
티스토리 뷰
Paper/Conversion
[Paper 리뷰] ACE-VC: Adaptive and Controllable Voice Conversion using Explicitly Disentangled Self-Supervised Speech Representations
feVeRin 2024. 9. 2. 09:41반응형
ACE-VC: Adaptive and Controllable Voice Conversion using Explicitly Disentangled Self-Supervised Speech Representations
- Voice conversion을 위해 self-supervised learning으로 얻어진 speech representation을 활용할 수 있음
- ACE-VC
- Content/speaker representation을 disentangle 하기 위해 original과 pitch-shifted audio content representation 간의 similarity에 기반한 siamese network를 활용
- Decomposed representation으로부터 speech signal을 reconstruct 하는 pitch, duration predictor를 도입
- 논문 (ICASSP 2023) : Paper Link
1. Introduction
- Non-parallel Voice Conversion (VC)은 linguistic content와 speaker characteristic을 disentangle 하는 것이 중요함
- 일반적으로 content, speaker information을 disentangle 하기 위해 pre-trained automatic speech recognition (ASR)이나 speaker verification (SV) model을 활용함
- BUT, mispronunciation 문제가 발생하고, speaker-independent style을 효과적으로 capture 하지 못하므로 neutral-sounding speech가 생성됨 - 한편으로 FragmentVC와 같이 self-supervised learning (SSL) representation을 활용할 수도 있음
- SSL representation은 phonetic information과 highly-correlate 되어 있어 VC task에 효과적임
- 이때 disentangled linguistic content를 추출하기 위해, SSL representation을 quantize 하는 방식을 활용 가능
- BUT, lossy compression으로 인해 reconstruction 품질이 저하되고, quantized representation에 speaker information이 포함되지 않는다는 것을 보장할 수 없음
- 일반적으로 content, speaker information을 disentangle 하기 위해 pre-trained automatic speech recognition (ASR)이나 speaker verification (SV) model을 활용함
-> 그래서 SSL representation에서 speaker/linguistic content를 효과적으로 disentangle 하는 ACE-VC를 제안
- ACE-VC
- SSL representation에 대한 disentangling을 향상하기 위해 Speech Representation Extractor (SRE)를 도입
- ASR, SV의 두 가지 downstream task에 대해 multi-task manner로 train 된 Conformer-SSL model을 활용
- Training 중에 content/speaker disentangling을 위해 pitch-shift transform을 적용한 다음, cosine-similarity loss가 포함된 siamese network를 통해 content embedding similarity를 반영
- 이후 해당 SRE representation으로부터 reconstruction을 수행하는 synthesis network를 설계
- Content, speaker representation 모두에서 fundamental frequency와 token duration을 예측하는 learnable intermediate model을 통합
- SSL representation에 대한 disentangling을 향상하기 위해 Speech Representation Extractor (SRE)를 도입
< Overall of ACE-VC >
- Qunatization이나 compression 없이 SSL representation을 효과적으로 disentangle 하는 VC model
