

티스토리 뷰
Paper/TTS
[Paper 리뷰] Stable-TTS: Stable Speaker-Adaptive Text-to-Speech Synthesis via Prosody Prompting
feVeRin 2025. 4. 15. 17:24반응형
Stable-TTS: Stable Speaker-Adaptive Text-to-Speech Synthesis via Prosody Prompting
- Speaker-adaptive text-to-speech model은 target speech sample에 sensitive 함
- Stable-TTS
- High-quality pre-training dataset의 subset인 prior sample의 prosody를 활용하여 target speaker timbre를 효과적으로 반영
- Fine-tuning 시 prior-preservation loss를 활용하여 target sample에 대한 overfitting을 방지
- 논문 (ICASSP 2025) : Paper Link
1. Introduction
- YourTTS, VALL-E와 같은 zero-shot text-to-speech (TTS) model은 few second target speech 만으로도 near-human quality speech를 합성할 수 있음
- BUT, zero-shot TTS는 다음의 한계점이 존재함:
- 모든 speaker에 대해 high-quality zero-shot TTS를 수행하기 위해서는 large dataset에 대한 extensive pre-training이 필요함
- Source corpora와 target speaker distribution 간의 shift로 인해 naturalness의 한계가 있음
- 해당 문제를 해결하기 위해 UnitSpeech, AdaSpeech와 같이 source domain knowledge를 반영하고 target speaker의 sample speech에 대한 fine-tuning을 수행할 수 있음
- BUT, few-shot sample이 noise, clipping, distortion을 포함하는 경우 speaker similarity가 저하됨
- BUT, zero-shot TTS는 다음의 한계점이 존재함:
-> 그래서 limited, noisy target sample에 대해서도 consistent 한 speech를 합성할 수 있는 Stable-TTS를 제안
- Stable-TTS
- Pre-training dataset에서 추출한 small subset인 high-quality prior sample을 활용
- Prosody Encoder와 Prosody Language Model (PLM)을 도입하여 prosody generation을 guide 하고 Style Encoder를 통해 target speaker timbre를 향상
- 추가적으로 fine-tuning 시 prior-preservation loss를 적용하여 target sample에 대한 overfitting을 방지
< Overall of Stable-TTS >
- Prosody modeling과 prior sample을 활용한 zero-shot TTS model
- 결과적으로 limited, noisy sample에 대해서도 기존보다 뛰어난 naturalness, similarity를 달성
2. Method
- Stable-TTS는 limited noisy target speech sample에 대해서도 prosody consistency를 보장하는 것을 목표로 함
- 이를 위해 fine-tuning/inference stage 모두에서 high-quality prior sample을 활용함

