

 [Paper 리뷰] Diffusion-Based Generative Speech Source Separation
[Paper 리뷰] Diffusion-Based Generative Speech Source Separation
Diffusion-Based Generative Speech Source Separation Source separation을 위해 Stochastic Differential Equation을 활용할 수 있음 DiffSep 분리된 source에서 시작해 mixture를 중심으로 하는 Gaussian 분포로 수렴하는 continuous time diffusion-mixing proces를 활용 Diffusion-mixing process의 score function에 대한 marginal probability를 근사하는 neural network를 훈련 Neural network를 활용하여 mixture에서 source를 점진적으로 분리하는 reverse-time SDE를 solve 논문 (ICASSP 2..
 [Paper 리뷰] Diff-TTS: A Denoising Diffusion Model for Text-to-Speech
[Paper 리뷰] Diff-TTS: A Denoising Diffusion Model for Text-to-Speech
Diff-TTS: A Denoising Diffusion Model for Text-to-Speech Neural text-to-speech 모델은 여전히 자연스러운 합성과 architecture 효율성이 요구됨 Diff-TTS 주어진 text에 대해 denoising diffusion을 활용하여 noise signal을 mel-spectrogram으로 변환 Text를 condition으로 하는 mel-spectrogram 분포를 학습하기 위한 likelihood-based optimization 추론 속도 향상을 위한 accelerated sampling의 도입 논문 (INTERSPEECH 2021) : Paper Link 1. Introduction 대부분의 neural text-to-speech (..
 [Paper 리뷰] LightGrad: Lightweight Diffusion Probabilistic Model for Text-to-Speech
[Paper 리뷰] LightGrad: Lightweight Diffusion Probabilistic Model for Text-to-Speech
LightGrad: Lightweight Diffusion Probabilistic Model for Text-to-SpeechText-to-Speech 모델은 효율적인 일상 활용을 위해 edge device에 배포하는 것이 요구됨Diffusion probabilistic model 은 다른 생성 모델들에 비해 안정적으로 학습되고 parameter 효율성이 높음LightGradEdge device에서 TTS를 활용하기 위한 경량 diffusion probabilistic model 경량 U-Net diffusion decoder와 빠른 sampling, streaming inference를 통한 latency 감소논문 (ICASSP 2023) : Paper Link1. Introduction일상생활에서..
 [Paper 리뷰] Hierarchical Diffusion Models for Singing Voice Neural Vocoder
[Paper 리뷰] Hierarchical Diffusion Models for Singing Voice Neural Vocoder
Hierarchical Diffusion Models for Singing Voice Neural Vocoder Pitch, loudness, pronunciation 같은 다양한 음악적 표현으로 인해 neural vocoder로 고품질의 가창 음성을 합성하는 것은 어려움 서로 다른 sampling rate에 대한 multiple diffusion model을 도입 HPG (Hierarchical Diffusion Model + PriorGrad) Lower sampling rate 모델은 pitch와 같은 저주파 요소를 합성 다른 모델은 lower sampling rate와 acoustic feature를 기반으로 higher sampling rate waveform을 점진적으로 합성 논문 (ICASS..
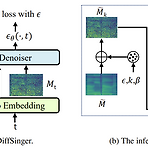 [Paper 리뷰] DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism
[Paper 리뷰] DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism Singing Voice Synthesis (SVS)는 음향 feature 재구성을 위해 간단한 Loss나 GAN을 활용함 각각의 방식은 over-smoothing 문제와 불안정한 학습과정으로 인해 부자연스러운 음성을 만들어냄 DiffSinger Diffusion probabilistic 모델 기반의 SVS용 음향 모델 조건부 분포 하에서 노이즈를 mel-spectrogram으로 반복적으로 변환하는 parameterized Markov chain Variational bound를 최적화함으로써 안정적이고 자연스러운 음성을 합성 논문 (AAAI 2022) : Paper Link 1. I..