

티스토리 뷰
Paper/Conversion
[Paper 리뷰] AVQVC: One-Shot Voice Conversion by Vector Quantization with Applying Contrastive Learning
feVeRin 2024. 8. 20. 09:01반응형
AVQVC: One-Shot Voice Conversion by Vector Quantization with Applying Contrastive Learning
- Voice conversion은 speech signal에서 timbre와 linguistic content를 disentangle 하여 수행될 수 있음
- AVQVC
- VQVC와 AutoVC를 결합한 one-shot voice conversion framework
- Content, timbre를 분리하기 위한 training method를 VQVC에 적용
- 논문 (ICASSP 2022) : Paper Link
1. Introduction
- Voice Conversion (VC)는 original utterance의 content를 유지하면서 target speaker로 변환하는 것을 목표로 함
- StarGANv2-VC와 같은 Generative Adversarial Network (GAN)-based 방식은 discriminator를 통해 generator가 indistinguishable speech를 생성하도록 유도함
- VQVC, VQVC+와 같이 Vector Quantization (VQ)을 사용하여 content, speaker information을 disentangle 하는 방법을 활용할 수도 있음
- BUT, VQ-based 방식은 간단한 training을 지원하지만 상대적으로 합성 품질이 떨어진다는 문제가 있음 - 한편으로 AutoVC는 GE2E loss로 pre-train 된 speaker encoder를 사용하여 ideal speaker embedding을 얻을 수 있고, 보다 reasonable 한 speaker/content disentanglement가 가능함
-> 그래서 AutoVC와 VQVC의 장점을 결합한 AVQVC를 제안
- AVQVC
- AutoVC를 기반으로 VQVC의 training을 재설계하여 speaker/content information을 disentangle 하도록 유도
- Disecrete vector는 content representation에 가까워지고, encoder output과 discrete vector 간의 mean difference는 speaker information에 가까워짐
< Overall of AVQVC >
- VQVC와 AutoVC를 결합한 voice conversion model
- 결과적으로 기존보다 뛰어난 conversion 성능을 달성
2. Method
- VQVC
- VQVC는 하나의 reconstruction loss 만으로 content embedding과 speaker embedding을 disentangle 함
- 구조적으로는 encoder, codebook, decoder로 구성됨
- Encoder는 input speech에서 latent feature를 추출하는 역할
- Learnable codebook은 continuous data를 discrete data로 quantize 하는 역할
- Decoder는 content, speaker embedding으로부터 converted speech를 생성하는 역할
- 이때 codebook에서 생성된 discrete data를 content embedding으로 취급하고, encoder output과 discrete data 간의 mean difference로 speaker embedding을 얻을 수 있음
- Discrete content embedding $\mathbf{C}_{x}$와 speaker embedding $\mathbf{S}_{x}$는:
(Eq. 1) $\mathbf{C}_{x}=\text{VQ}(\text{enc}(x)),\,\,\, \mathbf{S}_{x}=\mathbb{E}_{t}[\text{enc}(x)-\mathbf{C}_{x}]$
