

티스토리 뷰
Paper/Representation
[Paper 리뷰] SSAST: Self-Supervised Audio Spectrogram Transformer
feVeRin 2025. 10. 30. 12:35반응형
SSAST: Self-Supervised Audio Spectrogram Transformer
- Audio task에 Transformer를 적용할 수 있음
- SSAST
- Self-Supervised Learning을 통해 Audio Spectrogram Transformer를 향상
- Joint discriminative and generative masked spectrogram patch modeling에 기반한 pre-training을 적용
- 논문 (AAAI 2022) : Paper Link
1. Introduction
- Audio Spectrogram Transformer (AST)와 같은 pure self-attention-based model은 기존 CNN-based model에 비해 많은 training data를 요구함
- AST 역시 audio/speech data의 한계로 인해 ImageNet data를 활용한 cross-modal pre-training을 수행함
- BUT, expensive 한 annotated audio data에 비해 radio/YouTube 등에서 unlabeled audio data를 얻는 것은 쉬움
- 즉, data requirement를 줄이기 위해 unlabeled data 기반의 Self-Supervised Learning (SSL)을 고려할 수 있음
-> 그래서 AST에 self-supervised learning을 적용한 SSAST를 제안
- SSAST
- Joint discriminative and generative Masked Spectrogram Patch Modeling (MSPM)-based SSL framework를 활용하여 기존 AST의 성능을 향상
- 특히 neighboring band, time information을 기반으로 spectrogram patch를 predict 하여 temporal, frequency structure를 모두 학습
< Overall of SSAST >
- AST에 Masked Spectrogram Patch Modeling을 적용한 SSL model
- 결과적으로 다양한 downstream task에서 기존보다 우수한 성능을 달성
2. Method
- AST Model Architecture
- AST에서 $t$-seconds input audio waveform은 25ms Hanning window를 10ms 마다 적용한 128-dimensional log-Mel filterbank (fbank) feature sequence로 변환되어 $128\times 100t$ input spectrogram을 생성함
- 이후 spectrogram을 $16\times 16$ patch sequence로 split 하고 각 $16\times 16$ patch를 linear projection layer를 통해 1D 768-dimensional patch embedding으로 flatten 함
- 이때 해당 linear projection layer를 patch embedding layer라 하고, output을 patch embedding $E$라 함 - 한편 Transformer는 input order information을 capture 하지 않고 patch sequence 역시 temporal order가 아님
- 따라서 model이 2D audio spectrogram의 spatial structure를 학습할 수 있도록 각 patch embedding에 size 768의 trainable positional embedding $P$를 추가함
- 이후 생성된 sequence는 Transformer로 input 됨 - 구조적으로 Transformer는 여러 encoder, decoder layer로 구성됨
- BUT, AST는 classification task를 위해 design 되었으므로 논문에서는 768 embedding dimension, 12 layer, 12 head를 가지는 Transformer encoder만 사용함 - 해당 Transformer encoder output을 patch representation $O$라고 하자
- Fine-tuning/Infernence 시 patch representation sequence $\{O\}$에 대해 mean pooling을 적용하여 audio clip-level representation을 얻고 classification을 위한 linear head를 적용할 수 있음
- 따라서 model이 2D audio spectrogram의 spatial structure를 학습할 수 있도록 각 patch embedding에 size 768의 trainable positional embedding $P$를 추가함
- 이후 spectrogram을 $16\times 16$ patch sequence로 split 하고 각 $16\times 16$ patch를 linear projection layer를 통해 1D 768-dimensional patch embedding으로 flatten 함
- 추가적으로 논문은 Self-Supervised Learning을 위해 AST에 다음의 modification을 수행함
- 먼저 original AST에서는 $\text{[CLS]}$ token을 Transformer encoder의 input sequence beginning에 append 하고 $\text{[CLS]}$ token의 output representation을 audio clip-level representation으로 사용함
- 이와 달리 논문은 audio clip-level representation으로 all patch representation $\{O\}$에 mean pooling을 적용함
- 기존 AST에서는 supervised signal이 $\text{[CLS]}$에 적용되므로 $\text{[CLS]}$의 output representation이 pre-training을 summarize 하지만,
- SSL framework에서는 supervision이 individual patch에 적용되므로 all patch representation의 mean이 더 나은 summary가 되기 때문
- 다음으로 original AST에서는 spectorgram patch를 split with overlap 하여 model 성능을 향상함
- 반면 논문에서는 overlapped edge를 task prediction의 shortcut으로 사용하는 것을 방지하기 위해 pre-training 시 overlap 없이 patch를 split 함
- Fine-tuning/inference 시에는 original AST와 같이 overlap을 6으로 설정하여 patch를 split 함
- 먼저 original AST에서는 $\text{[CLS]}$ token을 Transformer encoder의 input sequence beginning에 append 하고 $\text{[CLS]}$ token의 output representation을 audio clip-level representation으로 사용함

- Joint Discriminative and Generative Masked Spectrogram Patch Modeling
- Masked Patch Sampling
- Pre-training 시 논문은 10s fixed-length audio를 $1024\times 128$ size의 spectrogram으로 변환함
- 그러면 AST는 spectrogram을 512개의 $16\times 16$ patch로 split 함
- 이를 통해 model은 pre-training 시 entire time frame이 아닌 spectrogram patch를 mask 하게 되므로 data의 temporal, frequency structure를 학습할 수 있음 - 추가적으로 논문은 아래 그림과 같이 masked patch cluster를 control 하기 위해 cluster factor $C$를 도입함
- 먼저 patch를 randomly select 하고 해당 patch를 중심으로 한 square를 side length $C$로 masking 함
- i.g.) $C=3$인 경우 total size $48\times 48$인 9개의 patch cluster를 masking 함 - 이때 $C$가 클수록 global spectrogram structure를 학습하고 $C$가 작을수록 local structure를 학습함
- 따라서 논문은 local, global structure를 모두 학습할 수 있도록 pre-training 시 $C\sim [3,5]$를 randomly use 함
- 먼저 patch를 randomly select 하고 해당 patch를 중심으로 한 square를 side length $C$로 masking 함