- Diffusion-based Zero-Shot TTS Models
- Stable-TTS는 diffusion-based TTS model인 Grad-StyleSpeech, Grad-TTS를 기반으로 함
- 구조적으로는 text encoder $T$, prosody encoder $P$, variance adaptor $V$, timbre encoer $S$, diffuion model로 구성됨
- Training 시에는 phoneme sequence의 text $\mathbf{t}$, speech $\mathbf{X}$의 pair로 구성된 dataset을 사용하고, 이때 speech $\mathbf{X}$는 mel-spectrogram으로 제공됨 - 먼저 text encoder $T$, prosody encoder $P$는 text $\mathbf{t}$, speech $\mathbf{X}$를 각각 latent representation $\mu_{ph}=T(\mathbf{t}), \mathbf{p}_{ph}=P(\mathbf{X})$로 encoding 함
- $\mathbf{p}_{ph}$ : $\mu_{ph}$의 length와 match 되는 phoneme-level prosody code
- 그러면 prosody encoder는 vector quantization layer를 통해 prosody representation을 discrete prosody code의 fixed set으로 discretize 함
- Variance adaptor $V$는 $\mathbf{p}_{ph},\mu_{ph}$를 각각 $\mathbf{p}=V(\mathbf{p}_{ph}),\mu=V(\mu_{ph})$의 sequence로 expand 함
- 여기서 두 sequence는 target mel-spectrogram $\mathbf{X}$와 same length를 가짐
- Timbre encoder $S$는 mel-spectrogram에서 timbre feature를 추출함
- 이때 논문은 training 중에 same speaker $\mathbf{X}$에서 $k$ mel-spectrogram을 sampling 하고
- 다음과 같이 concatenate 하여 target speaker characteristic을 strengthen 함:
(Eq. 1) $\mathbf{s}=S(\mathbf{X}_{R}),\,\,\,\mathbf{X}_{R}=\text{concat}(\mathbf{X}_{r_{1}},...,\mathbf{X}_{r_{k}})$
- $\text{concat}$ : concatenation, $\mathbf{X}_{r_{1}},...,\mathbf{X}_{r_{k}}$ : target speaker mel-spectrogram
- Diffusion model은 noise estimator $\epsilon$을 사용하여 speech를 생성함
- Noise estimator는 noisy mel-spectrogram에서 forward process에 대한 noise를 estimate 하도록 training 됨
- Forward process는 (Eq. 2)의 stochastic differential equation으로 modeling 되고, mel-spectrogram $\mathbf{X}$를 $\mathbf{X}_{T}$로 gradually transform 함:
(Eq. 2) $d\mathbf{X}_{t}=-\frac{1}{2}\mathbf{X}_{t}\beta_{t}dt+\sqrt{\beta_{t}}dW_{t},\,\,\,t\in[0,T]$
- $\mathbf{X}_{T}$ : Gaussian distribution $\mathcal{N}(0,I)$를 따르는 random noise
- $\beta_{t}$ : noise scheduling constant, $W_{t}$ : standard Wiener process - Certain timestep $t$에서 noise estimator $\epsilon$은 다음과 같이 주어진 representation에 대한 noise를 estimate 하도록 training 됨:
(Eq. 3) $\mathcal{L}_{diff}=\mathbb{E}_{t,\mathbf{X},\varepsilon}\left|\left| \epsilon(\mathbf{X}_{t},t,\mu,\mathbf{p},\mathbf{s})+\varepsilon \sigma_{t}^{-1}\right|\right|_{2}^{2}$
- $\mathbf{X}_{t}$ : timestep $t$에서 forwarded noisy input $\mathbf{X}$
- $\sigma_{t}=\sqrt{1-e^{-\int_{0}^{t}\beta_{s}ds }}$, $\varepsilon$ : $\mathcal{N}(0,\sigma_{t}^{2})$의 noise sample
- 구조적으로는 text encoder $T$, prosody encoder $P$, variance adaptor $V$, timbre encoer $S$, diffuion model로 구성됨
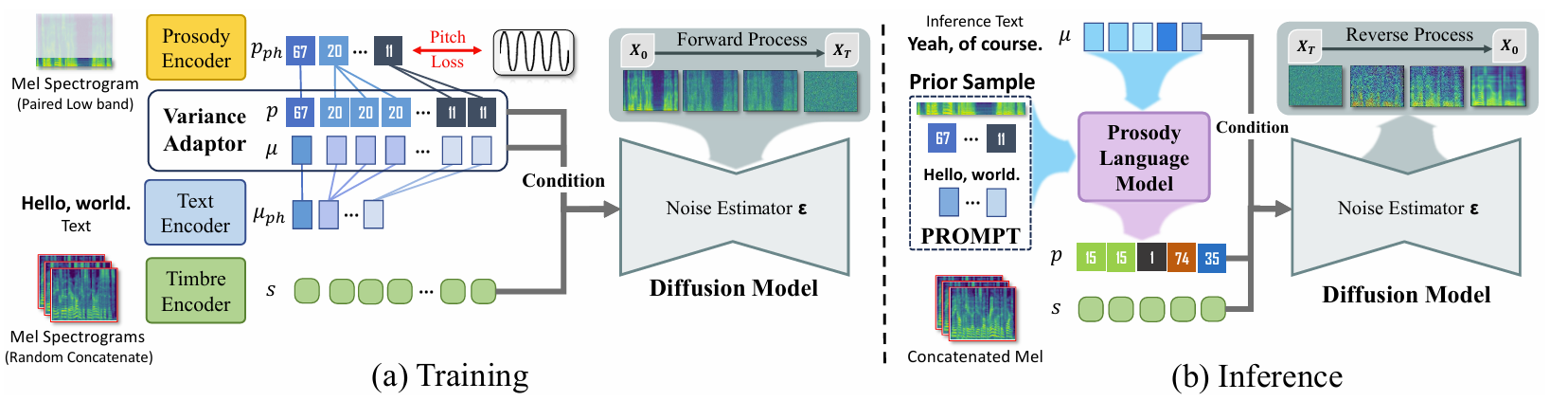
- Prosody Language Model for Prior Prosody Prompting
- Stable-TTS는 prosody $\mathbf{p}$와 timbre $\mathbf{s}$를 distinct representation으로 modeling 함
- 여기서 timbre vector $\mathbf{s}$는 continuous, unconstrained, prosody code $\mathbf{p}$는 discrete, pre-defined codebook으로 limit 됨
- 해당 code는 text contet에 appropriate prosodic element를 적용하는 것을 목표로 하므로, input text $\mathbf{t}$와 align 됨 - Inference 시에는 target speech와 input text가 directly align 되지 않으므로 input text에 대한 prosody code를 predict 하는 additional module이 필요함
