

티스토리 뷰
Paper/Conversion
[Paper 리뷰] MaskCycleGAN-VC: Learning Non-Parallel Voice Conversion with Filling in Frames
feVeRin 2024. 8. 22. 10:27반응형
MaskCycleGAN-VC: Learning Non-Parallel Voice Conversion with Filling in Frames
- Non-parallel voice conversion을 위한 Cycle-Consistent Adversarial Network-based 방식은 time-frequency structure를 capture 하는 능력이 부족함
- MaskCycleGAN-VC
- CycleGAN-VC2의 확장으로써 Filling in Frames를 통해 training 하여 얻어짐
- Filling in Frames를 사용하여 input mel-spectrogram에 temporal mask를 적용하고 converter가 surrounding frame을 기반으로 missing frame을 filling 하도록 함
- 논문 (ICASSP 2021) : Paper Link
1. Introduction
- Voice Conversion (VC)는 linguistic content를 변경하지 않고 target speaker의 voice로 변환하는 것을 목표로 함
- 일반적으로 VC task는 parallel data를 활용하여 source speaker와 target speaker 간의 conversion을 학습하는 방식으로 수행됨
- BUT, parallel corpus는 수집하기 어렵다는 한계가 있으므로 non-parallel data도 활용할 수 있어야 함 - 이를 위해 StarGAN-VC와 같은 Generative Adversarial Network (GAN) 기반의 방식들이 주로 활용됨
- BUT, 기존의 GAN-based VC는 time-frequency structure를 capture하지 못하므로 성능의 한계가 있음
- 한편으로 CycleGAN-VC3는 time-frequency adaptive normalization (TFAN)을 도입하여 성능을 크게 개선했지만, parameter efficiency가 크게 저하되는 문제가 있음
- 일반적으로 VC task는 parallel data를 활용하여 source speaker와 target speaker 간의 conversion을 학습하는 방식으로 수행됨
-> 그래서 효과적인 mel-spectrogram conversion과 적은 network modification을 지원하는 MaskCycleGAN-VC를 제안
- MaskCycleGAN-VC
- CycleGAN-VC2를 기반으로 auxiliary task인 Filling in Frame (FIF)를 도입해 training함
- FIF는 input mel-spectrogram에 temporal mask를 적용하고 converter가 surrounding frame을 기반으로 missing framer을 filling 하도록 함
- 이를 통해 self-supervised manner로 time-frequency feature를 학습함으로써 TFAN과 같은 additional module에 대한 의존성을 제거
< Overall of MaskCycleGAN-VC >
- CycleGAN-VC2를 기반으로 FIF task를 도입
- 결과적으로 기존보다 적은 parameter 수를 가지면서 뛰어난 conversion 성능을 달성
2. Conventional CycleGAN-VC2
- CycleGAN-VC2는 parallel supervision 없이 source acoustic feature $\mathbf{x}\in X$를 target acoustic feature $\mathbf{y}\in Y$로 변환하는 converter $G_{X\rightarrow Y}$를 training 함
- 이를 위해 adversarial loss, cycle-consistency loss, identity-mapping loss를 활용
- 추가적으로 second adversarial loss를 도입해 cyclically reconstructed feature의 품질을 개선
- Adversarial Loss
- Adversarial loss $\mathcal{L}_{adv}^{X\rightarrow Y}$는 converted feature $G_{X\rightarrow Y}(\mathbf{x})$가 target과 같아지도록 함:
(Eq. 1) $\mathcal{L}_{adv}^{X\rightarrow Y}=\mathbb{E}_{\mathbf{y}\sim P_{Y}}[\log D_{Y}(\mathbf{y})]+\mathbb{E}_{\mathbf{x}\sim P_{X}}\left[\log (1-D_{Y}(G_{X\rightarrow Y}(\mathbf{x})))\right]$ - Discriminator $D_{Y}$는 해당 loss를 최대화하여 생성된 $G_{X\rightarrow Y}(\mathbf{x})$와 real $\mathbf{y}$를 distinguish 함
- 반대로 $G_{X\rightarrow Y}$는 해당 loss를 최소화하여 $D_{Y}$를 deceive 하는 $G_{X\rightarrow Y}(\mathbf{x})$를 생성함 - Inverse converter $G_{Y\rightarrow X}$는 discriminator $D_{X}$를 사용하여 $\mathcal{L}_{adv}^{Y\rightarrow X}$를 통해 학습됨
