
 [Paper 리뷰] MaskCycleGAN-VC: Learning Non-Parallel Voice Conversion with Filling in Frames
[Paper 리뷰] MaskCycleGAN-VC: Learning Non-Parallel Voice Conversion with Filling in Frames
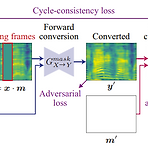
MaskCycleGAN-VC: Learning Non-Parallel Voice Conversion with Filling in FramesNon-parallel voice conversion을 위한 Cycle-Consistent Adversarial Network-based 방식은 time-frequency structure를 capture 하는 능력이 부족함MaskCycleGAN-VCCycleGAN-VC2의 확장으로써 Filling in Frames를 통해 training 하여 얻어짐Filling in Frames를 사용하여 input mel-spectrogram에 temporal mask를 적용하고 converter가 surrounding frame을 기반으로 missing frame을 fillin..
 [Paper 리뷰] CycleGAN-VC3: Examining and Improving CycleGAN-VCs for Mel-Spectrogram Conversion
[Paper 리뷰] CycleGAN-VC3: Examining and Improving CycleGAN-VCs for Mel-Spectrogram Conversion
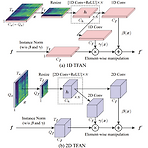
CycleGAN-VC3: Examining and Improving CycleGAN-VCs for Mel-Spectrogram ConversionNon-parallel voice conversion에서 CycleGAN-VC가 우수한 성능을 보임- BUT, mel-spectrogram conversion에 대한 ambiguity로 인해 time-frequency structure가 손상됨CycleGAN-VC3Time-Frequency Adaptive Normalization을 도입하여 time-frequency structure를 반영기존 CycleGAN의 mel-spectrogram conversion 성능을 향상논문 (INTERSPEECH 2020) : Paper Link1. IntroductionVo..
 [Paper 리뷰] AVQVC: One-Shot Voice Conversion by Vector Quantization with Applying Contrastive Learning
[Paper 리뷰] AVQVC: One-Shot Voice Conversion by Vector Quantization with Applying Contrastive Learning
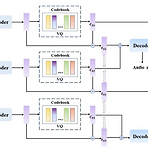
AVQVC: One-Shot Voice Conversion by Vector Quantization with Applying Contrastive LearningVoice conversion은 speech signal에서 timbre와 linguistic content를 disentangle 하여 수행될 수 있음AVQVCVQVC와 AutoVC를 결합한 one-shot voice conversion frameworkContent, timbre를 분리하기 위한 training method를 VQVC에 적용논문 (ICASSP 2022) : Paper Link1. IntroductionVoice Conversion (VC)는 original utterance의 content를 유지하면서 target speake..
 [Paper 리뷰] StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion
[Paper 리뷰] StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion
StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice ConversionUnsupervised non-parallel many-to-many voice conversion을 위해 generative adversarial network를 활용할 수 있음StarGANv2-VCAdversarial source classifier loss와 perceptual loss를 결합하여 사용Style encoder를 통해 plain reading speech를 stylistic speech로 변환논문 (INTERSPEECH 2021) : Paper Link1. IntroductionVoice Conversion (..
 [Paper 리뷰] Blow: A Single-Scale Hyperconditioned Flow for Non-Parallel Raw-Audio Voice Conversion
[Paper 리뷰] Blow: A Single-Scale Hyperconditioned Flow for Non-Parallel Raw-Audio Voice Conversion
Blow: A Single-Scale Hyperconditioned Flow for Non-Parallel Raw-Audio Voice ConversionMany-to-Many voice conversion을 위해서는 non-parallel data를 활용할 수 있어야 함BlowHypernetwork conditioning과 single-scale normalizing flow를 활용Single speaker identifier를 사용하여 frame-by-frame으로 end-to-end training 됨논문 (NeurIPS 2019) : Paper Link1. IntroductionRaw audio는 intermediate representation을 사용하는 것보다 더 많은 model capacit..
 [Paper 리뷰] FragmentVC: Any-to-Any Voice Conversion by End-to-End Extracting and Fusing Fine-Grained Voice Fragments with Attention
[Paper 리뷰] FragmentVC: Any-to-Any Voice Conversion by End-to-End Extracting and Fusing Fine-Grained Voice Fragments with Attention
FragmentVC: Any-to-Any Voice Conversion by End-to-End Extracting and Fusing Fine-Grained Voice Fragments with AttentionAny-to-Any voice conversion은 unseen any speaker에 대해 voice conversion을 수행하는 것을 목표로 함FragmentVCWav2Vec 2.0을 통해 source speaker의 latent phonetic structure를 얻고 target speaker의 spectral feature를 log mel-spectrogram을 통해 얻음두 가지의 서로 다른 feature space를 two-stage training process를 통해 align ..