- 이를 위해 auto-regressive manner로 prosody code를 predict 하는 Prosoy Language Model (PLM)을 도입함
- 즉, PLM은 prompt speech $\tilde{\mathbf{X}}$가 주어졌을 때 다음의 objective를 사용하여 prosody code $\mathbf{p}$를 predict 함:
(Eq. 4) $\arg\max_{\mathbf{p}_{t}}\text{PLM}(\mathbf{p}_{t}|\tilde{\mathbf{p}},\tilde{\mu},\mathbf{p}_{<t},\mu_{\leq t})$
- $\text{PLM}$ : trained PLM
- $\tilde{\mathbf{p}}=V(P(\tilde{\mathbf{X}}))$ : prompt speech $\tilde{\mathbf{X}}$에서 derive 된 prompt prosody code
- $\tilde{\mu}=V(T(\tilde{\mathbf{t}}))$ : prompt speech $\tilde{\mathbf{t}}$에서 encode 된 text
- Predicted prosody code $\mathbf{p}$를 codebook의 pre-defined set으로 constraining 함으로써, fine-tuning 이후에도 synthesized speech는 pre-training sample과 consistent를 유지할 수 있음
- 추가적으로 target speech를 prompt speech $\tilde{\mathbf{X}}$로 사용하는 대신 pre-training dataset의 clean speech인 prior sample을 사용함
- 이를 통해 PLM은 stable prosody code sequence를 생성할 수 있음
- 여기서 timbre vector $\mathbf{s}$는 continuous, unconstrained, prosody code $\mathbf{p}$는 discrete, pre-defined codebook으로 limit 됨
- Prior-Preservation Loss for Fine-Tuning
- Target speaker speech sample을 사용하여 TTS model을 fine-tuning 하면 naturalness를 preserving 하면서 speaker voice를 accurately cloning 할 수 있음
- BUT, 해당 방식은 real-world scenario의 noisy sample에 대해서는 한계가 있음
- 특히 few noisy sample에 대한 fine-tuning은 overfitting으로 이어질 수 있음 - 이를 해결하기 위해 논문은 fine-tuning에 prior-preservation loss를 도입함
- Prior-preservation loss는 clean/noisy sample 간의 estimated noise difference를 minimize 하여 pre-trained distribution을 maintain 함
- 즉, pre-training dataset에서 high-quality prior sample subset을 사용하여 두 diffusion model 간의 estimated noise의 mean squared error를 minimize 함:
(Eq. 5) $ \mathcal{L}_{ppl}=\mathbb{E}_{t,\mathbf{X}}\left|\left| \epsilon(\mathbf{X}_{t},t,\mu,\mathbf{p},\mathbf{s};\theta')-\epsilon( \mathbf{X}_{t},t,\mu,\mathbf{p},\mathbf{s};\theta)\right|\right|_{2}^{2}$
- $\mathbf{X}$ : pre-training dataset의 prior sample
- $\mathbf{X}_{t}$ : timestep $t$에서 forward noisy input $\mathbf{X}$
- $\theta'$ : noise estimator의 pre-trained, frozen parameter, $\theta$ : fine-tuning 할 parameter
- 해당 prior-preservation loss는 diffusion model이 clean speech를 합성할 수 있는 ability를 retain 하도록 보장함
- Fine-tuning 시 noise estimator는 (Eq. 3)의 $\mathcal{L}_{diff}$와 (Eq. 5)의 auxiliary loss $\mathcal{L}_{ppl}$을 minimize 함 - 결과적으로 이를 통해 Stable-TTS는 few noisy sample에 대해서도 high-quality speech를 생성할 수 있음
- BUT, 해당 방식은 real-world scenario의 noisy sample에 대해서는 한계가 있음

3. Experiments
- Settings
- Dataset : LibriTTS, VCTK
- Comparisons : Grad-StyleSpeech, UnitSpeech
- Results
- 전체적으로 Stable-TTS의 성능이 가장 우수함

- Zero-Shot vs. Fine-Tuning
- Stable-TTS는 zero-shot scenario에서도 충분히 우수한 성능을 보이지만, fine-tuning을 수행하는 경우 naturalness를 더욱 향상할 수 있음

- 한편으로 fine-tuning step은 500일 때 최적의 성능을 보임

- Evaluation Under Limited Amounts of Target Samples
- Stable-TTS는 restricted sample에 대해서도 뛰어난 성능을 달성할 수 있음

반응형
'Paper > TTS' 카테고리의 다른 글
댓글