

티스토리 뷰
Paper/SVS
[Paper 리뷰] SPSinger: Multi-Singer Singing Voice Synthesis with Short Reference Prompt
feVeRin 2025. 4. 24. 17:53반응형
SPSinger: Multi-Singer Singing Voice Synthesis with Short Reference Prompt
- Singing Voice Synthesis는 limited training data로 인해 multi-singer scenario에서 한계가 있음
- SPSinger
- Short reference prompt에서 consistent timbre feature를 capture 하는 global encoder를 도입
- Training 중에는 long prompt에서 detailed variation을 capture 하는 attention-based local encoder를 사용하고, 추론 시에는 global embedding에서 timbre feature를 derive 하는 Latent Prompt Adaptation Model을 적용
- 추가적으로 Latent Prompt Adaptation Model을 통해 pitch shift value를 predict 하는 pitch shift algorithm을 설계
- 논문 (ICASSP 2025) : Paper Link
1. Introduction
- Singing Voice Synthesis (SVS)는 realistic artificial singing voice를 생성하는 것을 목표로 함
- 특히 기존에는 multi-singer SVS를 위해 multi-speaker Text-to-Speech (TTS) apporach를 활용했음
- BUT, singing은 다양한 pitch, timbre를 가지므로 일반적인 spoken language와는 다른 characteristic을 가짐 - 결과적으로 single, consistent timbre feature는 multi-singer SVS system에 적합하지 않음
- 이를 위해서는 singer의 time-varying aspect나 multiple reference audio의 finer detail을 capture 할 수 있어야 함
- 특히 기존에는 multi-singer SVS를 위해 multi-speaker Text-to-Speech (TTS) apporach를 활용했음
-> 그래서 short reference audio prompt에 기반한 zero-shot multi-singer SVS model인 SPSinger를 제안
- SPSinger
- StableDiffusion framework를 기반으로 global encoder, local encoder를 incorporate
- Global encoder는 short reference prompt의 timbre feature를 capture 하고 local encoder는 longer prompt의 detailed timbre characteristic을 extract 함 - 추론 시 high-quality synthesis를 지원하기 위해 Latent Prompt Adaptation Model (LPAM)을 도입
- Global timbre hidden feature와 Music score의 local timbre feature를 추출하여 local encoder와 long prompt에 대한 의존성을 제거함 - 추가적으로 LPAM framework에서 pitch shift method를 적용하여 accurate pitch representation을 획득
- StableDiffusion framework를 기반으로 global encoder, local encoder를 incorporate
< Overall of SPSinger >
- StableDiffusion framework를 기반으로 prompt를 capture 하는 zero-shot SVS model
- 결과적으로 기존보다 뛰어난 zero-shot SVS 성능을 달성
2. Method
- Overall Architecture
- SPSinger는 phoneme level의 pitch $\mathbf{m}^{p}$, lyrics $\mathbf{m}^{l}$, duration $\mathbf{m}^{d}$, slur $\mathbf{m}^{s}$를 포함한 music score sequence $\mathbf{m}$을 target singer의 short audio prompt $\tilde{\mathbf{a}}^{s}$와 함께 사용함
- 구조적으로는 music score encoder, acoustic model, vocoder로 구성됨