- 결과적으로 기존보다 뛰어난 conversion 성능을 달성
2. Method
- ACE-VC는 크게 3가지 component로 구성됨
- SSL-based Speech Representation Extractor (SRE)
- Upstream mel-spectrogram synthesizer
- HiFi-GAN vocoder
- Speech Representation Extractor (SRE)
- SRE는 주어진 audio waveform에서 disentangled speaker와 content representation을 추출하는 것을 목표로 함
- 이를 위해 논문은 self-supervised manner로 train 된 Conformer를 backbone framework로 활용
- 구조적으로 Conformer는 multi-head self-attention block과 convolution을 결합하여 local/long-term dependency를 modeling 함
- 이때 mel-spectrogram representation을 기반으로 contrastive loss를 사용해 masked input의 quantized value를 예측하도록 training 됨 - 즉, mel-spectrogram $x=(x_{1},...,x_{T})$가 frame sequence로 주어지면, Conformer $E$는 vector $z=E(x)=(z_{1},...,z_{T'})$의 sequence를 output 함
- 구조적으로 Conformer는 multi-head self-attention block과 convolution을 결합하여 local/long-term dependency를 modeling 함
- 다음으로 pre-trained SRE backbone에서 linguistic content와 speaker representation을 추출하기 위해, 논문은 2개의 randomly initialized downstream head를 추가함
- 이후 Speech Recognition, Speaker Verification task를 위한 multi-task training을 수행 - Speech Recognition
- Speech recognition에 대한 downstream head는 2개의 linear layer로 구성됨
- 첫 번째 linear layer는 SRE backbone output을 content embedding sequence $z_{c}=f_{\theta_{c1}}(z)=z_{c1}...z_{cT'}$에 mapping 함
- 두 번째 linear layer는 softmax를 적용하여 각 time step의 content embedding을 language token에 대한 probability score에 $p_{c}=f_{\theta_{c2}}(z_{c})=p_{c1}...p_{cT'}$과 같이 mapping 함 - Speech recognition downstream head는 audio-text pair $(x,y_{c})$에서 CTC loss를 최적화하여 training 됨:
- 즉, $\mathcal{L}_{content}=\text{CTCLoss}(p_{c},y_{c})$
- Speech recognition에 대한 downstream head는 2개의 linear layer로 구성됨
- Speaker Verification (SV)
- Speaker verification head도 마찬가지로 2개의 linear layer로 구성됨
- 첫 번째 layer에서는 전체 utterance를 single speaker representation에 mapping 하기 위해, first time-step의 Confomer output을 speaker embedding $z_{s}=f_{\theta_{s1}}(z_{1})$에 mapping 함
- 두 번째 layer는 speaker embedding을 dataset 내의 모든 speaker에 대한 score $p_{s}=f_{\theta_{s2}}(z_{s})$에 mapping 함 - SV head는 audio-speaker pair $(x,y_{s})$에서 angular softmax loss를 최적화하여 train 됨:
- 즉, $\mathcal{L}_{SV}=\text{AngularSoftMax}(p_{s},y_{s})$
- Speaker verification head도 마찬가지로 2개의 linear layer로 구성됨
- Multi-task Training
- VoxCeleb와 같은 speaker-verification dataset에는 text transcript가 없으므로, 논문은 각 training iteration 중에 두 task에 대한 mini-batch를 load 하고 task-specific loss를 계산함
