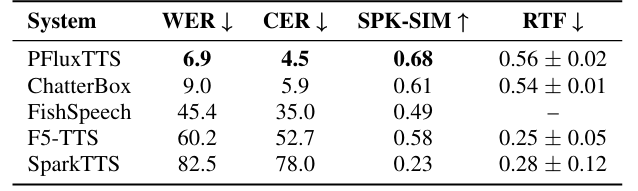
- Ablation Study
- $\alpha=0.75$일 때 최적의 성능을 달성함

- PeriodWave vocoder를 사용하면 더 나은 성능을 달성할 수 있음

반응형
'Paper > TTS' 카테고리의 다른 글
댓글