- $\text{enc}(\cdot)$ : encoder, $\mathbf{E}_{t}$ : latent space에서 segment length에 대한 expectation
- $\text{VQ}$ : continuous data sequence를 closest discrete code로 quantize 하는 quantization function - $\mathbf{V}$를 continuous data sequence $\mathbf{V}=v_{1},v_{2},...,v_{T}$라고 하면, $\text{VQ}(\mathbf{V})$는:
(Eq. 2) $\text{VQ}(\mathbf{V})=q_{1},q_{2},...,q_{T}$
(Eq. 3) $q_{j}=\arg\min_{q\in \text{Codebook}}(|| v_{j}-q||_{2}^{2})$
- Discrete content embedding $\mathbf{C}_{x}$와 speaker embedding $\mathbf{S}_{x}$는:
- Training 중에 하나의 utterance $x_{i}$가 reconsturction을 위해 randomly select 되면, latent-code loss는 discrete code와 continuous embedding 간의 distance를 최소화하도록 최적화됨
- 여기서 self-reconstruction loss는 speaker information을 제거하고 linguistic content를 retaining 하도록 model을 constrain 함:
(Eq. 4) $\mathcal{L}_{latent}=\mathbb{E}[|| \text{enc}(x)-\mathbf{C}_{x}||_{2}^{2}]$
(Eq. 5) $\mathcal{L}_{recon}=\mathbb{E}[|| \hat{x}_{i\rightarrow i}-x_{i}||_{1}^{1}]$
(Eq. 6) $\hat{x}_{i\rightarrow i}=\text{Decoder}(c_{x_{i}}+s_{x_{i}})$ - Conversion 시에는 서로 다른 speaker에 대한 2개의 utterance가 source/target speech로 사용됨
- 이때 각 utterance를 trained model에 전달하면 content, speaker embedding을 얻을 수 있음
- 이후 source speaker의 content embedding과 target speaker의 speaker embedding을 decoder에 전달하여 conversion을 수행함
- 구조적으로는 encoder, codebook, decoder로 구성됨

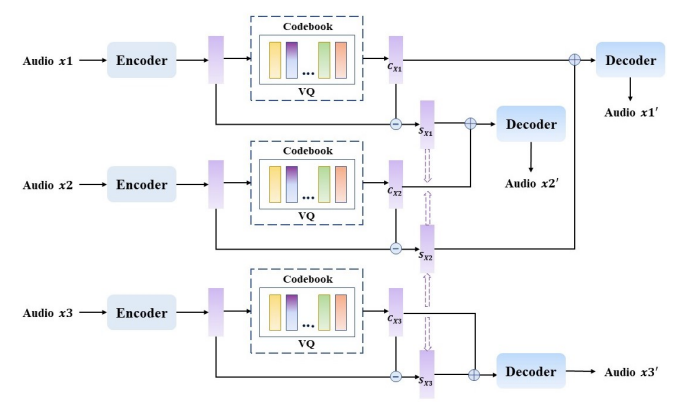
- AVQVC
- AVQVC는 VQVC의 architecture를 따르는 대신 AutoVC의 training method를 활용함
- 먼저 AVQVC에는 3개의 sentence $x_{1}, x_{2},x_{3}$가 전달됨
- $x_{1}, x_{2}$는 동일한 speaker의 서로 다른 text content, $x_{3}$는 다른 speaker의 sentence
- 이때 VQ model이 content, speaker embedding을 올바르게 disentangle 할 수 있다고 하면, $x_{1}, x_{2}$가 전달되었을 때 얻어지는 speaker embedding은 동일해야 함
- 반대로 $x_{1}, x_{3}$이나 $x_{2}, x_{3}$이 전달되면 얻어지는 speaker embedding이 서로 달라야 함
- 그러면, training phase에서 $x_{1},x_{2},x_{3}$이 전달되면 $\mathbf{C}_{x_{i}}, \mathbf{S}_{x_{i}}$를 얻을 수 있음 ($i=1,2,3$)
- 이때 $\mathbf{S}_{x_{1}}, \mathbf{S}_{x_{2}}$를 exchange하여 reconstruction task를 수행한다고 하자
- $\mathbf{S}_{x_{1}}, \mathbf{S}_{x_{2}}$는 동일해야 하므로 reconstruction speech $x'_{1},x'_{2}$는 $x_{1},x_{2}$에 가까워야 함 - 따라서 VQ model을 constrain 하기 위해 self-reconstruction loss와 latent-code loss를 적용할 수 있음:
