

 [Paper 리뷰] StreamSpeech: Low-Latency Neural Architecture For High-Quality On-Device Speech Synthesis
[Paper 리뷰] StreamSpeech: Low-Latency Neural Architecture For High-Quality On-Device Speech Synthesis
StreamSpeech: Low-Latency Neural Architecture For High-Quality On-Device Speech Synthesis Text-to-Speech (TTS) 모델의 추론 latency와 real-time factor (RTF)는 GPU와 같은 특수 hardware가 없는 상황에 배포하기에는 여전히 높음 StreamSpeech Single CPU를 활용한 resource 제약 환경에서 고품질, 실시간 합성을 가능하게 하는 TTS architecture Streaming과 low-latency generation을 가능하게하는 경량 convolutional acoustic decoder의 도입 논문 (ICASSP 2023) : Paper Link 1. Introduc..
 [Paper 리뷰] APNet: An All-Frame-Level Neural Vocoder Incorporating Direct Prediction of Amplitude and Phase Spectra
[Paper 리뷰] APNet: An All-Frame-Level Neural Vocoder Incorporating Direct Prediction of Amplitude and Phase Spectra
APNet: An All-Frame-Level Neural Vocoder Incorporating Direct Prediction of Amplitude and Phase Spectra Amplitude와 Phase spectra를 직접 예측하여 acoustic feature로부터 음성 waveform을 재구성하는 neural vocoder APNet Amplitude Spectrum Predictor (ASP)와 Phase Spectrum Predictor (PSP)로 구성 ASP는 acoustic feature로부터 frame-level amplitude spectra를 예측 PSP는 acoustic feature로부터 frame-level phase spectra를 예측 논문 (TASLP 2023)..
 [Paper 리뷰] Multi-Band MelGAN: Faster Waveform Generation for High-Quality Text-to-Speech
[Paper 리뷰] Multi-Band MelGAN: Faster Waveform Generation for High-Quality Text-to-Speech
Multi-Band MelGAN: Faster Waveform Generation for High-Quality Text-to-Speech 고품질 음성 합성과 빠른 생성을 목표로 기존 MelGAN을 개선 Multi-Band MelGAN MelGAN을 multi-band로 확장하고 generator의 receptive field를 확장 Feature matching loss를 multi-resolution STFT loss로 대체 논문 (SLT 2021) : Paper Link 1. Introduction WaveNet, WaveRNN, SampleRNN과 같은 기존의 고품질 neural vocoder는 autoregressive (AR) 모델임 AR 모델은 long-term dependecny를 모델링하..
 [Paper 리뷰] Source-Filter HiFi-GAN: Fast and Pitch Controllable High-Fidelity Neural Vocoder
[Paper 리뷰] Source-Filter HiFi-GAN: Fast and Pitch Controllable High-Fidelity Neural Vocoder
Source-Filter HiFi-GAN: Fast and Pitch Controllable High-Fidelity Neural Vocoder Unified Source-Filter GAN (USFGAN)은 source filter 이론을 도입하여 높은 음성 품질과 pitch 제어를 가능하게 함 USFGAN은 높은 temporal resolution으로 인해 높은 계산 비용을 가짐 Source-Filter HiFi-GAN HiFi-GAN에 source filter 이론을 도입한, 빠르고 pitch 제어가 가능한 neural vocoder Source excitation information에 resonance filter를 계층적으로 conditioning 논문 (ICASSP 2023) : Paper ..
 [Paper 리뷰] HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
[Paper 리뷰] HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Generative Adversarial Network (GAN)을 활용한 음성 합성은 autoregressive에 비해 낮은 품질을 보임 하지만 GAN을 활용하면 sampling과 메모리 효율성을 향상할 수 있음 HiFi-GAN 다양한 period를 가지는 sinusoidal pattern을 모델링 Autoregressive 모델보다 더 빠르고 고품질의 음성을 합성 논문 (NeurIPS 2020) : Paper Link 1. Introduction 대부분의 음성 합성 모델은 two-stage 구조를 가짐 Text로 부터 mel-spectrog..
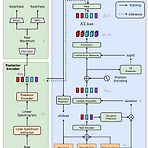 [Paper 리뷰] VISinger: Variational Inference with Adversarial Learning for End-to-End Singing Voice Synthesis
[Paper 리뷰] VISinger: Variational Inference with Adversarial Learning for End-to-End Singing Voice Synthesis
VISinger: Variational Inference with Adversarial Learning for End-to-End Singing Voice Synthesis 가사와 악보로부터 가창 음성을 직접 생성하는 End-to-End Singing Voice Synthesis (SVS) 모델 Normalizing flow 기반 VAE를 채택한 End-to-End Text-to-Speech (TTS) 모델인 VITS를 활용 VISinger Phoneme-level 평균, 분산 대신 Length regulator, Frame prior network를 사용하여 노래의 음향 변화를 모델링 F0 predictor를 통한 안정적인 가창 음성 합성 리듬감 향상을 위한 Duration predictor의 수정 논..