- Adversarial loss $\mathcal{L}_{adv}^{X\rightarrow Y}$는 converted feature $G_{X\rightarrow Y}(\mathbf{x})$가 target과 같아지도록 함:
- Cycle-Consistency Loss
- Cycle-consistency loss $\mathcal{L}_{cyc}^{X\rightarrow Y\rightarrow X}$는 parallel supervision 없이 cycle-consistency constraint 내에서 pseudo pair를 결정하는데 사용됨:
(Eq. 2) $\mathcal{L}_{cyc}^{X\rightarrow Y\rightarrow X}=\mathbb{E}_{\mathbf{x}\sim P_{X}}\left[||G_{Y\rightarrow X}(G_{X\rightarrow Y}(\mathbf{x}))-\mathbf{x} ||_{1}\right]$ - Inverse-forward mapping $G_{X\rightarrow Y}( G_{Y\rightarrow X}(\mathbf{y}))$에서는 $\mathcal{L}_{cyc}^{Y\rightarrow X\rightarrow Y}$를 사용
- Cycle-consistency loss $\mathcal{L}_{cyc}^{X\rightarrow Y\rightarrow X}$는 parallel supervision 없이 cycle-consistency constraint 내에서 pseudo pair를 결정하는데 사용됨:
- Identity-Mapping Loss
- Identity-mapping loss $\mathcal{L}_{id}^{X\rightarrow Y}$는 input preservation을 위해 사용됨:
(Eq. 3) $\mathcal{L}_{id}^{X\rightarrow Y}=\mathbb{E}_{\mathbf{y}\sim P_{Y}}\left[|| G_{X\rightarrow Y}(\mathbf{y})-\mathbf{y}||_{1}\right]$ - Inverse converter $G_{Y\rightarrow X}$에는 $\mathcal{L}_{id}^{Y\rightarrow X}$가 사용됨
- Identity-mapping loss $\mathcal{L}_{id}^{X\rightarrow Y}$는 input preservation을 위해 사용됨:
- Second Adversarial Loss
- Second adversarial loss $\mathcal{L}_{adv2}^{X\rightarrow Y\rightarrow X}$는 (Eq. 2)의 $L1$ loss로 발생하는 statistical averaging을 완화하기 위해 사용됨:
(Eq. 4) $\mathcal{L}_{adv2}^{X\rightarrow Y\rightarrow X}=\mathbb{E}_{\mathbf{x}\sim P_{X}}[\log D'_{X}(\mathbf{x})]+\mathbb{E}_{\mathbf{x}\sim P_{X}}\left[\log \left(1-D'_{X}(G_{Y\rightarrow X}(G_{X\rightarrow Y}(\mathbf{x})) )\right)\right]$
- Discriminator $D'_{X}$는 reconstructed $G_{Y\rightarrow X}(G_{X\rightarrow Y}(\mathbf{x}))$와 real $\mathbf{x}$를 distinguish 함 - Inverse-forward mapping에는 discriminator $D'_{Y}$와 함께 $\mathcal{L}_{adv2}^{Y\rightarrow X\rightarrow Y}$가 사용됨
- Second adversarial loss $\mathcal{L}_{adv2}^{X\rightarrow Y\rightarrow X}$는 (Eq. 2)의 $L1$ loss로 발생하는 statistical averaging을 완화하기 위해 사용됨:
- Full Objectives
- 최종적으로 얻어지는 full objective $\mathcal{L}_{full}$은:
(Eq. 5) $\mathcal{L}_{full}=\mathcal{L}_{adv}^{X\rightarrow Y}+\mathcal{L}_{adv}^{Y\rightarrow X}+\lambda_{cyc}\left( \mathcal{L}_{cyc}^{X\rightarrow Y\rightarrow X}+\mathcal{L}_{cyc}^{Y\rightarrow X\rightarrow Y}\right)+\lambda_{id}\left(\mathcal{L}_{id}^{X\rightarrow Y}+\mathcal{L}_{id}^{Y\rightarrow X}\right)+\mathcal{L}_{adv2}^{X\rightarrow Y\rightarrow X}+\mathcal{L}_{adv2}^{Y\rightarrow X\rightarrow Y}$
- $\lambda_{cyc}, \lambda_{id}$ : weighing parameter - $G_{X\rightarrow Y}, G_{Y\rightarrow X}$는 해당 loss를 최대화하여 최적화되고 $D_{X},D_{Y},D'_{X},D'_{Y}$는 해당 loss를 최소화하여 최적화됨
- 최종적으로 얻어지는 full objective $\mathcal{L}_{full}$은:
3. MaskCycleGAN-VC
- Training with Filling in Frames (FIF)