(Eq. 7) $\mathcal{L}_{recon}=||x'_{1}-x_{1}||_{1}^{1}+ ||x'_{2}-x_{2}||_{1}^{1}+|| x'_{3}-x_{3}||^{1}_{1}$
(Eq. 8) $\mathcal{L}_{latent}=|| \text{enc}(x_{1})-\mathbf{C}_{x_{1}}||^{2}_{2}+|| \text{enc}(x_{2})-\mathbf{C}_{x_{2}}||^{2}_{2}+|| \text{enc}(x_{3})-\mathbf{C}_{x_{3}}||^{2}_{2}$
- $x'_{1}$은 $\mathbf{C}_{x_{1}}, \mathbf{S}_{x_{2}}$로 얻어지고, $x'_{2}$는 $\mathbf{C}_{x_{2}},\mathbf{S}_{x_{1}}$로 얻어짐 - $x'_{3}$은 $\mathbf{C}_{x_{3}}, \mathbf{S}_{x_{3}}$으로 얻어짐:
(Eq. 9) $x'_{3}=\text{Decoder}(\mathbf{C}_{x_{3}}+\mathbf{S}_{x_{3}})$
- 이때 $\mathbf{S}_{x_{1}}, \mathbf{S}_{x_{2}}$를 exchange하여 reconstruction task를 수행한다고 하자
- 추가적으로 논문은 speaker-loss function과 diff-speaker-loss function을 도입해 discrete data가 content embedding과 유사해지도록 함
- 이를 통해 continuous data와 discrete data 간의 mean difference가 speaker embedding에 가까워지도록 함
- 즉, $\mathbf{S}_{X_{1}},\mathbf{S}_{X_{2}}$는 speaker가 동일하므로 speaker embedding이 최대한 가까워야하고, $\mathbf{S}_{X_{1}}, \mathbf{S}_{X_{3}}$와 $\mathbf{S}_{X_{2}}, \mathbf{S}_{X_{3}}$은 서로 다른 speaker이므로 speaker embedding이 달라야 함:
(Eq. 10) $\mathcal{L}_{speaker}=|| \mathbf{S}_{x_{2}}-\mathbf{S}_{x_{1}}||_{1}^{1}$
(Eq. 11) $\mathcal{L}_{diff}=-\left( || \mathbf{S}_{x_{2}}-\mathbf{S}_{x_{3}}||_{1}^{1}+|| \mathbf{S}_{x_{1}}-\mathbf{S}_{x_{3}}||_{1}^{1}\right)$ - 결과적으로 얻어지는 full objective는:
(Eq. 12) $\mathcal{L}=\mathcal{L}_{recon}+\alpha \mathcal{L}_{latent}+\beta\mathcal{L}_{speaker}+\lambda\mathcal{L}_{diff}$
- 이를 통해 continuous data와 discrete data 간의 mean difference가 speaker embedding에 가까워지도록 함
- 추론 시에는 source/target speaker의 utterance를 select 해 각각의 content/speaker embedding을 얻은 다음, decoder에 전달하여 conversion을 수행함
- 먼저 AVQVC에는 3개의 sentence $x_{1}, x_{2},x_{3}$가 전달됨
3. Experiments
- Settings
- Dataset : VCTK
- Comparisons : VQVC, VQVC+, AutoVC, StarGANv2-VC
- Results
- 전체적으로 AVQVC가 가장 우수한 성능을 보임

- One-Shot VC 측면에서도 AVQVC의 성능이 가장 뛰어남

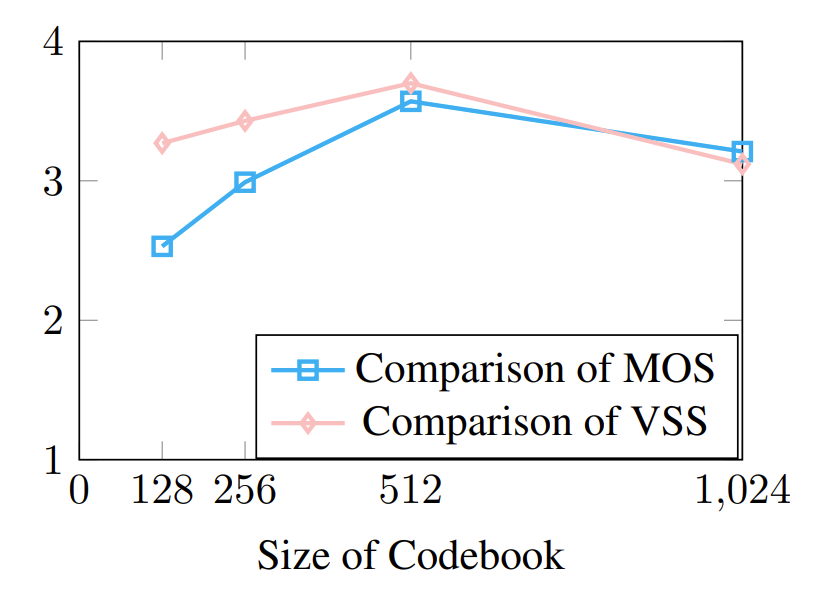
- Codebook size가 커질수록 성능이 향상되지만 너무 큰 size를 사용하는 경우 성능이 저하될 수 있음
- 논문에서는 512 codebook size를 채택
반응형
'Paper > Conversion' 카테고리의 다른 글
댓글