- 먼저 music score encoder $E^{m}$은 Transformer architecture를 기반으로 music score sequence $\mathbf{m}$을 hidden sequence $\mathbf{e}_{m}$으로 convert 함
- Acsoutic model의 경우 StableDiffusion architecture를 기반으로 함
- 이때 vocal characteristic을 precisely control 하기 위해 global encoder $E^{g}$와 local encoder $E^{l}$을 사용함
- Global encoder $E^{g}$는 short audio prompt에서 consistent timbre feature를 capture 하고 Local encoder $E^{l}$은 longer audio prompt에서 time-varying timbre feature를 추출함 - 추가적으로 추론 시 long prompt 사용을 제거하기 위해 Transformer 기반의 Latent Prompt Adaptation Module (LPAM)을 도입함
- LPAM은 music score hidden sequence $\mathbf{e}_{m}$과 global feature hidden sequence $\mathbf{e}_{g}$로부터 local feature hidden sequence $\mathbf{e}_{l}$을 predict 하여 long prompt를 obivate 함
- 여기서 LPAM은 synthesis 중에 pitch sequence $\mathbf{m}^{p}$를 adjust 하기 위해 pitch shift $\Delta p$를 predict 함
- 이때 vocal characteristic을 precisely control 하기 위해 global encoder $E^{g}$와 local encoder $E^{l}$을 사용함
- Vocoder의 경우 DiffSinger를 따라 pre-trained HiFi-GAN을 채택함

- Global & Local Encoder
- 논문은 pre-trained global encoder $E^{g}$를 사용하여 short audio prompt $\tilde{\mathbf{a}}^{s}$에서 fixed-size feature를 추출함
- 특히 해당 encoder는 ECAPA-TDNN과 additional linear layer를 포함하여 model에 adapt 됨
- 이때 consistent global timbre feature는 music score sequence에 대해 replicate 되고 speaker encoder parameter를 fix 한 상태로 linear layer만 training 함 - Local encoder $E^{l}$은 music score sequence에 align 되는 long reference mel-spectrogram $\tilde{\mathbf{M}}^{l}$의 timbre variation을 capture 함
- 이때 convolutional stack을 사용하여 contextual feature를 추출하고, $\text{mel2ph}$의 phoneme-level pooling을 통해 frame-level mel-spectrogram을 phoneme-level musice score sequence와 align 함
- 추가적으로 residual connection이 있는 Multi-Head Self-Attention (MHSA)를 활용하여 music score, long prompt feature 내의 global relationship을 capture 함
- 이후 Multi-Head Cross-Attention (MHCA)를 통해 music score hidden feature $\mathbf{h}_{m}$과 long prompt feature $\mathbf{h}_{l}$ 간의 inter-dependency를 modeling 함
- 여기서 attention query $\mathbf{Q}=\mathbf{h}_{m}\mathbf{W}_{q}\in\mathbb{R}^{L\times D}$, key $\mathbf{K}=\mathbf{h}_{l}\mathbf{W}_{k}\in\mathbb{R}^{L_{p}\times D}$, value $\mathbf{V}=\mathbf{h}_{l}\mathbf{W}_{v}\in\mathbb{R}^{L_{p}\times D}$에 대해, local feature hidden sequence $\mathbf{e}_{l}$은:
(Eq. 1) $\mathbf{e}_{l}=\text{softmax}\left(\frac{\mathbf{Q}\cdot \mathbf{K}^{\top}}{\sqrt{D}}\right)\cdot \mathbf{V}$
- 특히 해당 encoder는 ECAPA-TDNN과 additional linear layer를 포함하여 model에 adapt 됨