- 이때 두 loss를 결합하여 $\mathcal{L}_{multi}=\mathcal{L}_{content}+\alpha\mathcal{L}_{SV}$를 얻고, downstream head와 Conformer backbone으로 backpropagate 함
- Downstream network parameter에 대해서는 $10^{-4}$의 learning rate를 가지는 Adam optimizer를 사용하고, Conformer backbone에 대해서는 $10^{-5}$의 learning rate를 사용
- 이는 fine-tuning 중에 Conformer의 overfitting을 방지하기 위함
- Disentangling Content and Speaker Representations
- 앞선 multi-task training을 단순히 적용하면 speaker information이 linguistic content embedding $z_{c}$로 leaking 할 수 있음
- 이는 SSL encoding $z$가 speaker, linguistic content information을 모두 포함하기 때문
- 따라서 적절한 disentanglement가 없으면 network는 speaker embedding $z_{s}$를 ignore 하게 되므로 VC 성능이 저하됨 - 이를 해결하기 위해 논문은 training 중에 pitch-shift data augmentation을 사용하여 주어진 utterance $x$를 변경하여 pitch-shifted audio $x'$을 얻음
- 다음으로, siamese cosine-similarity loss를 적용하여 original $z_{c}=f_{\theta_{c1}}(E(x))$와 pitch-shifted audio $z'_{c}=f_{\theta_{c1}}(E(x'))$ 간의 content embedding similarity를 반영:
(Eq. 1) $\mathcal{L}_{disentangle}=1-S_{\cos}(z_{c},z'_{c})$
- $S_{\cos}$ : cosine-similarity - 결과적으로 해당 disentanglement loss를 multi-task training loss에 추가하여 $\mathcal{L}_{SRE}=\mathcal{L}_{multi}+\beta\mathcal{L}_{disentanglement}$를 얻음
- 이를 통해 content embedding이 speaker-independent 하도록 유도하여 disentanglement를 보장할 수 있음
- 앞선 multi-task training을 단순히 적용하면 speaker information이 linguistic content embedding $z_{c}$로 leaking 할 수 있음
- 이를 위해 논문은 self-supervised manner로 train 된 Conformer를 backbone framework로 활용

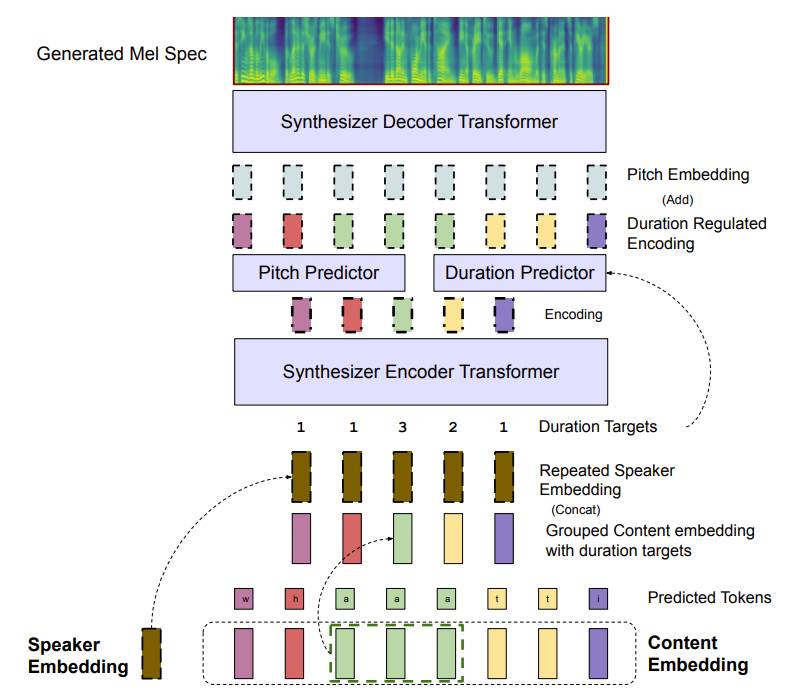
- Mel-Spectrogram Synthesizer
- Synthesizer는 SRE representation으로부터 mel-spectrogram을 reconstruct 하는 것을 목표로 함
- 이때 content representation $z_{c}$의 temporal characteristic과 length가 speakering rate, total duration을 결정함
- 따라서 SRE의 raw output에서 train 된 synthesizer는 $z_{c}$로부터 speaking rate를 결정할 수 있으므로, 다른 target speaker embedding $z'_{s}$의 speaker rate를 adapt 할 필요가 없음 - 이를 위해 ACE-VC는 동일한 predicted token을 가지는 consecutive content vector를 grouping 하여 raw content representation $z_{c}$를 처리함
- 먼저 time step $i$에서 $j$까지 동일한 predicted language token을 가지는 consecutive content vector $z_{ci},...,z_{cj}$가 있다고 하자
- 즉, $\arg\max(p_{ci})=...=\arg\max(p_{cj})$ - 해당 consecutive vector를 group 하고 temporal dimension에 따라 average 하여 time step $t$에 대한 new vector $g_{ct}=\text{average}(z_{ci}...z_{cj})$를 얻을 수 있음