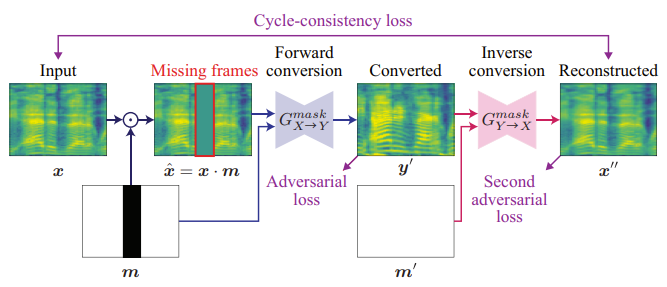
- 기존의 CycleGAN-VC2는 time-frequency structure를 capture 하는 능력이 부족해 harmonic structure가 compromise되므로, MaskCycleGAN-VC는 아래 그림과 같은 auxiliary FIF task를 도입함
- 먼저 source mel-spectrogram $\mathbf{x}$가 주어지면, temporal mask $\mathbf{m}\in M$을 생성함
- 해당 mask는 $\mathbf{x}$와 size가 동일하고, 값이 0인 부분과 값이 1인 부분으로 나누어짐
- Masked region (0 region)은 predetermined rule에 따라 random 하게 결정됨 - 여기서 mask $\mathbf{m}$을 $\mathbf{x}$에 적용하면:
(Eq. 6) $\hat{\mathbf{x}}=\mathbf{x}\cdot \mathbf{m}$
- $\cdot$ : element-wise product - (Eq. 6)을 통해 아래 그림의 red box 부분과 같은 artificially missing frame을 얻을 수 있음
- 해당 mask는 $\mathbf{x}$와 size가 동일하고, 값이 0인 부분과 값이 1인 부분으로 나누어짐
- 다음으로 MaskCycleGAN-VC converter $G_{X\rightarrow Y}^{mask}$는 $\hat{\mathbf{x}}, \mathbf{m}$으로부터 $\mathbf{y}'$을 합성함:
(Eq. 7) $\mathbf{y}'=G_{X\rightarrow Y}^{mask}(\text{concat}(\hat{\mathbf{x}},\mathbf{m}))$
- $\text{concat}$ : channel-wise concatentation
- Conditional information으로 $\mathbf{m}$을 사용하면 $G_{X\rightarrow Y}^{mask}$는 어떤 frame을 filling 해야 하는지를 알 수 있음 - CycleGAN-VC2와 유사하게 (Eq. 1)의 adversarial loss를 사용하여 $\mathbf{y}'$이 target $Y$에 속하는지 확인할 수 있지만, parallel supervision이 부족하므로 $\mathbf{y}'$를 ground-truth와 직접 비교하는 것은 어려움
- 따라서 논문에서는 cyclic conversion process를 통해 frame을 filling 하도록 함
- 즉, inverse converter $G_{Y\rightarrow X}^{mask}$를 사용하여 $\mathbf{x}''$를 reconstruct 함:
(Eq. 8) $\mathbf{x}''=G_{Y\rightarrow X}^{mask}(\text{concat}(\mathbf{y}',\mathbf{m}'))$
- $\mathbf{m}'$ : missing frame이 모두 filling 되었다는 가정 하에, all-ones matrix를 사용하여 represent 됨 - 다음으로 original, reconstructed mel-spectrogram에 대해 다음의 cycle-consistency loss를 적용:
(Eq. 9) $\mathcal{L}_{mcyc}^{X\rightarrow Y\rightarrow X}=\mathbb{E}_{\mathbf{x}\sim P_{X}, \mathbf{m}\sim P_{M}}\left[ || \mathbf{x}''-\mathbf{x}||_{1}\right]$
- (Eq. 4)의 second adversarial loss를 $\mathbf{x}''$에 대해 적용한 것과 같음
- $\mathcal{L}_{mcyc}^{X\rightarrow Y\rightarrow X}$를 최적화하기 위해 $G^{mask}_{X\rightarrow Y}$는 surrounding frame에서 missing frame을 filling 하는데 유용한 information을 얻어야 함
- 해당 방식은 self-supervision manner로 mel-spectrogram에서 time-frequency structure를 학습하도록 지원할 수 있음
- 결과적으로 MaskCycleGAN-VC는 TFAN에 의존하는 CycleGAN-VC3와 달리 converter parameter 수가 증가되지 않고, FIF는 self-supervised learning과 비슷하게 동작하므로 추가적인 data나 pretrain이 필요하지 않음
- 먼저 source mel-spectrogram $\mathbf{x}$가 주어지면, temporal mask $\mathbf{m}\in M$을 생성함
- Conversion with All-Ones Mask
- Conversion process에서는 all-ones mask를 사용함
- 따라서 missing frame이 없다는 가정하에 speech conversion을 수행할 수 있음
- 해당 가정은 일반적인 VC task와 동일
4. Experiments
- Settings
- Dataset : VCC2018
- Comparisons : CycleGAN-VC3, CycleGAN-CV2
- Results
- 전체적으로 MaskCycleGAN-VC가 가장 우수한 성능을 보임

- Naturalness 측면에서도 높은 선호도를 보임

- Speaker similarity 측면에서도 MaskCycleGAN-VC가 가장 선호됨

반응형
'Paper > Conversion' 카테고리의 다른 글
댓글