- Latent Prompt Adaptation Model (LPAM)
- Local encoder는 long reference audio prompt input이 필요하므로 impractical 함
- 따라서 논문은 long reference prompt $\tilde{\mathbf{a}}^{l}$ 없이 local feature hidden sequence $\mathbf{e}_{f}$를 생성하는 Transformer-decoder-based Latent Prompt Adaptation Model (LPAM)을 도입함
- 먼저 LPAM은 concatenated global feature hidden sequence $\mathbf{e}_{g}$와 music score hidden sequence $\mathbf{e}_{m}$을 input으로 사용함
- 이때 1D convolution layer는 해당 input을 $\mathbf{e}_{g}$의 dimension으로 project 하고, resulting output은 4개의 Transformer-decoder layer로 전달되어 $\hat{\mathbf{e}}_{l}$을 autoregressively infer 함:
(Eq. 2) $p\left(\hat{\mathbf{e}}_{l}|\mathbf{e}_{g},\mathbf{e}_{m};\theta\right)=\prod_{i=0}^{L-1}p\left( \hat{\mathbf{e}}_{l,i}|\hat{\mathbf{e}}_{l,<i},\mathbf{e}_{g},\mathbf{e}_{m};\theta\right)$
- LPAM for Pitch Shift
- 한편으로 multi-singer synthesis는 target singer와 music score 간의 pitch range mismatch 문제가 있음
- Naive Pitch Shift (NPS) algorithm은 pitch difference에 따라 fundamental frequencey $f0$를 adjust 할 수 있지만, short reference prompt로 인해 full vocal range를 capture 하기 어려움 - 따라서 논문은 LPAM을 기반으로 Transformer-decoder layer 다음에 classifier head를 추가하여 necessary pitch shift를 predict 함
- 한편으로 multi-singer synthesis는 target singer와 music score 간의 pitch range mismatch 문제가 있음
- 따라서 논문은 long reference prompt $\tilde{\mathbf{a}}^{l}$ 없이 local feature hidden sequence $\mathbf{e}_{f}$를 생성하는 Transformer-decoder-based Latent Prompt Adaptation Model (LPAM)을 도입함
- Training & Inference Strategy
- SPSinger training은 two-stage로 구성됨
- Speech, singing voice dataset을 활용하여 LPAM 없이 training 하는 과정
- First stage에서 infer 된 paired dataset으로 LPAM을 training 하는 과정
- Training of SPSinger without LPAM
- First stage에서는 StableDiffusion을 backbone으로 하여 reconstruction loss, adversarial loss, Gaussian constraint loss를 통해 VAE encoder $\mathcal{E}$와 decoder $\mathcal{D}$를 training 함
- 이후 Latent Diffusion Model (LDM)을 training 함:
(Eq. 3) $\mathcal{L}_{LDM}(\theta)=\mathbb{E}_{\mathcal{E}(\mathbf{M}),\mathbf{e},\epsilon\sim\mathcal{N}(0,I),t}\left[ || \epsilon-\epsilon_{\theta}(\mathbf{z}_{t},t,\mathbf{e})||_{2}^{2}\right]$
- $\mathbf{e}$ : $\mathbf{e}_{m},\mathbf{e}_{g},\mathbf{e}_{l}$을 concatenate 한 hidden sequence, $t$ : time step - 여기서 zero-shot performance를 향상하기 위해 music score encoder 대신 FastSpeech2의 phoneme encoder를 사용하여 speech data에 대해 pre-training을 수행함
- 이후 singing voice dataset에 대해 model을 fine-tuning 함
- Training of LPAM