- Joint Discriminative and Generative Masked Spectrogram Patch Modeling
- 논문은 pre-training을 위해 discriminative, generative objective를 combine 함
- 먼저 아래 [Algorithm 1]을 따라 각 input spectrogram $X$는 512 patch $x$로 split 되고 해당하는 patch embedding $E$로 convert 됨
- 이후 $N$ masked patch position index set $I$를 randomly generate 함
- 이때 mask 할 각 patch에 대해 해당 patch embedding을 learnable mask embedding $E_{mask}$로 replace 함 - 다음으로 patch embedding에 position embedding을 add 하고 Transformer encoder에 input 함
- 이후 $N$ masked patch position index set $I$를 randomly generate 함
- 각 masked patch $x_{i}$에 대해 Transformer encoder output $O_{i}$를 얻은 다음, $O_{i}$를 classification head와 reconstruction head에 input 하여 output $c_{i}, r_{i}$를 얻음
- Classification, reconstruction head는 $O_{i}$ (768)을 $x_{i}$ (256)과 동일한 dimension으로 mapping 하는 2-layer MLP로 구성됨
- 이때 $r_{i}$가 $x_{i}$와 close 하다면 model은 correct $(x_{i}, c_{i})$ pair를 match 할 수 있음 - 결과적으로 논문은 discriminative objective를 위한 InfoNCE loss $\mathcal{L}_{d}$, generative objective를 위한 Mean Square Error (MSE) loss $\mathcal{L}_{g}$를 도입함:
(Eq. 1) $ \mathcal{L}_{d}=-\frac{1}{N}\sum_{i=1}^{N}\log \left(\frac{\exp\left( C^{\top}_{i}x_{i}\right)}{\sum_{j=1}^{N}\exp\left(C^{\top}_{i}x_{j}\right)}\right)$
(Eq. 2) $\mathcal{L}_{g}=\frac{1}{N}\sum_{i=1}^{N}(r_{i}-x_{i})^{2}$
- $N$ : masked patch 수 - $\mathcal{L}_{d},\mathcal{L}_{g}$를 weight $\lambda=10$으로 summation 하면:
(Eq. 3) $\mathcal{L}=\mathcal{L}_{d}+\lambda\mathcal{L}_{g}$
- Classification, reconstruction head는 $O_{i}$ (768)을 $x_{i}$ (256)과 동일한 dimension으로 mapping 하는 2-layer MLP로 구성됨
- 최종적으로는 optimizer를 사용하여 AST model $\mathcal{M}$의 weight를 update 하여 $\mathcal{L}$을 minimize 함
- 즉, model은 모든 masked patch에서 각 masked position에 대해 correct patch를 pick 하는 것을 목표로 함
- 이를 통해 pre-text task의 difficulty를 높여 model이 trivial thing을 학습하는 것을 방지하고 algorithm이 mini-batch size에 영향받지 않도록 함

3. Experiments
- Settings
- Dataset
- Pre-training : AudioSet, LibriSpeech
- Downstream : AudioSet, ESC, Speech Commands 2 (KS2), Speech Commands 1 (KS1), VoxCeleb, IEMOCAP - Comparisons : Wav2Vec, Wav2Vec 2.0, HuBERT
- Results
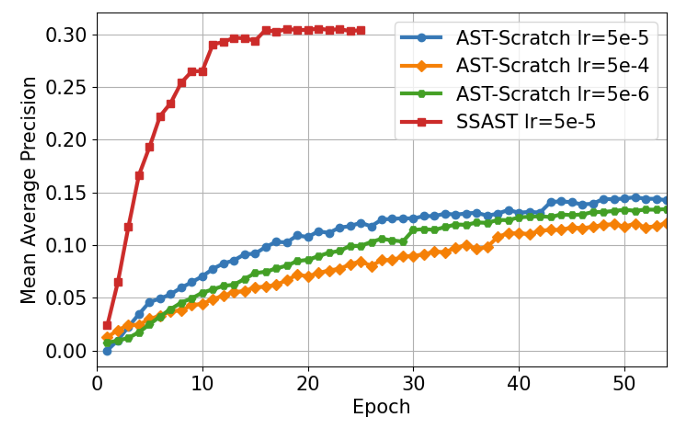
- 전체적으로 SSAST의 성능이 가장 우수함

- 각 downstream task에 대해 SSAST는 최고의 성능을 보임

- Learning curve 측면에서도 SSAST는 더 빠르게 수렴함
- Pre-Training Settings
- 400 masked patch를 사용하는 경우 최고의 성능을 달성함

- Pre-text task에서도 400 masked patch를 사용했을 때 가장 우수한 결과를 달성함

- 더 많은 iteration으로 pre-training 하면 더 나은 downstream task 성능을 얻을 수 있음

- AST Model Size
- AST model을 scaling 하면 더 나은 성능을 달성할 수 있음

- Patch-based vs. Frame-based AST
- Patch-based AST는 frame-based AST에 비해 더 큰 성능 향상을 보임

반응형
'Paper > Representation' 카테고리의 다른 글
댓글