- $g_{ct}$에 대한 target ground-truth duration은 grouped vector 수 $d_{ct}=j-i+1$과 같음 - 결과적으로 해당 과정을 모든 time-step에 대해 repeating 하면, grouped content representation와 target duration을 $g_{c},d_{c}=G(z_{c})$와 같이 얻을 수 있음
- 먼저 time step $i$에서 $j$까지 동일한 predicted language token을 가지는 consecutive content vector $z_{ci},...,z_{cj}$가 있다고 하자
- 이후 논문은 audio duration $d_{c}$와 fundamental frequency $p$를 content embedding $g_{c}$와 speaker embedding $z_{s}$의 function으로 modeling 함
- 이를 위해 $g_{c}, z_{s}$를 input으로 하여, FastPitch를 따르는 2개의 feed-forward transformer $F_{e},F_{d}$를 활용
- 먼저, 첫 번째 transformer의 hidden representation은 duration, pitch를 예측하는데 사용됨
- 즉, $h=F_{e}(g_{c},z_{s}), \hat{d}=\text{DurationPredictor}(h), \hat{p}=\text{PitchPredictor}(h)$ - 다음으로 pitch contour는 hidden representation $h$의 각 time step에 걸쳐 project 되고 average 되어 $h$에 추가됨
- 즉, $k=h+\text{PitchEmbedding}(p)$ - 최종적으로 $k$는 ground-truth duration $d_{c}$에 따라 discretely upsample 된 다음, 두 번째 transformer로 전달되어 predicted mel-spectrogram $\hat{y}=F_{d}(\text{DurationRegulation}(k,d_{c}))$를 output 함
- 이를 위해 $g_{c}, z_{s}$를 input으로 하여, FastPitch를 따르는 2개의 feed-forward transformer $F_{e},F_{d}$를 활용
- Synthesizer는 text-free manner로 multi-speaker dataset을 통해 training 되고, 이때 ground-truth pitch contour $p$는 Yin algorithm으로 얻어짐
- 이때 각 utterance의 pitch contour는 주어진 speaker의 pitch contour에 대한 평균과 표준편차를 통해 normalize 됨
- 해당 per-speaker normalization은 pitch contour가 time에 따른 prosodic change만 capture 하도록 함 - 결과적으로 synthesizer는 mel-reconstruction error, pitch prediction error, duration prediction error로 최적화됨:
(Eq. 2) $\mathcal{L}_{synth}=|| \hat{y}-y||_{2}^{2}+\lambda_{1}|| \hat{p}-p||_{2}^{2}+\lambda_{2}|| \hat{d}-d_{c}||_{2}^{2}$
- 이때 content representation $z_{c}$의 temporal characteristic과 length가 speakering rate, total duration을 결정함
3. Experiments
- Settings
- Dataset : LibriSpeech, VoxCeleb2
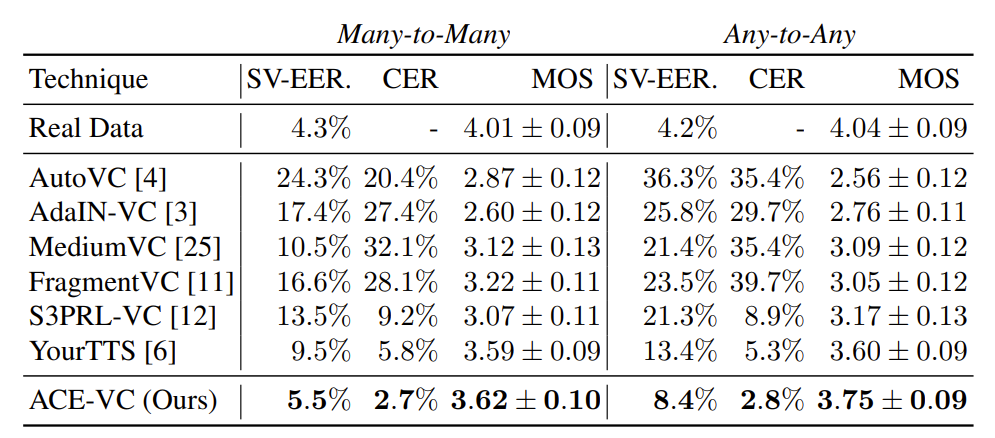
- Comparisons : AutoVC, AdaIN-VC, FragmentVC, MediumVC, S3PRL-VC, YourTTS
- Results
- Feature Disentanglement
- $\mathcal{L}_{disentangle}$을 사용한 content representation이 가장 낮은 speaker classification accuracy를 보임
- 즉, content representation에 speaker information이 가장 적게 포함되어 있음
- $\mathcal{L}_{disentangle}$을 사용한 content representation이 가장 낮은 speaker classification accuracy를 보임

- Voice Conversion
- Conversion 성능 측면에서도 ACE-VC가 가장 우수한 성능을 보임
반응형
'Paper > Conversion' 카테고리의 다른 글
댓글