- Second training stage에서는 first stage에서 pre-train 된 StableDiffusion model을 사용하여 hidden sequence $\mathbf{e}_{m},\mathbf{e}_{g}$를 infer 함
- 이후 classifier head를 제외하고 predicted $\hat{\mathbf{e}}_{l}$과 target $\mathbf{e}_{l}$ 간의 MSE loss $\mathcal{L}_{MSE}$를 minimize 함
- 이때 MSE loss는:
(Eq. 4) $\mathcal{L}_{MSE}(\theta)=\sum_{i=0}^{L-1}||\hat{\mathbf{e}}_{l,i}-\mathbf{e}_{l,i}||_{2}^{2}$
- 다음으로 다른 layer는 fix 한 상태로 LPAM classifier head를 training 함
- 먼저 input music score sequence의 pitch sequence를 $\delta\in[-6,+6]$으로 perturb 하여 perturbed hidden sequence $\mathbf{e}'_{m}$을 얻음
- Pitch shift는 $\Delta p=p'-p_{l}\in\{0,\pm 1,\pm 2, ...,\pm 15\}$와 같이 compute 됨
- $p_{l}$ : long reference prompt의 median pitch, $p'$ : perturbed pitch sequence의 median pitch - 결과적으로 $\mathbf{e}'_{m},\mathbf{e}_{g}$를 input, $\Delta p$를 target으로 하여 Class-Distance Weighted Cross-Entropy (DWCE) loss $\mathcal{L}_{DWCE}$로 classifier head를 training 함:
(Eq. 5) $\mathcal{L}_{DWCE}=\left(1+\frac{\sum_{i\in\mathbf{c}}p_{i}\left| i-\hat{\Delta p}\right|}{C-1}\right)\cdot\text{CE}\left(\Delta p,\hat{\Delta p}\right)$
- $\hat{\Delta p}, \Delta p$ : 각각 predicted, target pitch shift value
- $\mathbf{c}=[-15, -14, ..., 15]$ : class value vector
- $p_{i}$ : $i$-th class의 softmax probability
- Second training stage에서는 first stage에서 pre-train 된 StableDiffusion model을 사용하여 hidden sequence $\mathbf{e}_{m},\mathbf{e}_{g}$를 infer 함
- Inference of SPSinger
- Inference 시에는 music score와 short reference prompt가 StableDiffusion에 input 되어 $\mathbf{e}_{m},\mathbf{e}_{g}$를 infer 함
- 이후 LPAM은 pitch shift $\hat{\Delta p}$를 predict 하여 pitch sequence를 $\mathbf{m}^{p*}=\mathbf{m}^{p}+\hat{\Delta p}$로 update 하고 ${\mathbf{e}_{m}}^{*}$을 derive 함 - Local feature $\mathbf{e}_{l}$은 ${\mathbf{e}_{m}}^{*},\mathbf{e}_{g}$를 사용하여 classifier head를 제외한 LPAM module로 얻어짐
- LDM condition $\mathbf{e}$는 ${\mathbf{e}_{m}}^{*},\mathbf{e}_{g}, \mathbf{e}_{l}$을 concatenate 하여 구성되고, decoder와 vocoder를 통해 process 되어 singing voice를 생성함
- Inference 시에는 music score와 short reference prompt가 StableDiffusion에 input 되어 $\mathbf{e}_{m},\mathbf{e}_{g}$를 infer 함
3. Experiments
- Settings
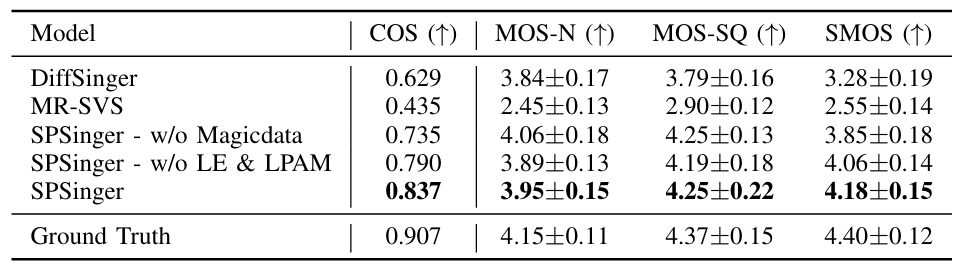
- Dataset : M4Singer, Magicdata
- Comparisons : DiffSinger, MR-SVS
- Results
- 전체적으로 SPSinger의 성능이 가장 우수함

- Unseen singer에 대해서도 SPSinger는 뛰어난 성능을 보임
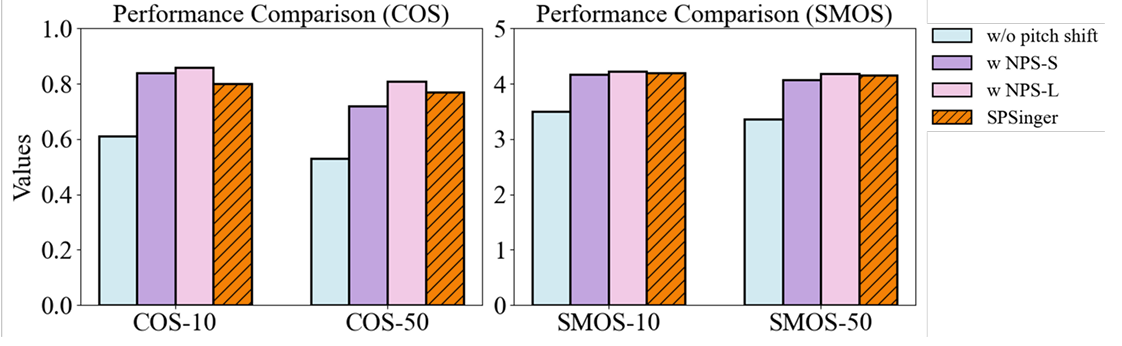
- Pitch shift를 반영하는 경우 성능을 더욱 향상할 수 있음
반응형
'Paper > SVS' 카테고리의 다른 글
댓글