

 [Paper 리뷰] PeriodGrad: Towards Pitch-Controllable Neural Vocoder based on a Diffusion Probabilistic Model
[Paper 리뷰] PeriodGrad: Towards Pitch-Controllable Neural Vocoder based on a Diffusion Probabilistic Model
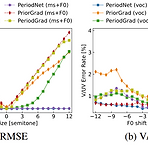
PeriodGrad: Towards Pitch-Controllable Neural Vocoder based on a Diffusion Probabilistic Model Diffuision-based vocoder는 고품질의 합성이 가능하고 간단한 time-domain loss로 학습할 수 있지만 pitch control이 어려움 PeriodGrad Explicit periodic signal을 auxiliary conditioning signal로써 Denoising Diffusion Probabilistic Model에 통합 Waveform의 periodic structure를 정확하게 capture 하여 pitch controllability를 향상 논문 (ICASSP 2024) : Paper Li..
 [Paper 리뷰] Denoising Diffusion Probabilistic Models
[Paper 리뷰] Denoising Diffusion Probabilistic Models
Denoising Diffusion Probabilistic Models Nonequilibrium thermodynamics에서 영감을 받은 latent variable model인 diffusion probabilistic model을 사용하여 고품질의 이미지 합성을 시도 Denoising Diffusion Probabilistic Model (DDPM) Diffusion probabilistic model과 Langevin dynamics를 연결하는 denoising score matching을 활용 Autoregressive decoding의 generalization으로 해석될 수 있는 progressive lossy decompression을 허용 논문 (NeurIPS 2020) : Paper..
 [Paper 리뷰] FreGrad: Lightweight and Fast Frequency-aware Diffusion Vocoder
[Paper 리뷰] FreGrad: Lightweight and Fast Frequency-aware Diffusion Vocoder
FreGrad: Lightweight and Fast Frequency-aware Diffusion Vocoder Lightweight, fast diffusion-based vocoder를 사용하여 사실적인 audio를 합성할 필요가 있음 FreGrad 복잡한 waveform을 sub-band wavelet으로 decompose 하는 discrete wavelet transform을 적용 Frequency awareness를 높이는 frequency-aware dilated convolution을 도입 합성 품질을 향상할 수 있는 추가적인 bag of tricks를 소개 논문 (ICASSP 2024) : Paper Link 1. Introduction Neural vocoder는 mel-spectrog..
 [Paper 리뷰] WaveGrad: Estimating Gradients for Waveform Generation
[Paper 리뷰] WaveGrad: Estimating Gradients for Waveform Generation
WaveGrad: Estimating Gradients for Waveform Generation Score mathcing과 diffusion probabilistic model을 waveform generation에 활용할 수 있음 WaveGrad Data density의 gradient를 추정하는 waveform generation을 위한 conditional model Gaussian white noise에서 시작하여 mel-spectrogram에 따라 condition 된 gradient-based sampler를 활용 논문 (ICRL 2021) : Paper Link 1. Introduction Autorgressive 모델을 raw waveform 생성에서 활용할 수 있지만, sequenti..
 [Paper 리뷰] EmoDiff: Intensity Controllable Emotional Text-to-Speech with Soft-Label Guidance
[Paper 리뷰] EmoDiff: Intensity Controllable Emotional Text-to-Speech with Soft-Label Guidance
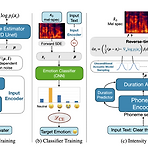
EmoDiff: Intensity Controllable Emotional Text-to-Speech with Soft-Label Guidance 최신 Text-to-Speech 모델들은 고품질 음성을 합성할 수 있지만, emotion에 대한 intensity controllability는 떨어짐 - Intensity 계산을 위한 external optimization이 필요하기 때문 EmoDiff Classifier guidance에서 파생된 soft-label guidance를 diffusion 기반 text-to-speech 모델에 적용 Specified emotion과 Neutral을 emotion intensity $\alpha, 1-\alpha$로 나타내는 soft-label을 활용 논문 (I..
 [Paper 리뷰] DiffWave: A Versatile Diffusion Model for Audio Synthesis
[Paper 리뷰] DiffWave: A Versatile Diffusion Model for Audio Synthesis
DiffWave: A Versatile Diffusion Model for Audio Synthesis Conditional/Unconditional waveform generation을 위해 diffusion probabilistic model을 사용할 수 있음 DiffWave Non-autoregressive 하고 Markov chain을 통해 white noise signal을 waveform으로 변환하는 모델 - Data likelihood에 대한 variational bound를 최적화함으로써 학습됨 Mel-spectrogram에 따라 condition 된 neural vocoding, class-conditional generation, unconditional generation 작업에서 활..